A load balancer is a software or hardware device that acts to spread network traffic across a group of servers, preventing any one server from being overloaded. A load balancing algorithm is the logic that a load balancer uses to distribute network traffic among servers (an algorithm is a set of predefined rules), sometimes called a type of load balancing. There are many types of load balancing algorithms, ranging from simple round-robin load balancing algorithms to adaptive load balancing algorithms based on response status information.
The choice of load balancing algorithm will affect the effectiveness of the load distribution mechanism, thereby affecting performance and business continuity (that is, the SLA promised to the outside world). Choosing the correct load balancing algorithm can have a significant impact on application performance.
This article will introduce common load balancing algorithms, and introduce the implementation of various load balancing algorithms in combination with mainstream load balancing software or hardware devices
Round Robin (round robin load balancing algorithm)
Among all load balancing algorithms, the round-robin load balancing algorithm is the simplest and the most commonly used load balancing algorithm. Client requests are dispatched to the application server in a simple round-robin fashion. For example, suppose there are three application servers: the first client request is sent to the first application server, the second client request is sent to the second application server, and the third client request is sent to the third Application server, the fourth client request restarts from the first application server, and goes back and forth in sequence.
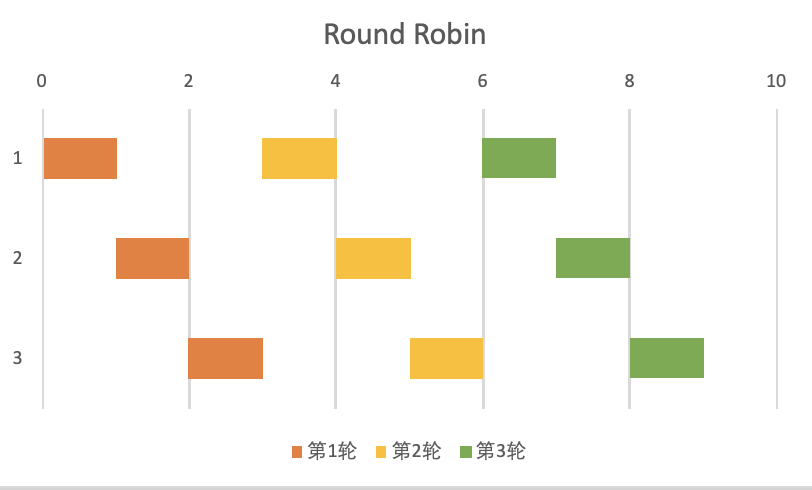
Round-robin load balancing is suitable for all client requests that require the same server load, and all server instances have the same server capacity and resources (such as network bandwidth and storage)
Weighted Round Robin (Weighted Round Robin Load Balancing Algorithm)
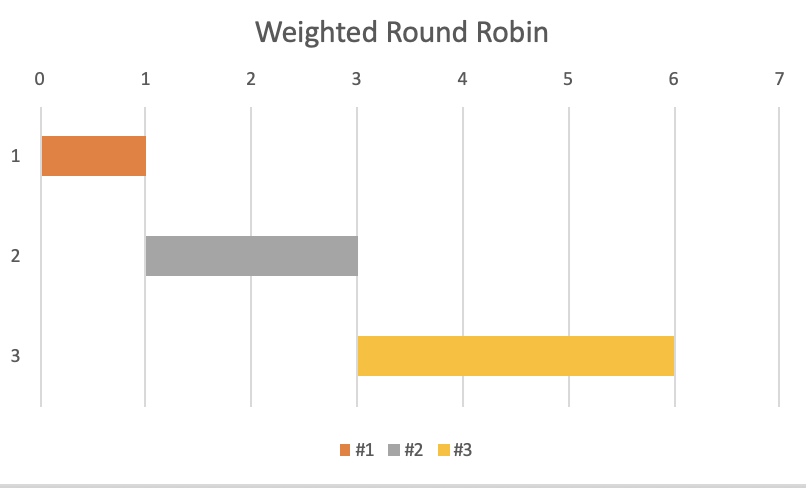
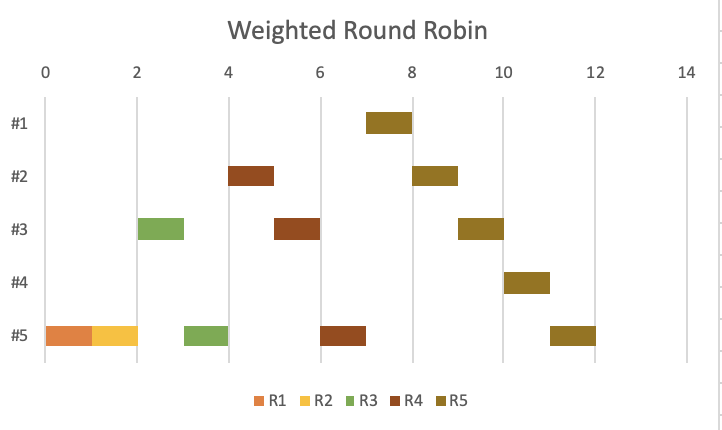
The weighted load balancing algorithm is similar to the round-robin algorithm, with the added ability to spread requests to different servers based on the relative capacity of each server. It is suitable for spreading incoming client requests over a set of servers with different functions or with different load capacities. The server cluster administrator assigns each application server a weight based on a criterion that represents each server’s relative processing power for requests.
For example, if server #1 has twice as many CPU cores as server #2 and server #3 when all other resources are infinite, then server #1 has a higher weight, while server # 2 and #3 have the same weight (both are lower than #1). If we have 4 consecutive client requests, then 2 requests are sent to #1, and the other 2 requests are sent to #2 and #3 respectively.
The weighted round-robin load balancing algorithm describes the load distribution over a period of time. Different weighted round-robin load balancing algorithms may produce different selection sequences. No assumption should be made about the server that handles the next load.
Least Connections (least connection load balancing algorithm)
The least connection load balancing algorithm is also called the least waiting request algorithm (Least Outstanding Request, LOR). Least connection load balancing is a dynamic load balancing algorithm in which client requests are distributed to the application server with the fewest active connections at the time the request is received. In the case of application servers with similar specifications, a server may be overloaded with too many connections (not being able to receive requests is also overloaded), this algorithm takes the active connection load into account. This technique is suitable for incoming requests with different connection times (multiple rooms) and a group of servers that are relatively similar in terms of processing power and available resources.
Weighted Least Connections (Weighted Least Connection Load Balancing Algorithm)
Weighted Least Connections is based on a Least Connections Load Balancing algorithm that takes into account different application server characteristics. As with the weighted round-robin load balancing algorithm, the server cluster administrator assigns each application server a weight based on a criterion that represents each server’s relative processing power for requests. The load balancer makes load balancing decisions based on active links and assigned server weights (for example, using the number of connections times the inverse of the weight to choose the server with the highest value).
Resource Based (resource-based load balancing algorithm)
Resource-based load balancing algorithms are also called adaptive load balancing algorithms. Resource-based load balancing algorithms make decisions based on status metrics provided by backend servers. This status indicator can be obtained by a custom application (such as an agent) running on the server, or from an open interface from an infrastructure provider. The load balancer periodically queries each server’s status metrics and then adjusts the server’s dynamic weights appropriately.
In this way, the load balancing algorithm actually performs a health check on each real server. This algorithm works for any situation where detailed health check information from each server is required to make load balancing decisions.
For example: this algorithm is suitable for any application that has variable workloads and requires detailed application performance and status to evaluate server health (such as CPU-intensive shortest path calculations, or other high-performance computing scenarios).
Fixed Weighting (fixed weight load balancing algorithm)
Fixed-weight load balancing algorithms allow server cluster administrators to assign a weight to each application server based on their criteria to represent each server’s relative traffic handling capacity. The application server with the highest weight will receive all traffic. If the application server with the highest weight fails, all traffic will be directed to the next application server with the highest weight. This approach is suitable for workloads where a single server can handle all expected incoming requests, and if the currently active server fails, one or more “hot standby” servers can be used directly to take on the load.
Weighted Response Timetimeload balancing algorithm)
The weighted response time load balancing algorithm uses the application’s response time to calculate server weights. The most responsive application server receives the next request. This method is suitable for scenarios where application response time is the most important issue.
It is especially important when the application provides an open service, because the open service will provide a service level agreement (Service Level Argument, SLA) for partners, and the main promise in the SLA is the availability of the service and the response time of the service (TP99 , TP999, etc.).
Source IP Hash (source address hash load balancing algorithm)
The source address hash load balancing algorithm uses the source IP and destination IP addresses of client requests to generate a unique hash key for assigning client requests to specific servers. If the transport layer session is interrupted, the key can be re-keyed, so client requests will be directed to the same unified server it was using before. This method works best when it is critical that the client always returns to the same server for each successive connection.
Database transactions that are frequently contacted by server-side R&D are suitable for this scenario
Consistent Hash (consistent hash load balancing algorithm)
The consistent hash load balancing algorithm is similar to source address hashing, except that the consistent hash load balancing algorithm can use any application parameters to form a unique hash key, and when the server cluster changes, it can process as little data as possible migrate.
This section will introduce the implementation of various common load balancing algorithms. Some load balancing algorithms have multiple implementations, and each implementation has its own applicable scenarios. These different implementations will also be described in this section. Introduce. At the same time, this section assumes that all requests are linear, and does not deal with the details of concurrency safety.
Round Robin (round robin load balancing algorithm)
Among all load balancing algorithms, the round-robin load balancing algorithm is the easiest to implement, requiring only one variable representing the current position and increasing it continuously.
public class RoundRobinLoadBalancer {
private final List instances;
private int position;
public RoundRobinLoadBalancer(List instances) {
this.instances = instances;
this.position = ThreadLocalRandom.current().nextInt(instances.size());
}
public ServiceInstance peek(HttpServletRequest request) {
int peeked = (position++) & Integer.MAX_VALUE;
return instances.get(peeked % instances.size());
}
}
There are two points to note here
When we initialize the location, we need to set it to a random value to avoid multiple load balancers requesting the same server at the same time, causing instantaneous pressure on the server
When the position is incremented, the sign bit needs to be ignored, because Java does not have unsigned integers, so when the value of the position exceeds the maximum value of the integer, it will become a negative value and cause an exception to be thrown. As for why the absolute value cannot be used, it is because the minimum value of the integer has no corresponding absolute value, and the obtained value is still negative (Spring Cloud #1074)
Weighted Round Robin (Weighted Round Robin Load Balancing Algorithm)
There are many mainstream implementations of weighted round-robin load balancing algorithms, and each has its own advantages. Although it is suitable for weighted load balancing to generate any selection sequence that conforms to the distribution of the total allocation ratio, whether it is possible to select as many nodes as possible to provide services in a short time window is still a key indicator to evaluate the quality of weighted load balancing.
array expansion
The implementation of array expansion is a strategy that applies space to time, and is suitable for small server clusters or dedicated load balancing devices. The advantage of it is that it is very fast and is exactly the same as the Round Robin implementation.Its shortcomings are also obvious, when the sum of weights is large, it will bring a large memory overhead
public class WeightedLoadBalancer {
private final List instances;
private int position;
public WeightedLoadBalancer(List instances) {
this.instances = expandByWeight(instances);
}
public ServiceInstance peek(HttpServletRequest request) {
int peeked = (position++) & Integer.MAX_VALUE;
return instances.get(peeked % instances.size());
}
private List expandByWeight(List instances) {
List newInstances = new ArrayList<>();
for (ServiceInstance instance : instances) {
int bound = instance.getWeight();
for (int w = 0; weight < bound; weight++) {
newInstances.add(instance);
}
}
Collections.shuffle(newInstances);
return newInstances;
}
}
There are three points to note here:
When an instance is expanded into an array by weight, the instance weight may be very large, but their greatest common divisor is not 1. In this case, the greatest common divisor can be used to reduce the size of the expanded array. Because of the many limitations of the greatest common divisor, such as any natural number N and N+1 are relatively prime, and any natural number N and 1 are relatively prime, it is easy to fail the optimization, so this example is not given, you can see if you are interested Spring Cloud related PR (Spring Cloud #1140)
After the instances are expanded into arrays by weight, the resulting arrays need to be shuffled to ensure that the traffic is as uniform as possible and avoid consecutive requests for the same instance (the shuffling algorithm implemented in Java is Fisher-Yates algorithm, and other languages can implement it by themselves)
Because the load balancer is expanded into an array by weight when building the load balancer, the weight of the instance cannot be changed after the load balancer is constructed, which is not applicable to scenarios where the weight is frequently and dynamically changed.
Upper bound convergence selection method
The upper bound convergence selection method calculates the maximum value of all weights in advance, and sets the initial upper bound as the maximum value of all weights. Next, we traverse all instances round by round and find the instances with weights greater than or equal to the upper bound. After the current round of traversal ends, all elements greater than or equal to the upper bound are selected, and then start to try nodes with lower weights, until the last upper bound is 0, and reset it to the maximum value. Currently openresty (someone analyzed this algorithm on issue #44)
public class WeightedLoadBalancer {
private final List instances;
private final int max;
private final int gcd;
private int bound;
private int position;
public WeightedLoadBalancer(List instances) {
this.instances = instances;
this.max = calculateMaxByWeight(instances);
this.gcd = calculateGcdByWeight(instances);
this.position = ThreadLocalRandom.current().nextInt(instances.size());
}
public ServiceInstance peek(HttpServletRequest request) {
if (bound == 0) {
bound = max;
}
while (instances.size() > 0) {
for (int peeked = position; peeked < instances.size(); peeked++) {
ServiceInstance instance = instances.get(peeked);
if (instance.getWeight() >= bound) {
position = peeked + 1;
return instance;
}
}
position = 0;
bound = bound - gcd;
}
return null;
}
private static int calculateMaxByWeight(List instances) {
int max = 0;
for (ServiceInstance instance : instances) {
if (instance.getWeight() > max) {
max = instance.getWeight();
}
}
return max;
}
private static int calculateGcdByWeight(List instances) {
int gcd = 0;
for (ServiceInstance instance : instances) {
gcd = gcd(gcd, instance.getWeight());
}
return gcd;
}
private static int gcd(int a, int b) {
if (b == 0) {
return a;
}
return gcd(b, a % b);
}
}
There are four points to note here:
In the case of short-frequency requests, high-weight instances will be accessed all the time, causing the load to appear uneven over a short time window. This can be solved by changing the direction and approximating from the lower bound to the upper bound.
The value of lowering the upper bound after each round can take the greatest common divisor of all weights, because if it drops by 1 each time, the middle rounds will repeatedly request the instances with the highest weights, resulting in unbalanced load.
Although the greatest common divisor can reduce the number of descents, if the weights are very different, and all elements are coprime (n is coprime to n+1, any natural number n is coprime to 1, which is very easy to appear in practice), then There will be a lot of idling as the upper bound descends. This can refer to the idea of breadth-first traversal and use a first-in, first-out queue to reduce idling.
The same problem encountered with the array expansion method is that the value of the greatest common divisor is calculated when the load balancer is constructed, so there will still be a large performance overhead for scenarios where the weights are frequently dynamically changed, but compared to the array expansion method It can avoid performance and memory fragmentation problems caused by frequent dynamic allocation of arrays
Weight rotation implementation
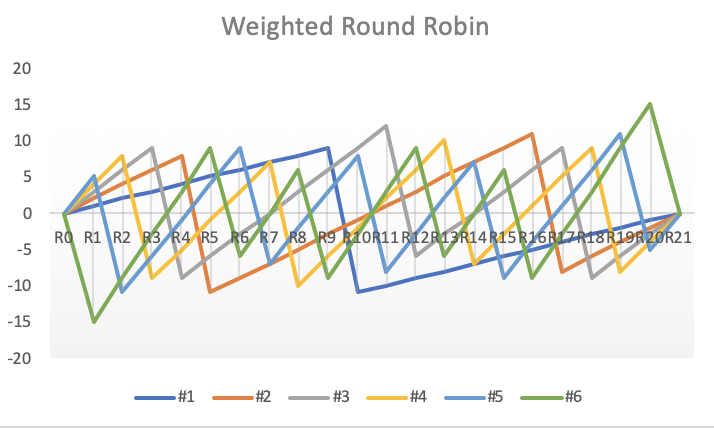
The weight rotation algorithm will store the values of two weights, one is the original weight that does not change, and the other is the current weight that changes with each selection. A circular invariant is maintained in the weight rotation implementation – the sum of the current weights of all nodes is 0. The effective weight of all instances during each round of traversal increases its original weight, and the node with the highest current weight is selected. The node with the highest weight is selected and its current weight is subtracted from the sum of all instance weights to avoid it being selected again. The weighted round-robin load balancing algorithm in NGINX uses this implementation (NGINX). The advantage of this algorithm is that it is smooth, low-weight nodes have shorter waiting times, and the minimum positive period for each round of weight rotation is small, which is the sum of the weights of all server instances. .
It is also called Smooth Weighted Load Balancing (SWRR) in NGINX.
public class WeightedLoadBalancer {
private final List instances;
public WeightedLoadBalancer(List instances) {
this.instances = instances;
}
public ServiceInstance peek(HttpServletRequest request) {
ServiceInstance best = null;
int total = 0;
for (ServiceInstance instance : instances) {
total += instance.getWeight();
instance.setCurrentWeight(instance.getCurrentWeight() + instance.getWeight());
if (best == null || instance.getCurrentWeight() > best.getCurrentWeight()) {
best = instance;
}
}
if (best != null) {
best.setCurrentWeight(best.getCurrentWeight() - total);
}
return best;
}
}
There are three points to note here:
Weight rotation is great for collections where instances change very frequently because it does not require building data structures in advance
The efficiency of weight rotation is related to the number of instances, and the time complexity is O(n). When the number of cluster servers is very large, the number of servers participating in each selection needs to be limited (Spring Cloud #1111)
The weight rotation implementation needs to modify the data structure of the server instance. This implementation cannot be used when the service instance is provided by other institutions.
EDF (Earliest Deadline First) implementation
The EDF algorithm was first used in CPU scheduling, and EDF is the best scheduling algorithm for preemptive uniprocessor scheduling. The EDF implementation is similar to the weight rotation implementation. It introduces an extra variable called deadline. It can be considered that the server instance with higher weight will complete the task faster. Then, assuming that the cost of all requests is the same, the time it takes is weighted Reciprocal, so it is natural to select the server instance that can be idle first to provide services, and assign tasks to it.
To implement the EDF algorithm, you only need to bind each downstream server instance to the deadline, and then maintain it in the priority queue with the deadline as the priority, and continuously take out the first element of the queue, adjust its deadline, and resubmit it to the priority queue. The well-known Service Mesh proxy envoy uses this method to implement weighted load balancing (envoy), and this method is also implemented in the ant open source network proxy mosn (mosn #1920)
public class WeightedLoadBalancer {
private final PriorityQueue entries;
public WeightedLoadBalancer(List instances) {
this.entries = instances.stream().map(EdfEntry::new).collect(Collectors.toCollection(PriorityQueue::new));
}
public ServiceInstance peek(HttpServletRequest request) {
EdfEntry entry = entries.poll();
if (entry == null) {
return null;
}
ServiceInstance instance = entry.instance;
entry.deadline = entry.deadline + 1.0 / instance.getWeight();
entries.add(entry);
return instance;
}
private static class EdfEntry implements Comparable {
final ServiceInstance instance;
double deadline;
EdfEntry(ServiceInstance instance) {
this.instance = instance;
this.deadline = 1.0 / instance.getWeight();
}
@Override
public int compareTo(EdfEntry o) {
return Double.compare(deadline, o.deadline);
}
}
}
The algorithm complexity of each selection of EDF is O(log(n)), which is slower than array expansion, but compared to the upper bound convergence, the selection requires O(n) time complexity in the worst case and weight rotation. In terms of degree, its performance is very good, and for very large clusters, its performance is not significantly degraded. Its space complexity is O(n) and will not cause a lot of memory overhead.
Least Connections (least connection load balancing algorithm)
traversal comparison method
The simplest implementation, iterates over all instances and finds the instance with the least number of current connections
public class LeastConnectionLoadBalancer {
private final List instances;
public LeastConnectionLoadBalancer(List instances) {
this.instances = instances;
}
public ServiceInstance peek(HttpServletRequest request) {
ServiceInstance best = null;
for (ServiceInstance instance : instances) {
if (best == null || instance.getConnections() < best.getConnections()) {
best = instance;
}
}
if (best != null) {
best.setConnections(best.getConnections() + 1);
}
return best;
}
}
heap maintenance
All dynamic ordered sets can be implemented by priority queues, which are the same as the EDF algorithm, take the element at the head of the queue, modify its priority, and put it back in the queue
public class LeastConnectionLoadBalancer {
private final PriorityQueue instances;
public LeastConnectionLoadBalancer(List instances) {
this.instances = instances.stream().collect(toCollection(
() -> new PriorityQueue<>(comparingInt(ServiceInstance::getConnections))));
}
public ServiceInstance peek(HttpServletRequest request) {
ServiceInstance best = instances.poll();
if (best == null) {
return null;
}
best.setConnections(best.getConnections() + 1);
return best;
}
}
Weighted Least Connections (Weighted Least Connection Load Balancing Algorithm)
The weighted least connection load balancing algorithm is implemented in the same way as the least connection load balancing algorithm, except that the weight-related parameters are added during the calculation.
traversal comparison method
public class LeastConnectionLoadBalancer {
private final List instances;
public LeastConnectionLoadBalancer(List instances) {
this.instances = instances;
}
public ServiceInstance peek(HttpServletRequest request) {
ServiceInstance best = null;
for (ServiceInstance instance : instances) {
if (best == null || instance.getConnections() * best.getWeight() < best.getConnections() * instance.getWeight()) {
best = instance;
}
}
if (best != null) {
best.setConnections(best.getConnections() + 1);
}
return best;
}
}
Tips, in the inequality a/b < c/d is equivalent to ad < bc, and can avoid the performance and accuracy problems caused by division
heap maintenance
public class LeastConnectionLoadBalancer {
private final PriorityQueue instances;
public LeastConnectionLoadBalancer(List instances) {
this.instances = instances.stream().collect(toCollection(
() -> new PriorityQueue<>(comparingDouble(ServiceInstance::getWeightedConnections))));
}
public ServiceInstance peek(HttpServletRequest request) {
ServiceInstance best = instances.poll();
if (best == null) {
return null;
}
best.setConnections(best.getConnections() + 1);
best.setWeightedConnections(1.0 * best.getConnections() / best.getWeight());
return best;
}
}
Weighted Response Timetimeload balancing algorithm)
The weighted response time load balancing algorithm uses a statistical method to obtain a predicted value through the historical response time, and uses this predicted value to select a relatively better server instance. There are many ways to get the predicted value, including the average within the time window, the TP99 within the time window, the exponential moving weighted average (EWMA) of all response times in history, and so on. Among them, Linkerd and APISIX use the EWMA algorithm (Linkerd and APISIX).
The operation of obtaining the predicted value through the historical response time is usually very CPU-intensive. In actual use, instead of traversing all elements, use K-neighboring elements or directly select two elements at random for comparison. This inspiration This method cannot guarantee the global optimum, but it can guarantee that it will not be the global worst.
Source IP Hash (source address hash load balancing algorithm)
The source address hash load balancing uses an arbitrary algorithm to map the request address to an integer, and maps the integer to the subscript of the instance list
public class IpHashLoadBalancer {
private final List instances;
public IpHashLoadBalancer(List instances) {
this.instances = instances;
}
public ServiceInstance peek(HttpServletRequest request) {
int h = hashCode(request);
return instances.get(h % instances.size());
}
private int hashCode(HttpServletRequest request) {
String xForwardedFor = request.getHeader("X-Forwarded-For");
if (xForwardedFor != null) {
return xForwardedFor.hashCode();
} else {
return request.getRemoteAddr().hashCode();
}
}
}
Here is a point to note:
The load balancer that provides services to the public network may pass through any multi-layer reverse proxy server. In order to obtain the real source address, it is necessary to obtain the X-Forwarded-For header first. If the header does not exist, then obtain the TCP source address of the connection
Service Registry and Service Discovery
When maintaining a large server cluster, server instances may be created or removed at any time. When a server is created or removed, the cluster administrator needs to go to each load balancing device to update the server instance list.
The service registry internally maintains a list of server instances corresponding to services. After the server instance is created and the service is successfully run, the server instance will go to the service registry to register itself, including the network address (IPv4/IPv6), service port number, service protocol (TCP/TLS/HTTP/HTTPS) and the service provided by itself. Service name, etc. Some service registries themselves also provide the ability to actively check health (such as Eureka and Consul). When the server instance exits normally, the deregistration logic will be executed in the service registry. At this time, the service registry will remove the server instance from the server instance list. Even if the server instance exits abnormally and the anti-registration logic cannot be executed, the service registry will remove the abnormal server instance from the server instance list through the active health check mechanism.
After having the service registry, the load balancing device does not need to manually maintain the server instance list, but pulls the corresponding server instance list from the service registry when a request comes, and performs load balancing in this server instance list. To improve service availability, the load balancing device caches these server instance lists locally (in memory or in a local file registry) to avoid service unavailability due to the inability of the load balancing device to connect with the service registry.
The strategy for caching and re-acquiring the server list has different implementations according to different business scenarios. In Spring Cloud Loadbalancer, the re-acquisition logic is triggered by cache expiration (Spring Cloud). When the service registry is unavailable, because there is no load balancing device in the device. The available server backup causes the service to be completely unavailable; in most load balancing devices, the cache acquisition and update logic is changed to a timer active refresh mechanism, so that when the service registry is unavailable, it can actively decide whether to mark old data as Expired. Although local caching can improve service availability, it should be noted that the load balancing device is still using the old service provider list. When the new service provider list cannot be obtained for a long time, the load balancing device should discard the old service provider list. List of parties, and expose the problem of service unavailability, and notify the cluster administrator to deal with it through the monitoring and alarming capabilities provided by the infrastructure.
Health Check
A health check is essentially a predetermined rule that sends the same request to all members of the server cluster behind the load balancer to determine whether each member server can accept client requests.
For some types of health checks, the health of each member server is determined by evaluating the response from the server and the time it takes to receive the server response. Typically, when the state of a member server becomes unhealthy, the load balancer should quickly remove it from the list of server instances and add it back to the list of server instances when the state of the member server returns to normal.
For network layer load balancers (also known as NLB or L4LB), by establishing a TCP connection, the status of the member server is determined based on whether the connection can be successfully established and how long it takes to establish the connection.
For the application layer load balancer (also called ALB or L7LB), by sending the request message for health check defined by the application layer protocol (not just the HTTP protocol), and according to the content of the response message and the entire request from establishment of connection to complete The time it took to receive all responses to determine the status of the member server.
There is no fixed pattern for application load balancers. For example, for an application that provides HTTP protocol services, you can provide the URL for health check, set the HTTP status code (or status code set) that passes the health check, and verify the field in the response packet that represents the server status (via JSONPath or XMLPath, etc.) is the expected value to confirm the status of the member server; for the RPC protocol, a special ping-pong service can be provided. The load balancer assembles the request message according to the RPC protocol and sends a ping request to the member server. The status of the member server is confirmed according to whether the content returned by the member server is a pong response. For the specific design, please refer to the ping-pong mechanism of websocket (RFC 6455).
Slow Start
The idea of slow start in load balancers comes from TCP’s congestion control theory, and its core is to avoid a large number of requests flooding into applications that have just been started, resulting in a large number of request blocking, timeouts or exceptions. As we all know, Java is a semi-compiled and semi-interpreted language. The interpreters of modern interpreted languages, including the Java language, are equipped with just-in-time compilers (Just In Time, JIT). The JIT compiler will track the execution point of each method. More efficient optimization of those hot paths (Hotspot), which is also the origin of the name Hotspot JVM. The JIT optimization of hotspot paths comes from all method calls since the application is started, that is to say, the system carrying capacity of the application is continuously strengthened as the program runs, and the JIT-optimized Java code can even get Approximate performance of O3 (highest level) optimizations in GCC. See Oracle’s Java Developer Guide for more details on the JIT compiler.
At the same time, modern applications inevitably use local caches. When the application is just started, the cache in memory is empty. As the application runs, it continuously accesses external systems to obtain data and writes data to the memory cache. , the interaction between the application and the external system will continue to decrease, and the system carrying capacity of the application will gradually peak.
The above are the most common factors for the continuous improvement of application performance after startup, and there are many factors other than the first time. Therefore, in order to avoid the phenomenon of a large number of requests flooding into the application that has just been started, the load balancer will continue to increase the weight of these server instances through the slow start method as the server runs, and finally reach the actual weight of the server, so as to achieve dynamic adjustment. The effect of traffic allocated to these server instances.
There are many server weight change algorithms, including linear growth over time, logarithmic growth over time, exponential growth over time, exponential growth over time, and logistic growth over time. At present, the Jingdong Service Framework (JSF) achieves linear growth with time; envoy achieves exponential growth with time, and introduces an asymptotic factor to adjust the rate of change (envoy slow start).

Load balancing technology is the core component of network proxy and gateway components. This article briefly introduces what is load balancing technology, common load balancing algorithms and the implementation of common load balancing algorithms, and gives the extension of load balancing technology for future Learn more about network proxy-related technologies to lay the foundation.
Due to my lack of talent and limited experience and ability, there will inevitably be negligence and omissions in the text, as well as inconsistencies. I welcome everyone to communicate with me and give suggestions.
author:Ji Zhuozhi
#Decryption #Load #Balancing #Technology #Load #Balancing #Algorithm #Cloud #Developers #Personal #Space #News Fast Delivery