Author: vivo Internet Database Team – Li Shihai
This article mainly introduces the general process and principle of lossless compression of images, as well as the problems and solutions found in the previous research of Lepton lossless compression.
1.1 Find the Difference Game
Please take out your stopwatch and find the difference in the picture below within 15 seconds.

Time is up, have you noticed the difference between the two pictures?
The growth of the wise
In the above game, you may not find any difference between the two pictures, but in fact one of them is the original picture in jpg format with a size of 3.7MB, and the other is a compressed picture in jpg format with a size of 485KB, just Different sizes. You may be a little angry and indignant to the point that this is a deception, but you are smart and quickly have a series of questions in your brain. These question marks make you uncover the veil of the game layer by layer, instead of regretting for being fooled, but from new knowledge get happy.
2.1 Socratic midwifery
- Why is the picture above smaller?
- Where does the lost information go?
- Why is the picture quality degraded and I can’t see it?
- Can I make it smaller?
- Can I restore it to its original size?
- Why should I compress my images?
Why is the picture above smaller? The picture changed from 3.7MB to 485KB because I used the picture viewing tool to save the original picture as a new picture. During the save process, there was a parameter for picture quality selection. I chose the lowest quality, and after saving, it was generated. A smaller picture. But the picture quality has dropped, why can’t I see it? This requires understanding the principle of image compression.
2.2 Explore the story behind the appearance
Take advantage of the weakness of the human eye.
There are two types of cells in the human retina, cones and rods. Cones are used to perceive color, and rods are used to perceive brightness. And relative to color, our perception of light and dark is more obvious.
Therefore, the color information can be compressed to reduce the size of the picture.
Therefore, we will perform color space transformation before image compression. JPEG images are usually transformed into YCbCr color space, Y represents brightness, Cb blue chromaticity, Cr red chromaticity, and it is easier for us to deal with the color part after transformation. Then we cut a picture into 8*8 pixel blocks, and then use the discrete cosine transform algorithm (DCT) to calculate the high-frequency and low-frequency regions.
Since the human eye is not sensitive to complex information in the high frequency region, this part can be compressed, a process called quantization. Finally, the new file is packaged. This process completes the image compression.
The basic process is as follows:

JPEG compression is lossy.
In the above process, after the color space conversion of the prediction module, the compression ratio is improved by discarding part of the color density information. The common option is 4:2:0. After this step, the information represented by 8 numbers was originally required, but now only 2 are needed, and 75% of the Cb Cr information is directly discarded. However, this step is irreversible, which results in Image compression is lossy. In addition, in the entropy coding module, run-length coding or Huffman coding will be used to further compress the picture information, and the compression of this part is lossless and reversible.
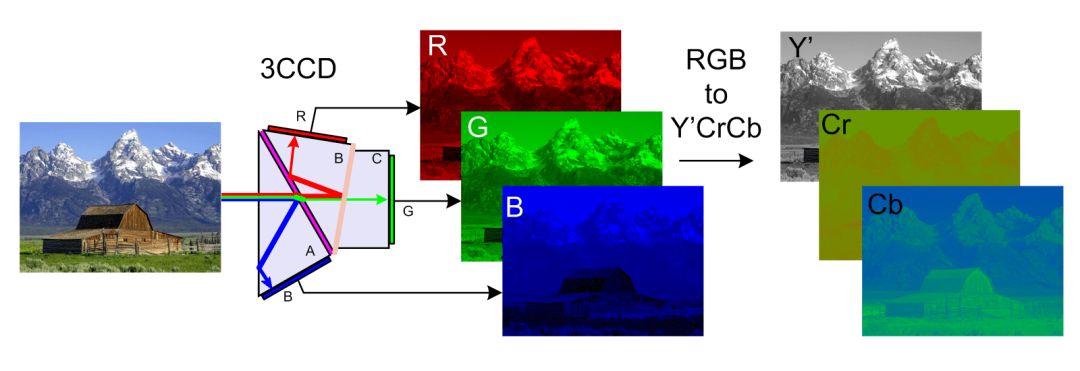
(YCbCr space conversion)
The principle of Huffman coding is as follows:
If the characters to be encoded have a total of 38 symbol data, count them, and the obtained symbols and corresponding frequencies are as follows:

First, sort all symbols according to their frequency, and the sorting is as follows:

Then, select the two nodes with the smallest frequency as the leaf nodes, the one with the smallest frequency as the left child node, the other one as the right child node, and the root node is the sum of the frequencies of the two leaf nodes.
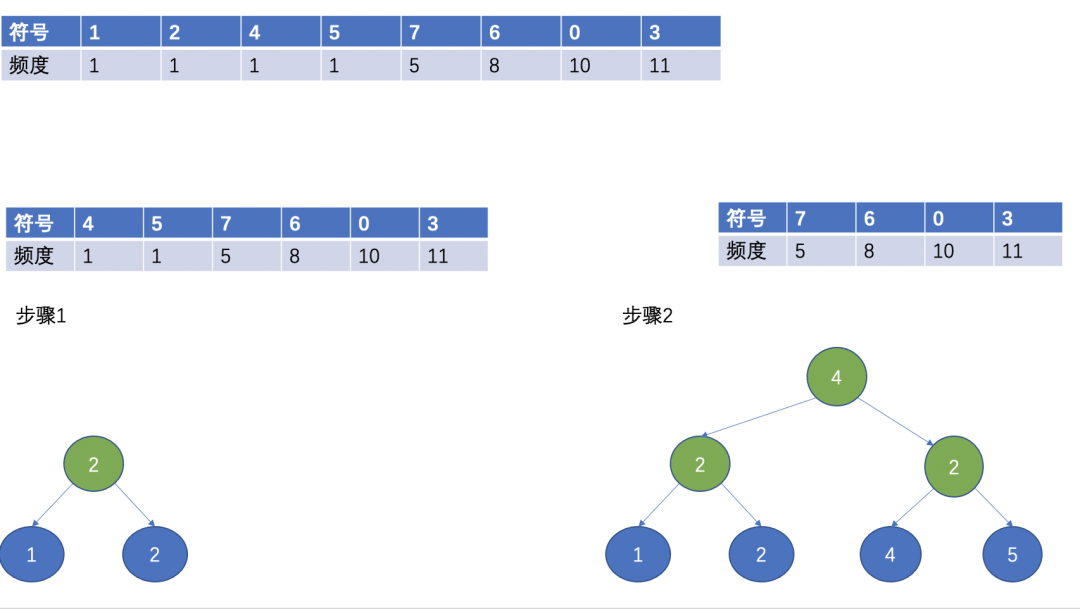
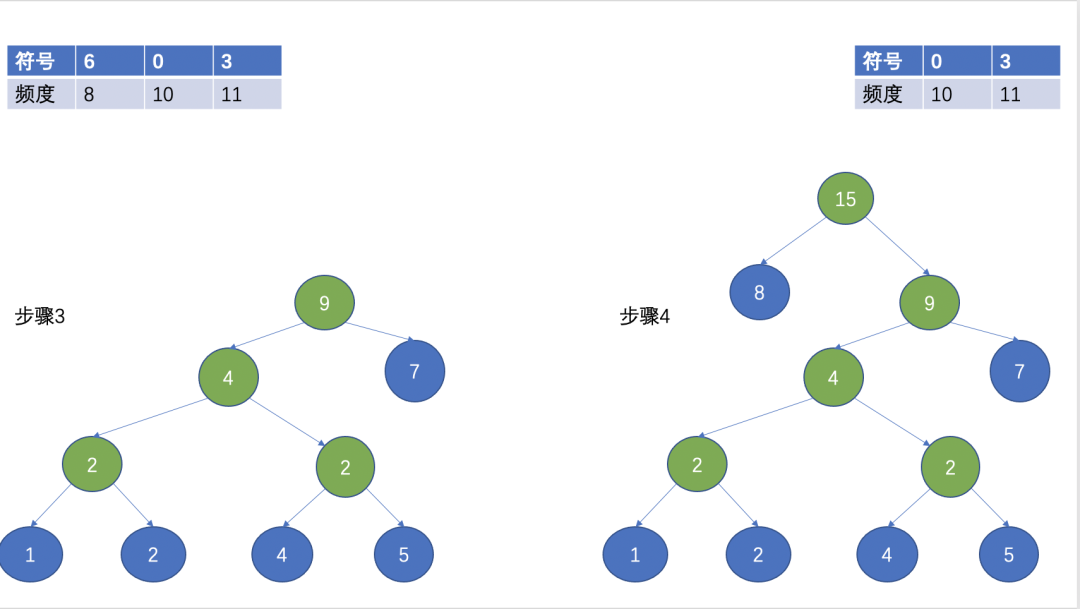
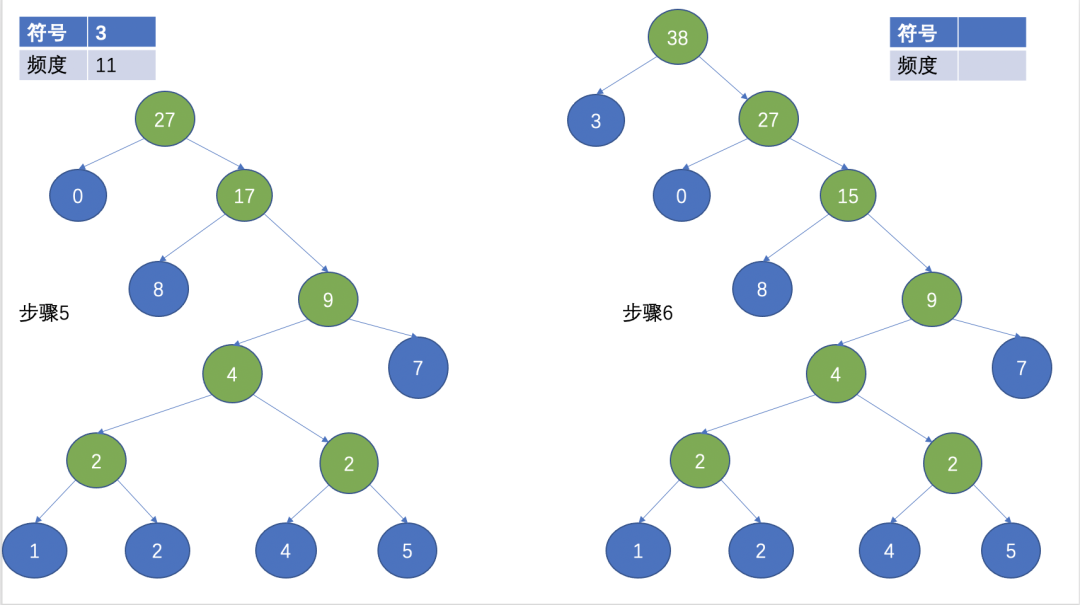
(Huffman tree)
After the above steps, a Huffman tree is formed. Huffman coding is often used in lossless compression. The basic idea is to use short codes to represent characters with high frequency, and use long codes to represent characters with low frequency. The average length and the expected value of the length of the encoded character string are reduced, so as to achieve the purpose of compression.
not perfect.
Although the above JPEG compression reduces the size of the image and the quality is so good that it is difficult for the human eye to distinguish the difference, but due to the lossy compression, the image quality cannot be restored to the original quality, and in fact the jpg image at this time still has Compressed space.
Lepton can further compress images losslessly on the basis of JPEG.
3.1 Why choose Lepton
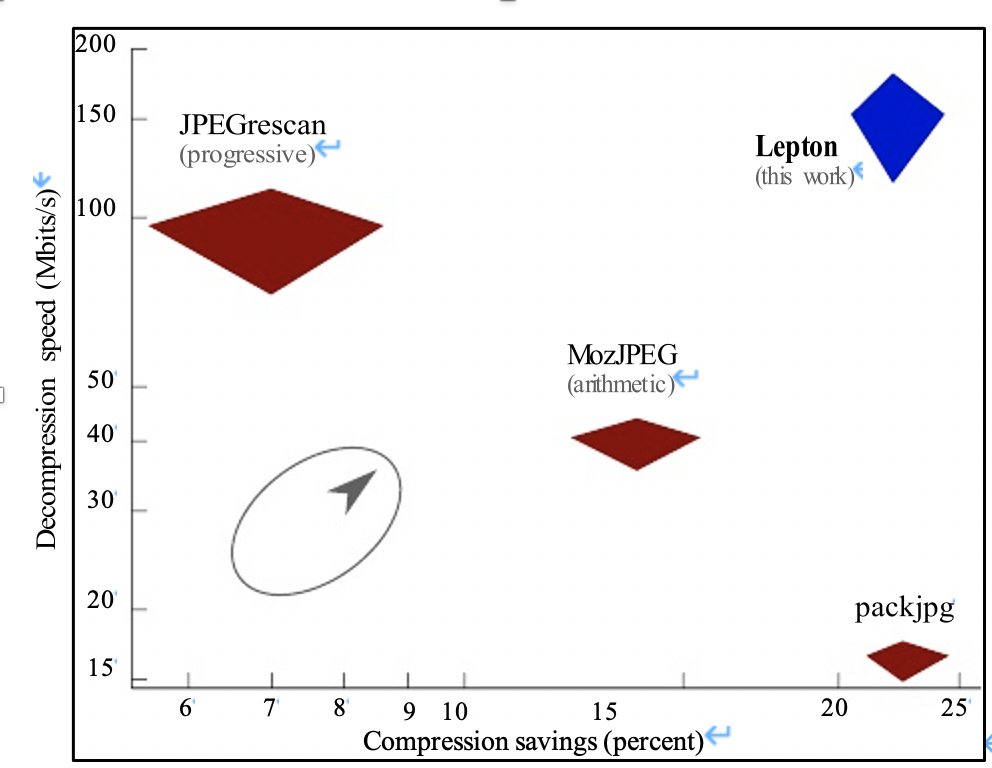
Similar compression tools to lepton are jpegcan, MozJPEG, PackJPG, PAQ8PX. But these tools all have more or less flaws that make them less suitable for industrial production than the lepton.
For example, PackJPG needs to rearrange all compressed pixel values in the file in a globally sorted order. This means that decompression is single-threaded and requires the entire image to fit in memory resulting in higher latency and lower throughput for processing the image.
The following figure is a comparison of several tools in the lepton paper:
3.2 What optimizations are made by Lepton.
First of all, Lepton divides the image into two parts, the header and the image data itself. The header uses DEFLATE for lossless compression, and the image itself uses arithmetic coding to replace Holman coding for lossless compression. Since JPEG uses Huffman encoding, which makes exploiting multithreading difficult, Lepton improved it with “Huffman switch words”.
Second, Lepton uses a complex adaptive probabilistic model developed by testing it on a large number of images in the wild. The goal of the model is to produce the most accurate predictions for the value of each coefficient, resulting in smaller files; engineering allows for multi-threaded concurrent processing, allowing for distributed processing in blocks across multiple servers, stream-by-line processing Effectively control the memory, while also ensuring the safety of data read and output.
It is Lepton’s optimization of the above-mentioned key issues that makes it currently available for use in production environments.
3.3 Lepton’s exploration in vivo storage
expected profit:
At present, one of the object storage clusters has about 100PB of data, of which image data accounts for about 70%, and 90% of the pictures are jpeg type pictures. If the average compression rate is 23%, then 100PB * 70% * 90 % * 23% = 14.5PB, which would result in a cost savings of approximately 14.5PB.
At the same time, because it is lossless compression, the user experience is well guaranteed. The design of the current lepton compression function is as follows:
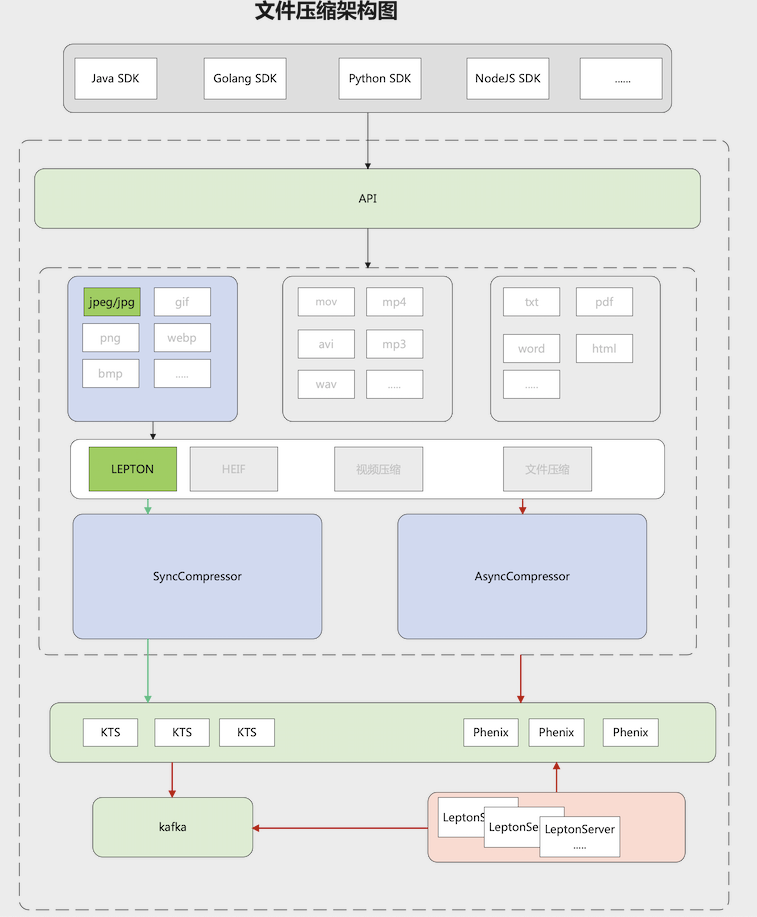
Current challenges:
- Lepton compression and decompression require high computing performance of the server and consume a lot of money.
- It is expected to make full use of idle server CPU resources to reduce costs and increase efficiency.
- In the face of tidal phenomena, it has the ability to dynamically expand and shrink.
The main problems currently facing:
At present, the size of most of the pictures is 4M-5M. After testing, when the compression delay of 4M-5M files is about 1s, the server needs at least 16 cores and 5QPS. At this point, the utilization of each core is above 95%. It can be seen that Lepton’s compression requires high computing performance. The current common solution is to use FPGA cards for hardware acceleration and horizontal expansion of a large number of computing nodes. The use of FPGAs increases hardware costs and reduces the cost-benefit of compression.
solution:
In order to solve the above problems and challenges, we try to use the hybrid deployment of physical servers and Kubernetes to solve the problem of computing resource usage and dynamic expansion. The architecture diagram is as follows: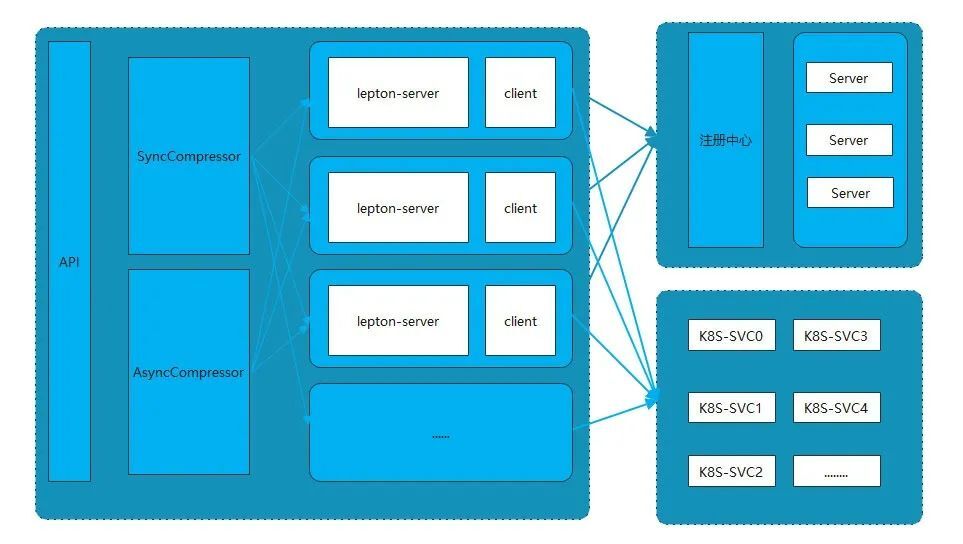
For the management and expansion of physical servers, flexible expansion is performed through service registration and discovery, and the cpu usage of processes is managed through this cgroup/taskset. At the same time, Kubernetes is used for container management, and the flexibility of containers is more suitable for this kind of computing service.
3.4 Performance Evaluation
Whether it is synchronous compression or asynchronous compression, usually more attention is paid to the latency of image reading. Reading a large number of pictures will bring great pressure to the server, and the pressure mainly comes from the decompression calculation of pictures. In order to improve the decompression efficiency and make full use of the company’s resources, we will distribute the lepton compression service to servers with idle CPUs in an independent service mode in the future. We can make full use of the peaks and valleys of resources to improve computing performance according to the degree of resource idleness and idle time. .
Pressure measurement data:
We selected image files of different sizes and performed compression and decompression tests in a stand-alone environment. The test results are as follows:
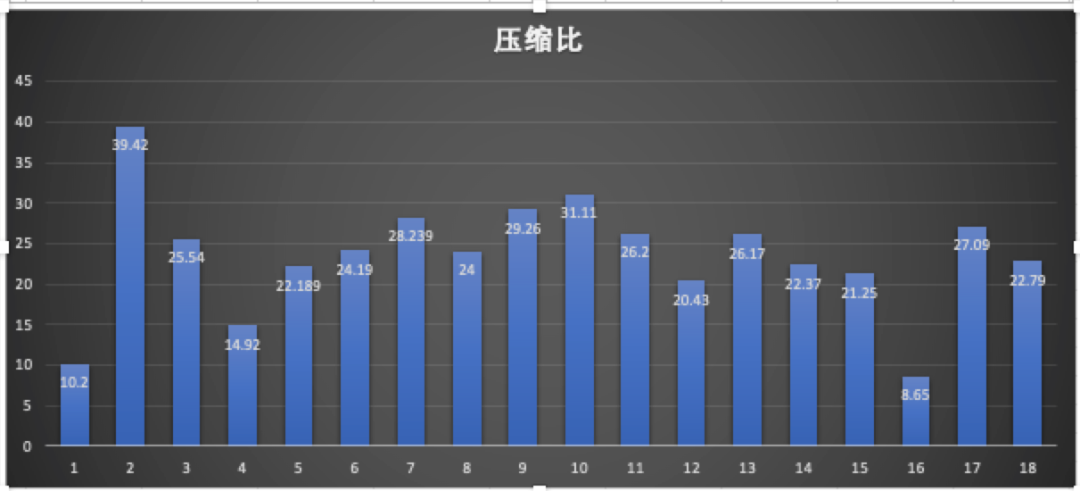
The compression ratio remains on average around 22%.
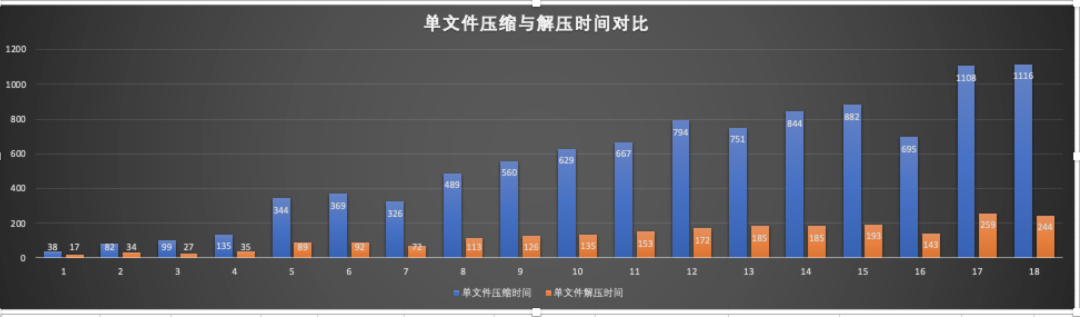
The figure above is the ratio of compression and decompression time for files of different sizes, orange is the decompression time, and blue is the compression time.
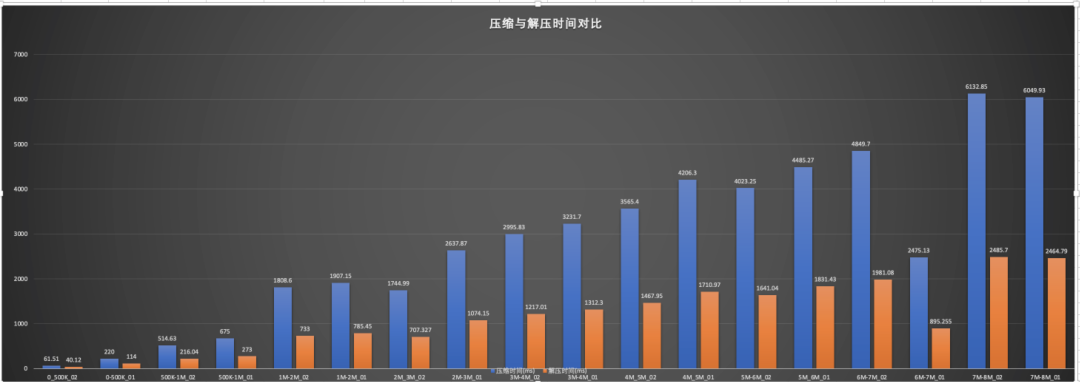
The above picture is a picture of different sizes, in 32 threads concurrently, each thread processes the test data of 100 files.
4.1 Distinguishing lossy and lossless compression by file format

4.2 Common Lossless Compression Algorithms

Lepton’s lossless compression can provide a relatively high compression ratio without affecting the user’s image quality and user experience, and will obtain relatively obvious benefits in scenarios with large data volumes.
insufficiencyIt is a picture that requires high computing performance and only supports jpeg type. There are also relatively mature solutions in the industry for performance requirements, such as the FPGA and elastic computing solutions mentioned above. The key is to choose a reasonable solution according to the needs of the enterprise.
Quote:
- “The Design, Implementation, and Deployment of a System to Transparently Compress Hundreds of Petabytes of Image Files For a File-Storage Service”
- “Research on JPEG Image Cloud Storage Based on Deep Learning”
- “Research on VLSI Structure Design of Key Modules of JPEG-Lepton Compression Technology”
#Lepton #Lossless #Compression #Principle #Performance #Analysis #vivo #Internet #Technology #News Fast Delivery