Umi-OCR is a free, open-source, batch-capable offline OCR software based on PaddleOCR for Windows 10/11 platforms.
characteristic
- free: All codes of this project are open source and completely free.
- convenient: Unzip and use, offline operation, no network required.
- batch: Images can be imported and processed in batches, and the results are saved to local txt/md/jsonl files in various formats. You can also take instant screenshots for identification.
- efficient: Adopt PaddleOCR-json C++ recognition engine. Usually faster than online OCR services as long as the computer is powerful enough.
- precise: Use the PPOCR-v3 model library by default. In addition to being able to accurately recognize regular text, it also has a good recognition rate for scenarios such as handwriting, incorrect orientation, and messy backgrounds.Can be setignore areaExclude watermarks, settingsPost-processing of text blocksMerge typesetting paragraphs to get regular text.
Description directory
download
Umi-OCR software body contains Simplified Chinese & English Universal Recognition Library.
matching Multilingual Recognition Extension Pack can be imported繁中,英,日,韩,俄,德,法Recognition library, please download as needed.
Github download:Release v1.3.3
Lanzuo cloud download:https://hiroi-sora.lanzoul.com/s/umi-ocr
compatibility
- The system supports Win10 x64 and above.
- CPU must have AVX instruction set.
- Please refer to the Troubleshooting .
foreword
aboutIgnore specified areaspecial features of:
Similar to video screenshots with watermarks, game screenshots with UI/buttons, etc., often only need to extract the text in the subtitle area, and avoid extracting watermark and UI text. The software can be set to ignore text in certain areas to achieve this purpose.
When there are a large number of video and game screenshots that need to be sorted and archived, or you want to search for screenshots containing a certain line/subtitle; it is a very effective method to extract the text from these pictures and then press Ctrl+F. This is the original intention of developing this software.
About offline OCR engine Paddle OCR-json :
right PaddleOCR 2.6 cpu_avx_mkl C++ package. The efficiency is higher than the Python version PPOCR and some OCR engines written in Python, usually faster than the online OCR service (saving the time of network transmission). Support to replace the official Paddle model (compatible with v2 and v3 versions) or the model trained by yourself, and support to modify various parameters of PPOCR. By adding different language models, the software can recognize multiple languages.
easy to use
Prepare
Download the compressed package and unzip all the files.
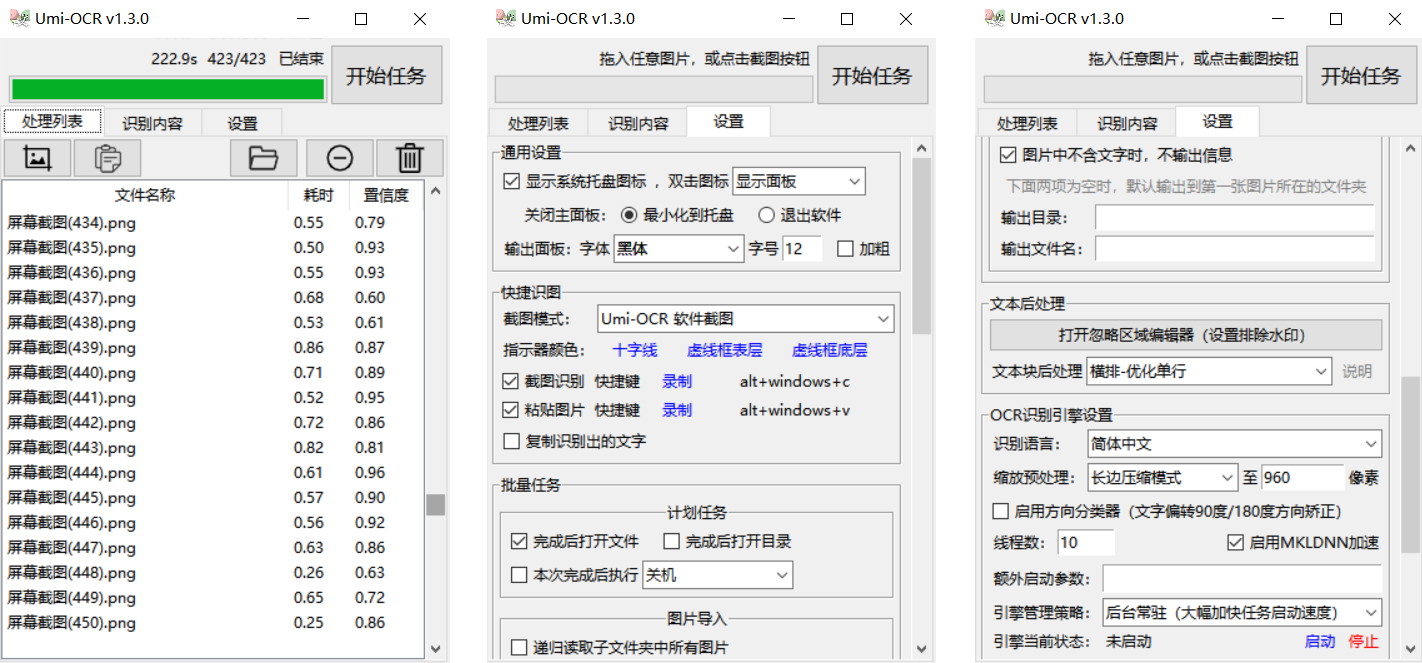
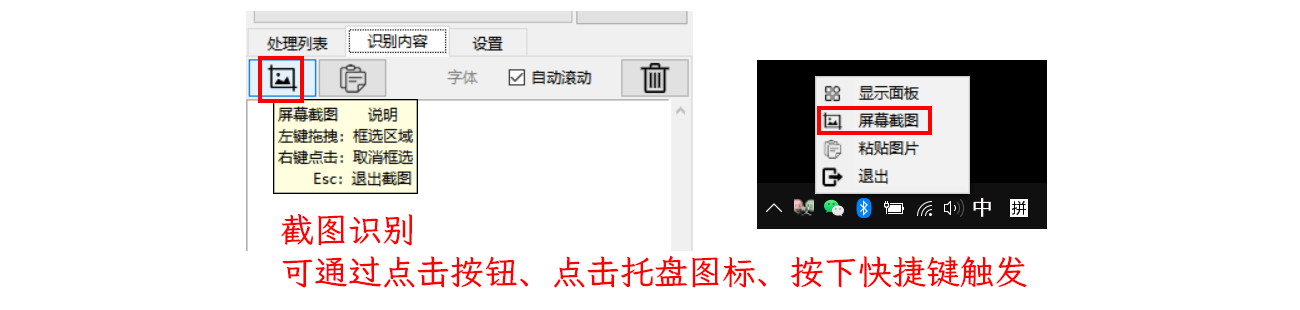
screenshot recognition
Click the screenshot button or customize the shortcut key to evoke the screenshot recognition.
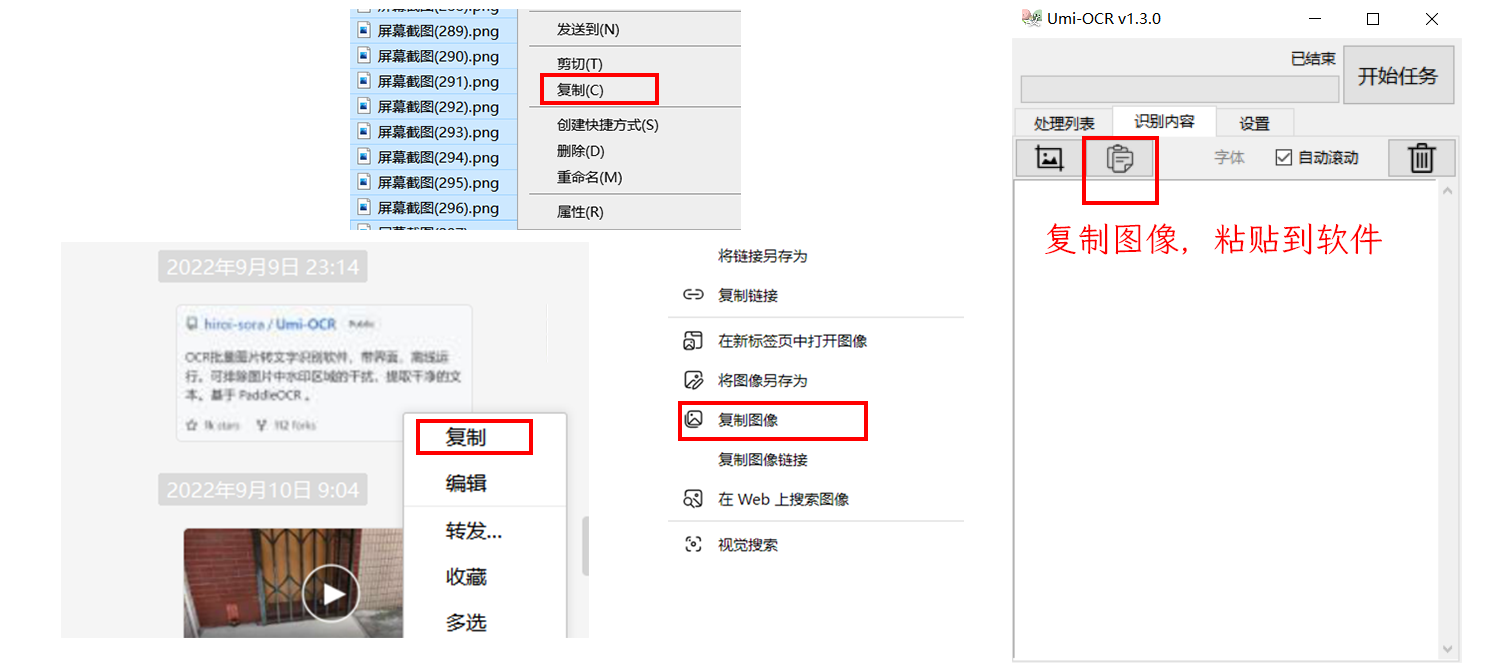
Paste the picture into the software
Copy the picture anywhere (such as file manager, web page, WeChat), click the paste button on the software, and it will be automatically recognized.
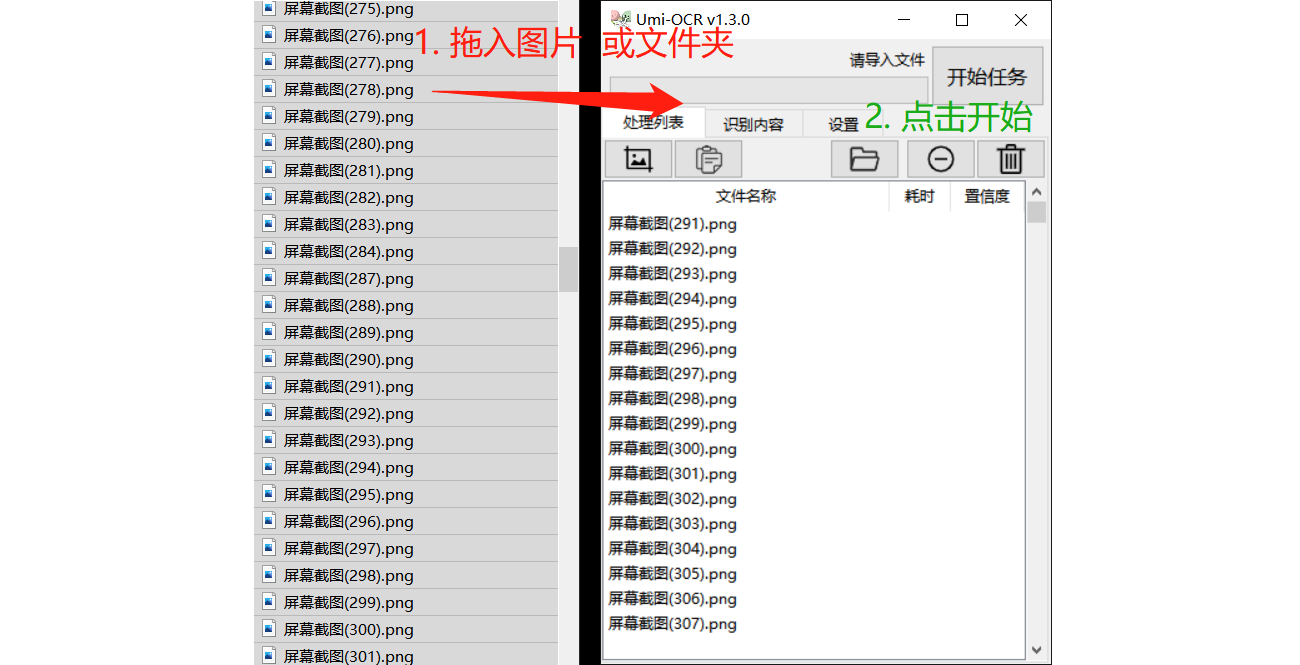
Identify local image files in batches
Drag pictures or folders into the software to convert text in batches. You can also click the button to open the browser window to import.
The recognition result will be saved locally. Optionally generate plain text txt files, Markdown files with links, raw information jsonl files and other formats. Perform shutdown/standby after configurable task completion.
Text block post-processing (typesetting optimization)
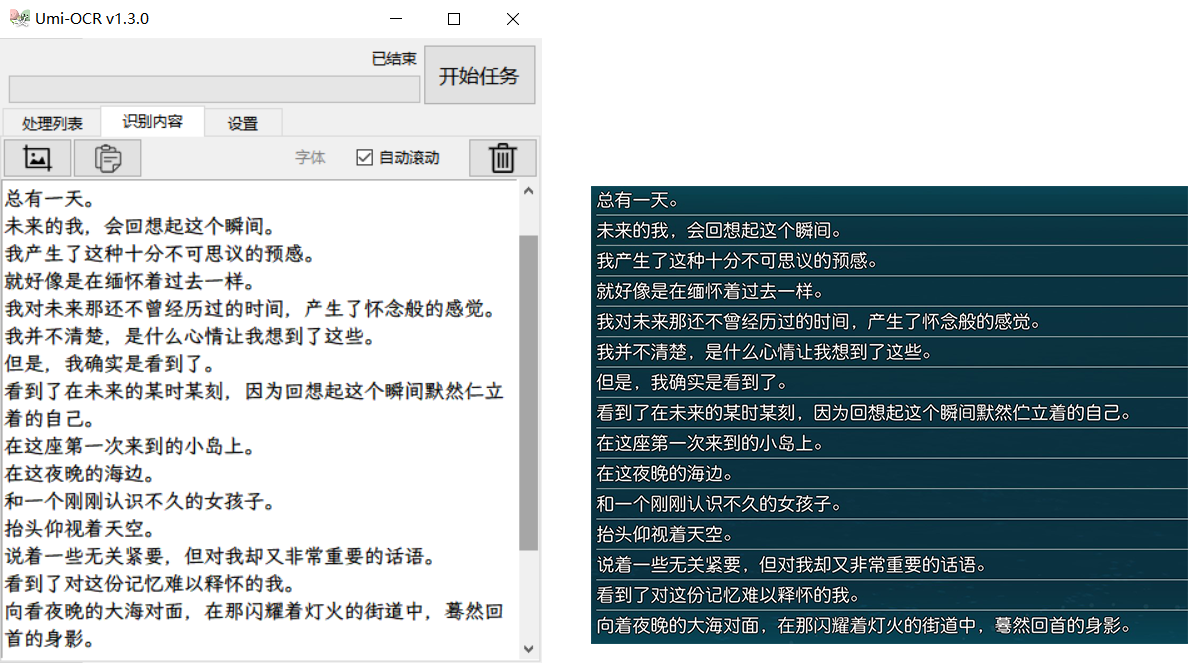
The text recognized by OCR is divided into “blocks”. Usually, a line of text is divided into one block, and sometimes a line is mistakenly divided into multiple blocks, which brings inconvenience to reading.text block postprocessingIt is the process of reprocessing the text blocks, merging the text in the same line or paragraph, and sorting them in the correct order.
The following figure shows which processing scheme should be selected for different typesetting:

#UmiOCR #Homepage #Documentation #Download #Offline #Text #Recognition #Tool #News Fast Delivery