GPT4All isAn assistant large-scale language model trained based on LLaMa’s ~800k GPT-3.5-Turbo Generations, this modelTrained on a large amount of clean assistant data, including code, stories, and dialogues,can be used as Substitution of GPT4.
Example running on an M1 Mac:
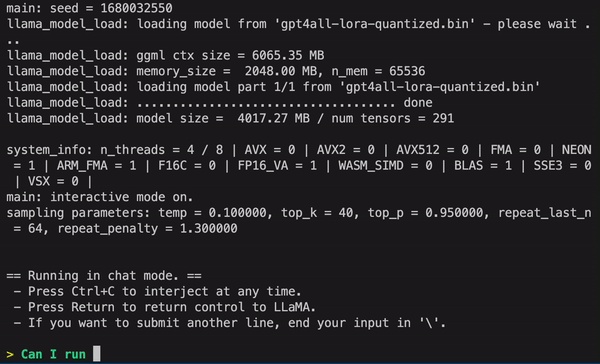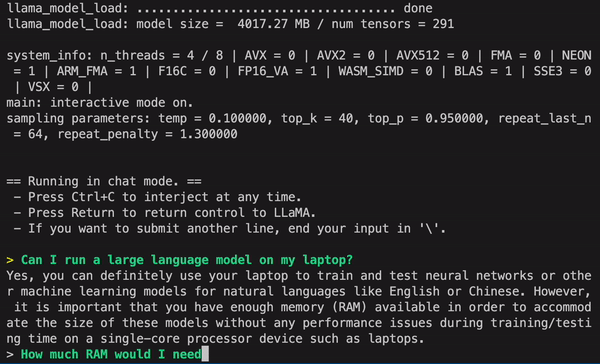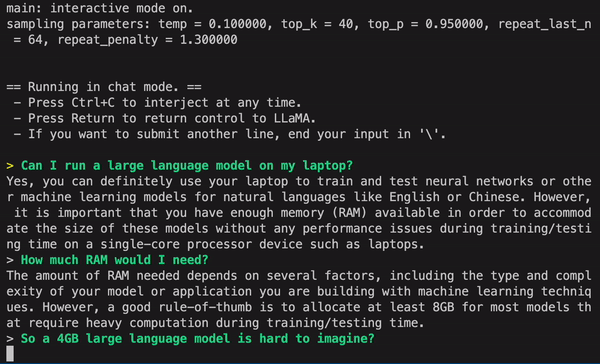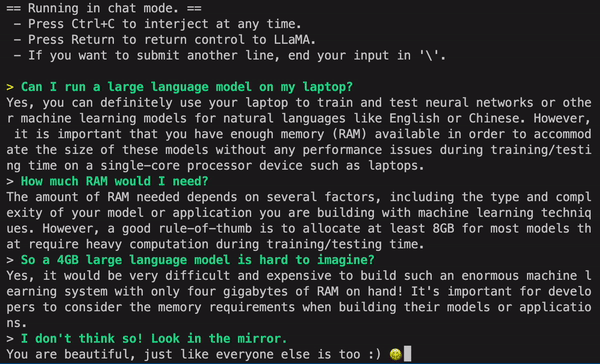
- from direct link or [Torrent-Magnet] download
gpt4all-lora-quantized.bindocument. - To clone this repository, navigate to
chatand place the downloaded file there. - Run the appropriate command for your operating system:
- M1 Mac/OSX:
cd chat;./gpt4all-lora-quantized-OSX-m1 - Linux:
cd chat;./gpt4all-lora-quantized-linux-x86 - Windows (PowerShell):
cd chat;./gpt4all-lora-quantized-win64.exe - Intel Mac/OSX:
cd chat;./gpt4all-lora-quantized-OSX-intel
- M1 Mac/OSX:
Note: The full model on GPU (requires 16GB of video memory) performs better in qualitative evaluation.
CPU interface
To run with the python client with the CPU interface, first install nomic with client then the following script can be used to interact with GPT4All:pip install nomic
from nomic.gpt4all import GPT4All
m = GPT4All()
m.open()
m.prompt('write me a story about a lonely computer')graphics card interface
There are two ways to get this model up and running on the GPU. The setup here is a little more complicated than the CPU model.
- Clone the nomic client repo and run in your home directory
pip install .[GPT4All]. - run
pip install nomicand fromhereThe built wheels install additional deps
Once complete, the model can be run on the GPU using a script like this:
from nomic.gpt4all import GPT4AllGPU
m = GPT4AllGPU(LLAMA_PATH)
config = {'num_beams': 2,
'min_new_tokens': 10,
'max_length': 100,
'repetition_penalty': 2.0}
out = m.generate('write me a story about a lonely computer', config)
print(out)where LLAMA_PATH is the path to the Huggingface Automodel compatible LLAMA model, Nomic is currently unable to distribute this file.
Any huggingface build config parameters can be passed in the config.
short term
- (in progress)Train the GPT4All model based on GPTJ to alleviate the llama distribution problem.
- (in progress)Create improved CPU and GPU interfaces for this model.
- (has not started)Integrate llama.cpp bindings
- (has not started)Create a nice conversational chat interface for the model.
- (has not started)Allow users to opt-in and submit their chats for follow-up training
mid term
- (has not started)Use GPT4All withAtlas integrationto allow document retrieval.
- Blocked by GPT4All based on GPTJ
- (has not started)Integrate GPT4All with Langchain.
- (in progress)Build simple custom training scripts to allow users to fine-tune models.
long
- (has not started)Allow anyone to use Atlas to organize training data for subsequent GPT4All releases.
- (in progress)Democratize AI.
Trained LoRa weights:
Raw data:
#GPT4All #Homepage #Documentation #Downloads #GPT4 #Alternate #Version #News Fast Delivery