Pengcheng Pangu α is the industry’s first 200 billion parameter pre-trained language model with Chinese as the core. Currently, two versions are open source: Pengcheng Pangu α and Pengcheng Pangu α enhanced version, and support both NPU and GPU. It supports rich scene applications, and has outstanding performance in text generation fields such as knowledge question answering, knowledge retrieval, knowledge reasoning, and reading comprehension, and has a strong ability to learn with few samples.
Based on the Pangu series of large models, it provides large-scale model application landing technology to help users efficiently implement super-large pre-trained models to actual scenarios. The whole framework features are as follows:
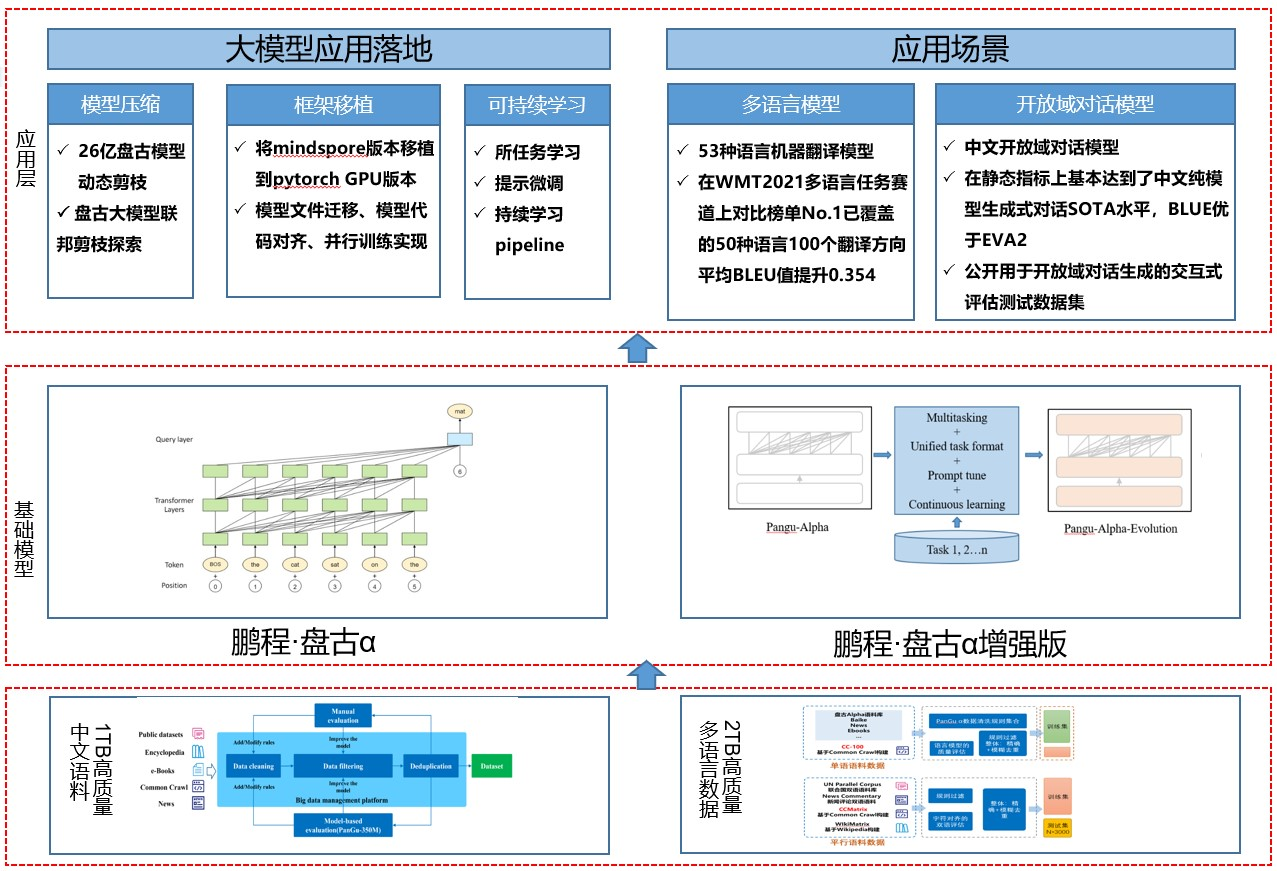
There are mainly the following core modules:
-
Dataset: Nearly 80TB of original corpus were collected from open source open datasets, common crawl datasets, e-books, etc., and a high-quality Chinese corpus dataset of about 1.1TB was constructed, and a high-quality monolingual and bilingual dataset of 53 languages was 2TB.
-
Basic module: Provides a pre-training model library and supports commonly used Chinese pre-training models, including Pengcheng·Pangu α, Pengcheng·Pangu α enhanced version, etc.
-
Application layer: supports common NLP applications such as multilingual translation, open domain dialogue, etc., and supports pre-trained model landing tools, including model compression, framework transplantation, and sustainable learning, to help large models quickly land.
#PengchengPangu #Homepage #Documentation #Download #Chinese #Pretrained #Language #Model #News Fast Delivery