GPTCache is a library for creating semantic caches to store responses from LLM queries.Cut your LLM API cost by 10x and speed it up by 100x.
ChatGPT and various large language models (LLMs) are incredibly versatile, enabling the development of a wide range of applications. However, as your application grows in popularity and encounters higher traffic levels, the costs associated with LLM API calls can become significant. Additionally, LLM services may exhibit slow response times, especially when processing a high volume of requests. GPTCache was created to address this challenge, a project dedicated to building a semantic cache for storing LLM responses.
GPTCache offers the following key benefits:
- reduce costs: Most LLM services are based on the number of requests andtoken countcombination charges. GPTCache effectively reduces your overhead by caching query results, which in turn reduces the number of requests and tokens sent to the LLM service. Therefore, you can enjoy a more cost-effective experience when using the service.
- enhanced performance: LLM employs generative AI algorithms to generate responses in real time, a process that can sometimes be time-consuming. However, when similar queries are cached, the response time is significantly improved because the results are fetched directly from the cache without interacting with the LLM service. In most cases, GPTCache can also provide higher query throughput than the standard LLM service.
- Adaptable development and test environment: As a developer of an LLM application, you know that connecting to the LLM API is often necessary and that it is critical to thoroughly test the application before moving it into production. GPTCache provides an interface that mirrors the LLM API and houses the storage of LLM-generated and simulated data. This feature enables you to effortlessly develop and test your application without connecting to the LLM service.
- Improved scalability and availability: The LLM service executes frequentlyrate limit, which is the limit imposed by the API on the number of times a user or client can access the server within a given time frame. Hitting the rate limit means that additional requests will be blocked until a certain period of time has elapsed, causing service disruption. With GPTCache, you can easily scale to accommodate increasing query volumes, ensuring consistent performance as your application user base grows.
How does it work?
Online services often exhibit data locality, with users frequently accessing popular or trending content. Caching systems take advantage of this behavior by storing frequently accessed data, which in turn reduces data retrieval time, improves response times, and reduces the burden on backend servers. Traditional caching systems typically leverage exact matches between new queries and cached queries to determine whether the requested content is available in the cache before fetching the data.
However, due to the complexity and variability of LLM queries, using the exact match approach with the LLM cache is less effective, resulting in a lower cache hit ratio. To solve this problem, GPTCache employs alternative strategies such as semantic caching. Semantic caching identifies and stores similar or related queries, increasing cache hit probability and improving overall cache efficiency.
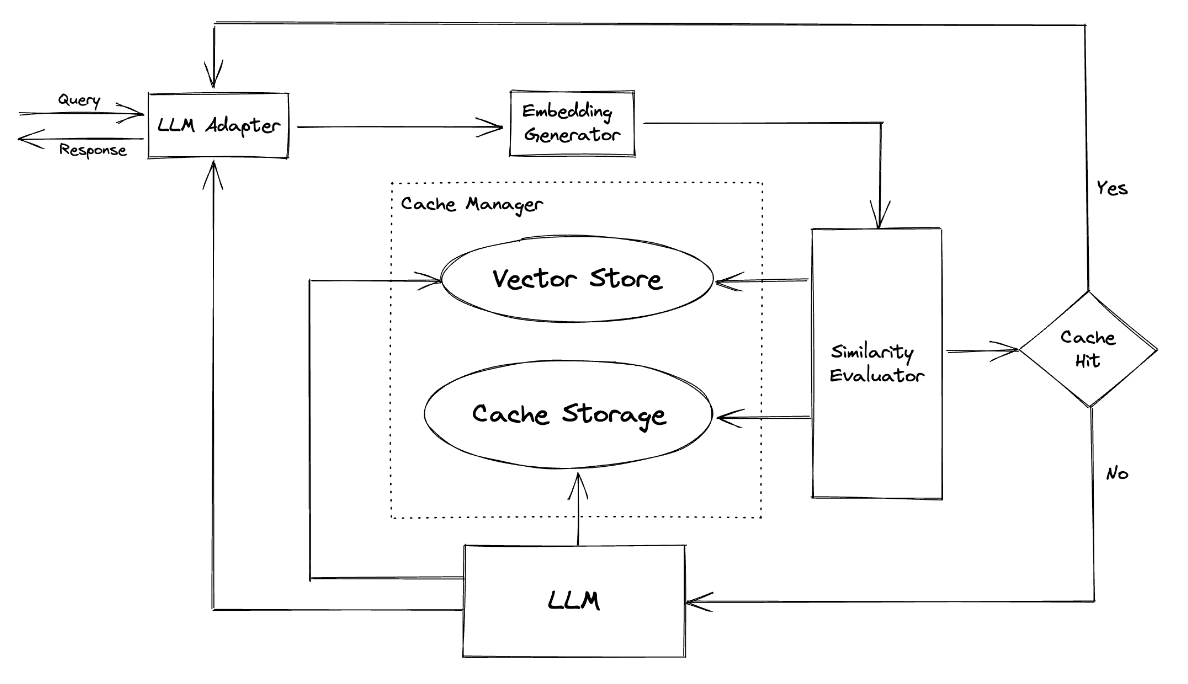
GPTCache uses an embedding algorithm to convert queries into embeddings, and uses a vector store to perform similarity searches on these embeddings.This process allows GPTCache to identify and retrieve similar or related queries from cache storage, such asmodule partshown.
GPTCache has a modular design, allowing users to easily customize their own semantic cache. The system provides different implementations for each module, and users can even develop their own implementations to meet their specific needs.
In semantic caching, you may experience false positives during cache hits and false negatives during cache misses. GPTCache provides three metrics to measure its performance, which help developers optimize their caching systems:
- hit rate: This metric quantifies the cache’s ability to successfully satisfy requests for content, compared to the total number of requests it has received. A higher hit ratio indicates a more efficient cache.
- Delay: This metric measures the time required to process a query and retrieve the corresponding data from cache. Lower latency means a more efficient and responsive caching system.
- recall rate: This metric represents the ratio of queries served by the cache to the total number of queries the cache would have served. A high recall percentage indicates that the cache is effectively serving appropriate content.
contains aexample benchmarkfor users to start evaluating the performance of their semantic cache.
#GPTCache #Homepage #Documentation #Downloads #library #creating #semantic #caches #LLM #queries #News Fast Delivery