In cloud services, caching is extremely important. The so-called cache is actually a high-speed data storage layer. When the cache exists, requesting the data again in the future will directly access the cache, improving the speed of data access. However, the data stored in the cache is usually short-lived, which requires frequent updates to the cache. And we operate the cache and database, which are divided into read operations and write operations.
The detailed process of the read operation is to request data. If there is data in the cache, it will be read and returned directly. If it does not exist, it will be read from the database. After success, the data will be placed in the cache.
Write operations are divided into the following four types:
Update the cache first, then update the database
Update the database first, then update the cache
Delete the cache first, then update the database
Update the database first, then delete the cache
For some data that does not require high consistency, such as the number of likes, you can update the cache first, and then synchronize it to the database at regular intervals. In other cases, we usually wait for the database operation to succeed before operating the cache.
The following mainly introduces the difference and improvement plan between updating the cache and deleting the cache after the database is successfully updated.
Update the database first, then delete the cache
Update the database first, and then delete the cache. This mode is also called cache aside, which is currently a popular method for dealing with the consistency of the cache database. Its advantages are:
The probability of data inconsistency is extremely low, and the implementation is simple
Since the cache is not updated but deleted, in the case of concurrent writes, there will be no data inconsistency
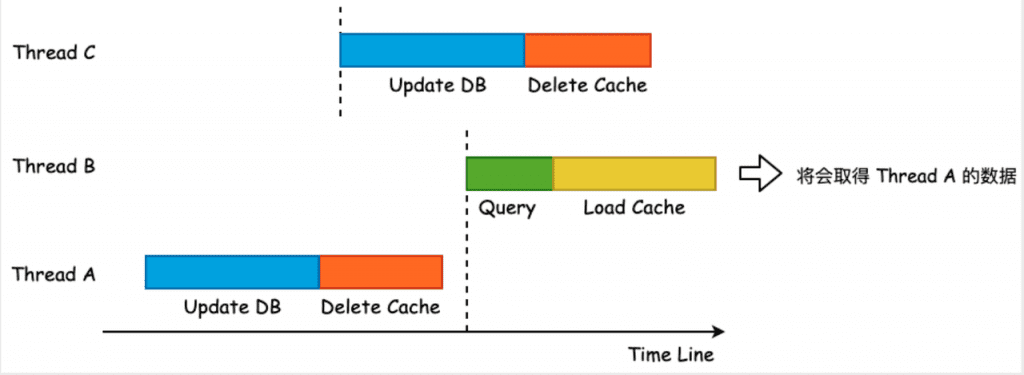
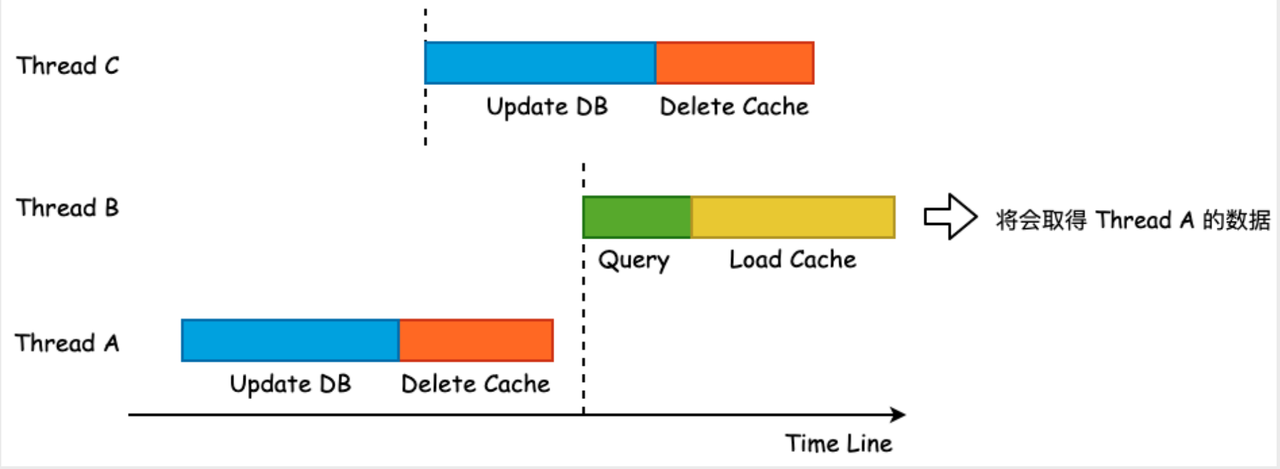
The data inconsistency occurs in the scenario of concurrent reading and writing. See the following figure for details:
The probability of this happening is relatively low, and there must be two or more writes and multiple reads in a certain time interval at the same time, so most businesses tolerate this small probability of inconsistency.
Although the probability of occurrence is low, there are still some options to reduce the impact even less.
Optimization
The first option is to use a shorter expiration time to reduce the impact. This approach has two disadvantages:
The second solution is to adopt a delayed double-delete strategy, for example: delete the cache after 1 minute. This approach also has two disadvantages:
The third solution is the double-update strategy, which is similar to the delayed double-delete strategy. The difference is that this scheme does not delete the cache but updates the cache, so read requests will not miss. But another disadvantage still exists.
Update the database first, then update the cache
Compared with the operation of first updating the database and then deleting the cache, the operation of first updating the database and then updating the cache can avoid the problem of user requests directly hitting the database, which will lead to cache penetration.
This solution is to update the cache. We need to pay attention to the data inconsistency caused by concurrent read and write and concurrent write and write scenarios.
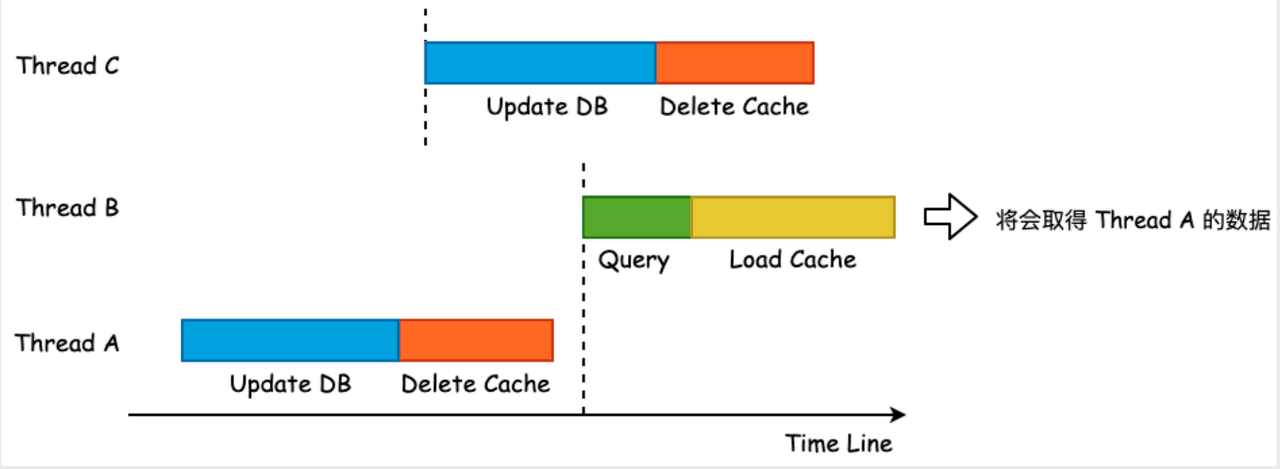
Let’s take a look at the concurrent reading and writing. The steps are shown in the figure below:

It can be seen that since steps 4 and 5 are both cached, if step 4 occurs before step 5, the old value will overwrite the new value, that is, the cache will be inconsistent. In this case, you only need to modify step 5 to solve it.
Optimization
It can be optimized by not using set cache in the fifth step, but using add cache and using the setnx command in redis. The schematic diagram of the modified steps is as follows:

After solving the data inconsistency caused by concurrent read and write scenarios, let’s take a look at the data inconsistency caused by concurrent write and write situations.
The situation of inconsistency is shown in the figure below. Thread A finishes updating DB before Thread B, but Thread B finishes updating the cache first, which causes the cache to be overwritten by the old value of Thread A.
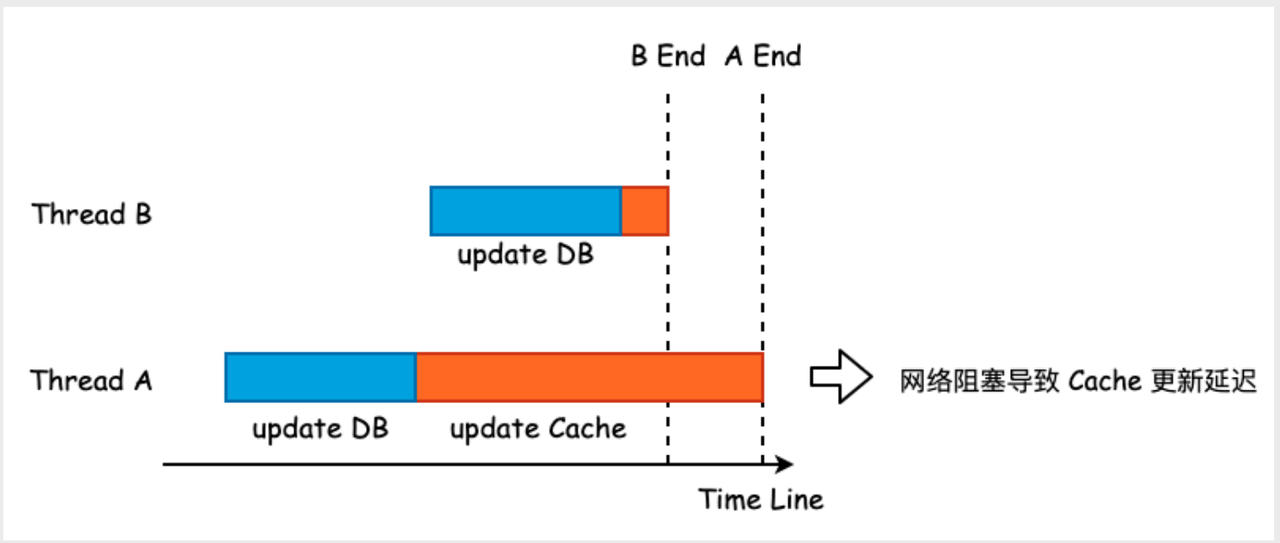
There are also ways to optimize this situation. Here are two mainstream methods:
Use distributed locks
use version number
Use distributed locks
To solve the problem of concurrent reading and writing, the first idea is to eliminate concurrent writing. Using distributed locks and queuing write operations for execution can theoretically solve the problem of concurrent writing, but there is currently no reliable implementation of distributed locks.
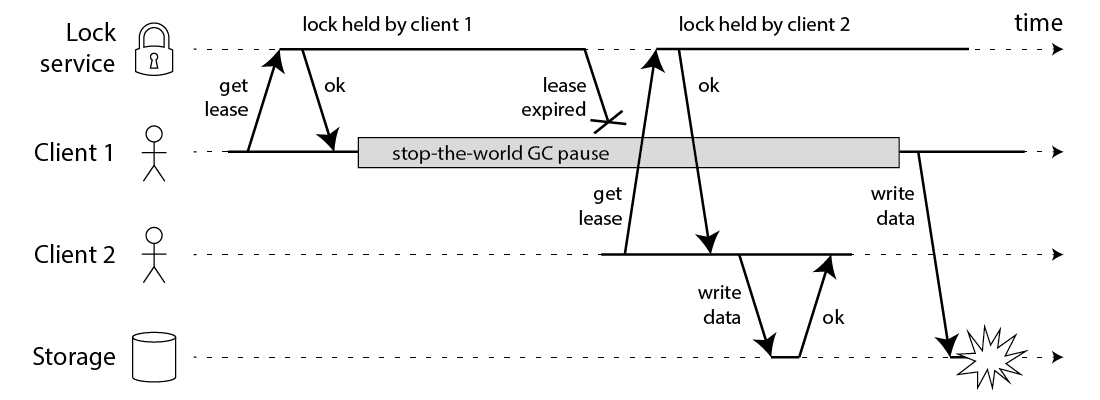
No matter the distributed lock is implemented based on Zookeeper, etcd or redis, in order to prevent the program from hanging and the lock cannot be released, we will set the lease/expiration time for the lock. Imagine a scenario: if the process freezes for a few minutes (although the probability is low) , causing the lock to fail, and other threads acquire the lock. At this time, the scene of concurrent reading and writing appears again, and data inconsistency may still be caused.
use version number
The data inconsistency caused by concurrent writing is because the lower version covers the higher version. Then we can find a way to prevent this from happening. A feasible solution is to introduce a version number. If the written data is lower than the current version number, the overwrite will be discarded.
shortcoming:
The cost of maintaining the version of the application layer is very high, and it is difficult to implement it on a large scale
The data model needs to be modified and the version added
Every time you need to modify it, let the version auto-increment
Whether it is updating the cache or deleting the cache, after optimization, the probability of data inconsistency will be minimized. But is there a way that is simple and does not cause data inconsistencies? Let’s introduce Rockscache.
Rockscache
Introduction
Rockscache is also a method to maintain cache consistency. The cache management strategy it adopts is: after updating the database, mark the cache as deleted. Mainly through the following two methods to achieve:
At runtime, as long as Fetch is called when reading data, and TagAsDeleted is called after updating the database, it can ensure that the cache is eventually consistent. This strategy has 4 characteristics:
There is no need to introduce a version, and it can be applied to almost all caching scenarios
Architecturally the same as “delete cache after updating DB”, no additional burden
High performance: the change is only to replace the original GET/SET/DELETE with Lua scripts
The performance of the strong consistency scheme is also very high, which is the same as that of the ordinary anti-cache breakdown scheme
In the Rockscache strategy, the data in the cache is a hash containing several fields:
value: the data itself
lockUtil: data lock expiration time, when a process queries the cache without data, then lock the cache for a short period of time, then query the DB, and then update the cache
owner: data locker uuid
prove
Because the Rockscache solution does not update the cache, it only needs to ensure the consistency of concurrent read and write data. Let’s take a look at how Rockscache solves the problem of data inconsistency. First, recall the reasons for the data inconsistency caused by the cache aside mode.
Combined with the scenario of data inconsistency in the cache aside mode, let’s talk about how Rockscache solves it.
The core problem we want to solve is to prevent old values from being written into the cache. Rockscache’s solution is this:
So far we have completed the cache update under the rockscache policy. However, like other cache update strategies, we all default to successful operation of the database after successful operation of the cache. But this is wrong. In the actual operation process, even if the operation of the database is successful, the cache operation may fail. Therefore, the following three methods can be used to ensure the success of the cache update:
local message table
monitor binlog
Two-phase message for dtm
In addition to cache updates, Rockscache has the following two functions:
These are very useful functions, and I recommend that you try them out in practice.
References
#Starting #actual #combat #lets #talk #cache #database #consistencyUPYUNunstructured #data #cloud #storage #cloud #processing #cloud #distribution #platform #News Fast Delivery