LaWGPT is a series of open source large language models based on Chinese legal knowledge.
This series of models is based on the general Chinese base model (such as Chinese-LLaMA, ChatGLM, etc.)Large-scale Chinese legal corpus pre-training, which enhances the basic semantic understanding ability of large models in the legal field. on the basis of,Construct a dialogue question-and-answer data set in the legal field and a Chinese judicial examination data set for instruction fine-tuningwhich improves the model’s ability to understand and enforce legal content.
For details, please refer toTechnical Reports.
project structure
LaWGPT
├── assets # 项目静态资源
├── data # 语料及精调数据
├── tools # 数据清洗等工具
├── README.md
├── requirements.txt
└── src # 源码
├── finetune.py
├── generate.py
├── models # 基座模型及 Lora 权重
│ ├── base_models
│ └── lora_weights
├── outputs
├── scripts # 脚本文件
│ ├── finetune.sh # 指令微调
│ └── generate.sh # 服务创建
├── templates
└── utilsdata construction
This project is based on the data sets of legal documents and judicial examination data released by the Chinese Judgment Documents Network. For details, please refer toSummary of legal data in Chinese
- Primary data generation: According toStanford_alpacaandself-instructway to generate dialogue question answering data
- Knowledge-guided data generation: Generate data based on Chinese legal structured knowledge through the Knowledge-based Self-Instruct method.
- Introduce ChatGPT cleaning data to assist in the construction of high-quality data sets.
model training
The training process of LawGPT series models is divided into two stages:
- The first stage: expanding the vocabulary in the legal field, pre-training Chinese-LLaMA on large-scale legal documents and code data
- The second stage: Construct a dialogue question-and-answer dataset in the legal field, and fine-tune instructions based on the pre-trained model
Secondary training process
- refer to
src/data/example_instruction_train.jsonConstruct a secondary training data set - run
src/scripts/train_lora.sh
Instruction fine-tuning steps
- refer to
src/data/example_instruction_tune.jsonConstruction instruction fine-tuning dataset - run
src/scripts/finetune.sh
computing resources
8 Tesla V100-SXM2-32GB
model evaluation
output example
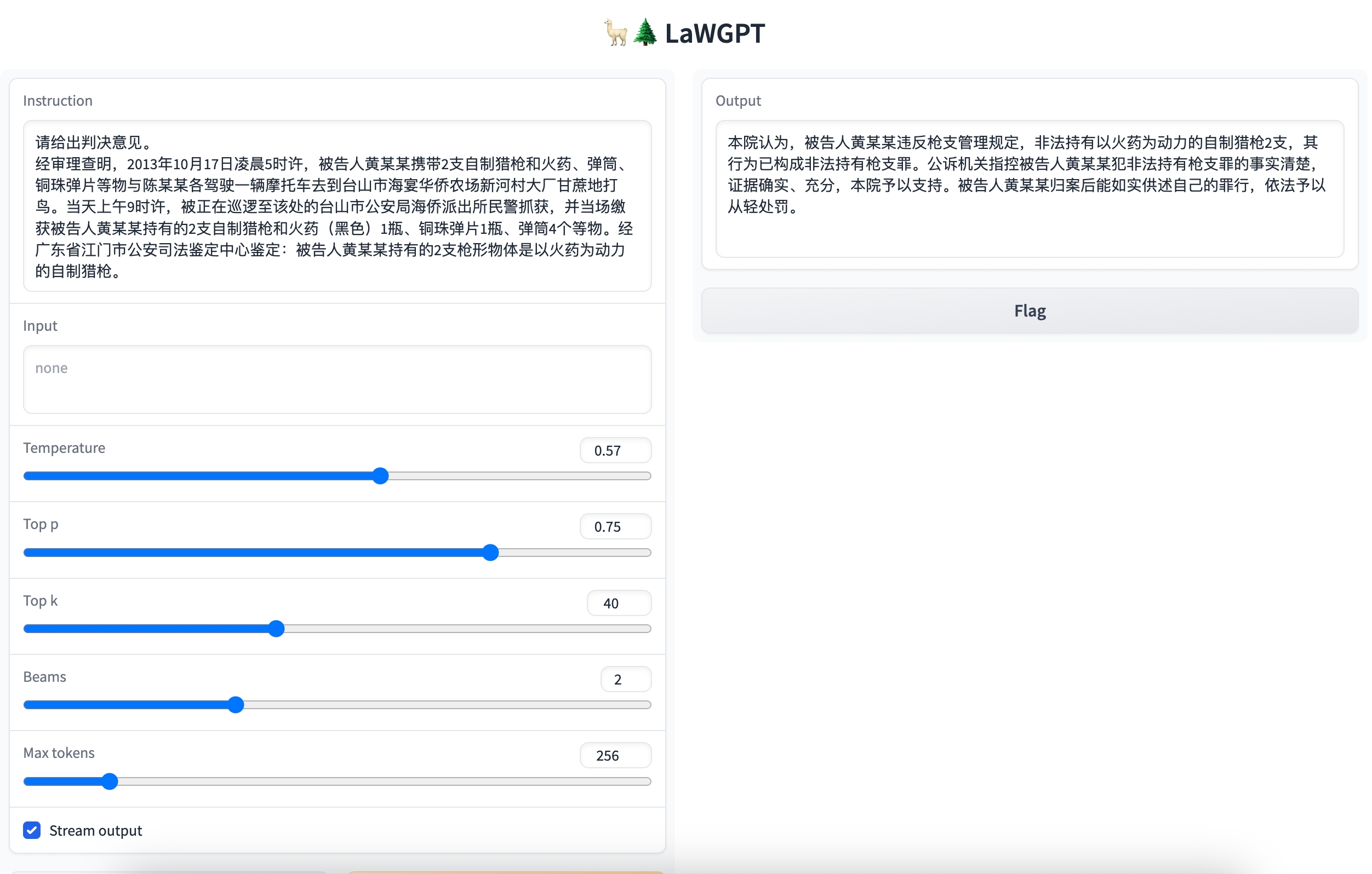
Question: Please give a verdict.
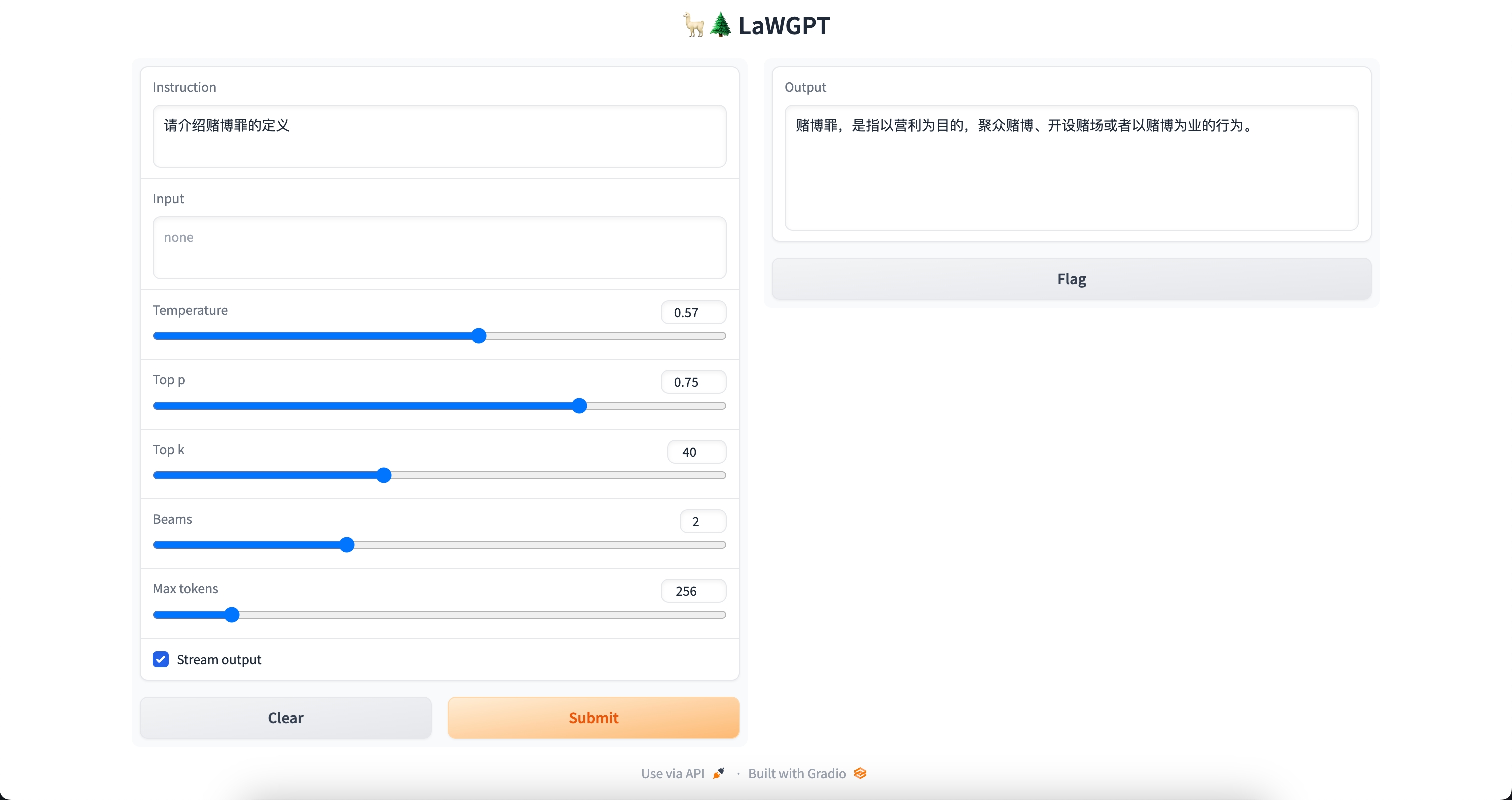
Question: Please introduce the definition of gambling crime.
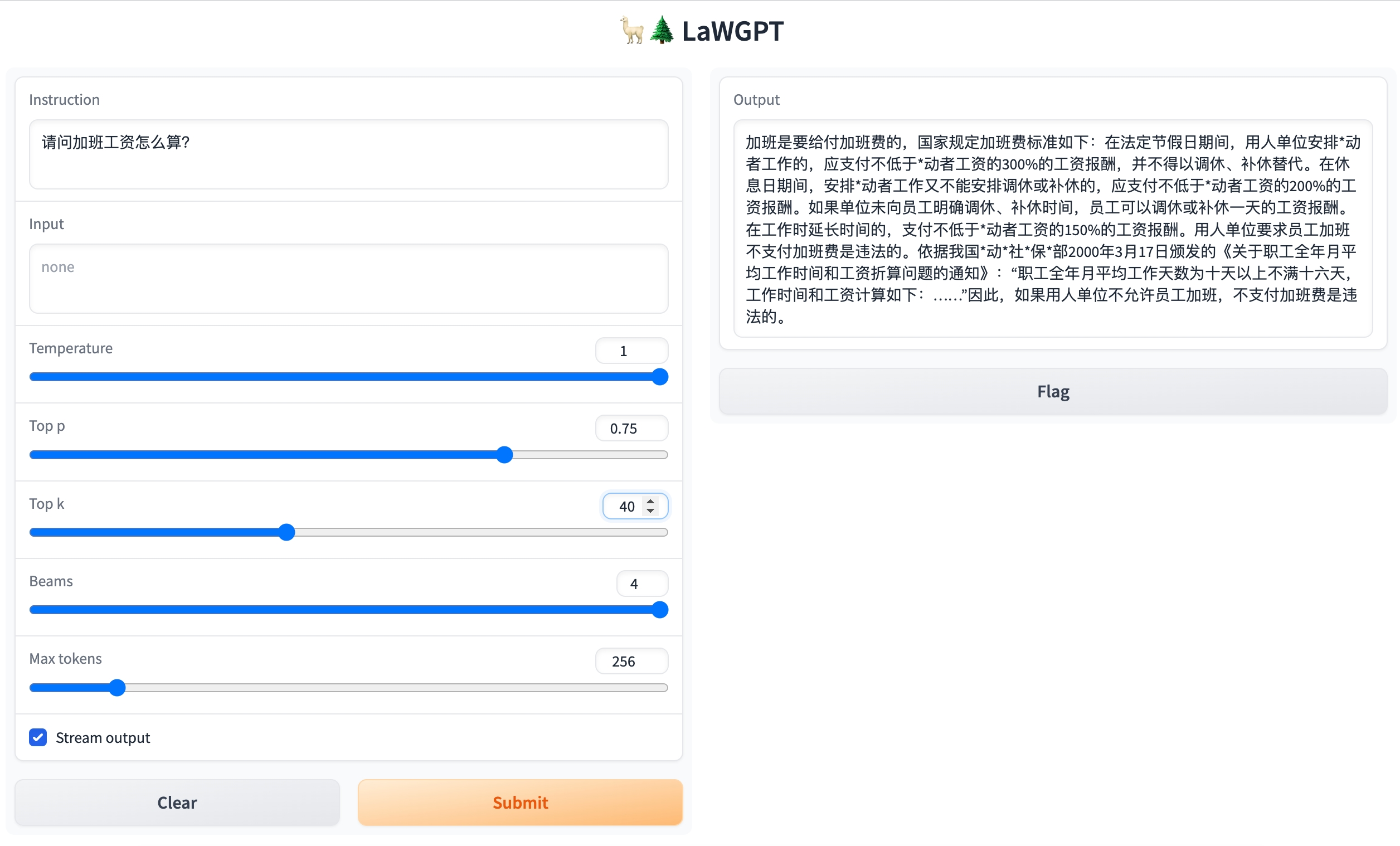
Question: What is the calculation of overtime wages?
limitation
Due to the limitations of computing resources, data scale and other factors, LawGPT has many limitations at the current stage:
- Limited data resources and small model capacity lead to relatively weak model memory and language ability. Therefore, incorrect results may be generated when faced with factual knowledge tasks.
- This family of models only performs preliminary human intent alignment. Therefore, unpredictable harmful content and content that does not conform to human preferences and values may be produced.
- There are problems in self-awareness ability, and Chinese comprehension ability needs to be improved.
#LaWGPT #Homepage #Documentation #Downloads #Large #Language #Model #Based #Chinese #Legal #Knowledge #News Fast Delivery