TensorBase is a modern, real-time open source data warehouse implemented in Rust.
characteristic
-
All in Rust. TensorBase claims that it has experienced dozens of terabytes of data injection in daily tests. It is currently a general-purpose data warehouse project that is deeply optimized for users, especially small and medium-sized enterprises, and has the highest degree of production completion in the Rust community.
-
out of the box. TensorBase already supports the complete data warehouse process from data insertion or import to query, and has a high degree of early completion. Users can download the binary files in the relevant Linux environment from the TensorBase Release page to try it out. (WSL2 for Windows 10 should also work now)
-
Compatible with ClickHouse protocol. ClickHouse is a data warehouse written in C++. TensorBase implemented a high-performance ClickHouse SQL dialect parser and TCP communication protocol stack from scratch using the Rust language. ClickHouse TCP client can seamlessly connect to TensorBase.
-
performance first. TensorBase expects to unleash the full potential of modern hardware through new software and system designs. TensorBase implements “F4” on the core link code for the first time: Copy-free, Lock-free, Async-free, Dyn-free (no dynamic object distribution).Initial Performance EvaluationDisplay: On the New York taxi dataset of 1.47 billion rows, the performance of TensorBase’s simple query is already ahead of ClickHouse.
-
simplify. The current big data system is very complicated to use. Even if you want to run the simplest system, you need to configure a lot of incomprehensible parameters or install a lot of third-party dependencies.
- For users, in addition to the out-of-the-box use that has been achieved now, TensorBase hopes that the system can run autonomously at runtime instead of relying on the operation and maintenance administrator.
- For developers, TensorBase hopes to lower the contribution threshold. The entire project architecture design is concise and efficient (see later for more information), with few dependencies outside the project, and the stand-alone time for complete recompilation (cargo clean to cargo build) is within 1 minute. (Complete build times for big data systems or C++ databases are often measured in hours.)
-
connected future. TensorBase transforms Apache Arrow and DataFusion at the core, and seamlessly supports Arrow format query, analysis and transmission. As an intermediate format for big data exchange that is increasingly widely used, the Arrow format has been supported by multiple databases and big data ecological platforms. TensorBase is compatible with Arrow on the engine, and in the future, it can support the data warehouse experience in both cloud-native and cloud-neutral scenarios, and provide storage-neutral data lake services.
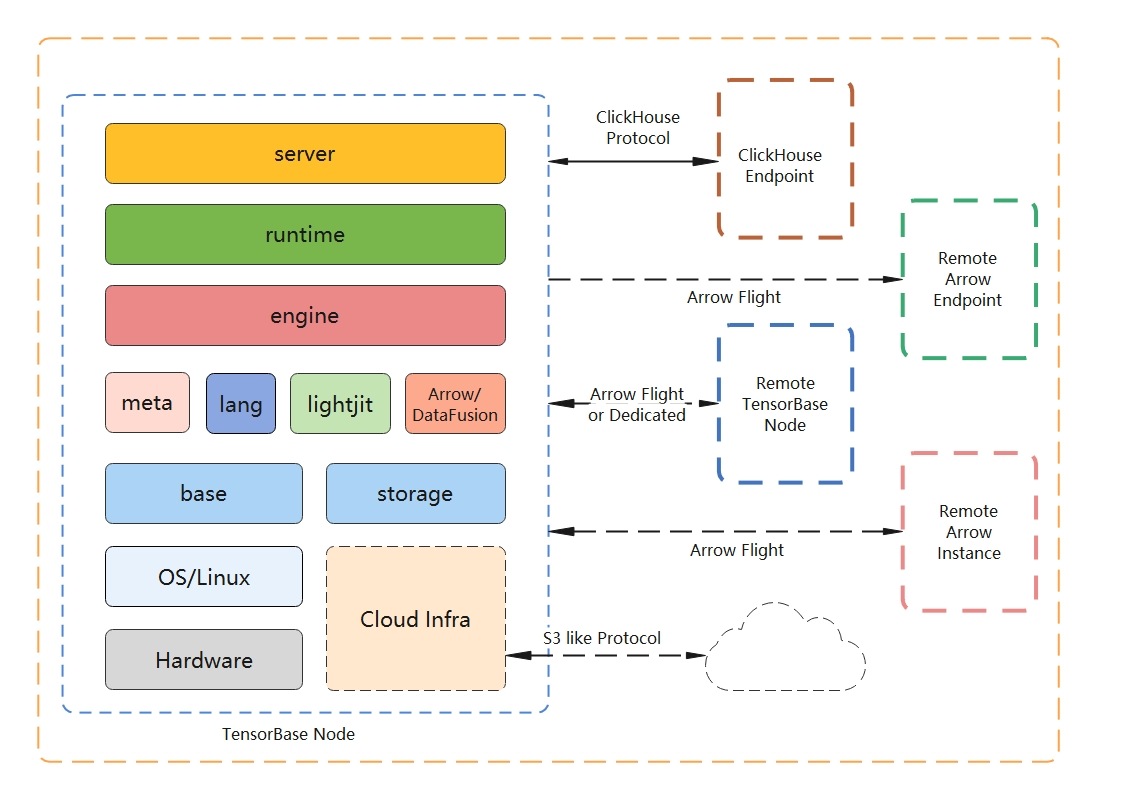
architecture
-
Base Server
TensorBase service interface layer. Provide data interface services externally, such as data writing and query entry. TensorBase creatively implements the world’s first non-C++ ClickHouse TCP protocol service stack, which can support ClickHouse client (clickhouse-client command line) and direct connection driven by native protocol language. Meanwhile, Base Server is the first async-neutral Rust high-performance server. Based on the modified Actix event loop, Base Server does not use async at all in the implementation of the service. While providing excellent debuggability, the evaluation performance also greatly exceeds the implementation based on tokio’s default async expression layer. In the future, non-tokio network io layer implementations can be introduced.
-
Base Meta/Runtime/Storage
TensorBase’s metadata layer, runtime layer, and storage layer. At the storage layer, TensorBase is not a classic columnar storage. The most important of these, we have given an anti-gravity design: No LSM. We no longer use the LSM Tree (Log Structured Merge Tree) data structure that is popular in current open source databases and big data platforms. Instead, we use a data structure that we call Partition Tree. The data is directly written to the partition file. While maintaining the performance of append only writing, it avoids the subsequent compact overhead of the LSM structure. Thanks to the support of the modern Linux kernel and the ingenious writing design, we do not use any locks (Lock-free) on the core read-write link of the user-space (User-space), and maximize the use of the high-concurrency network service layer The provided capability can provide ultra-high-speed data writing service.
-
base engine
The engine layer of TensorBase. TensorBase uses the modified Apache Arrow and DataFusion, and creatively adapts the underlying storage to the Arrow format, realizing Zero Copy data query. Of course, the current adaptive storage strategy is only a suboptimal solution in progress. TensorBase will continue to iterate the storage layer in the future and provide more optimizations that keep pace with the times. At the same time, TensorBase will further optimize and help the Arrow/DataFusion community optimize the performance of its query engine and grow together with the community.
-
other
TensorBase also has some basic components, such as:
- base, general tool library;
- lang, language layer (currently mainly implements a ClickHouse compatible parsing and presentation layer).
- lightjit, an expression-like JIT engine, can be extended to a high-performance, safe and controllable user-defined function UDF (User Defined Functions) layer in the future. TensorBase will further develop and open its own high-performance infrastructure in the future, and contribute some unique high-performance reusable infrastructure to the Rust community.
Note that the dotted line connection in the architecture diagram has not yet been realized. This is a panoramic architecture blueprint.
demo

#TensorBase #home #page #documentation #downloads #Rustbased #modern #data #warehouse #News Fast Delivery