MiniGPT-4 enhances visual-language understanding with advanced large-scale language models.
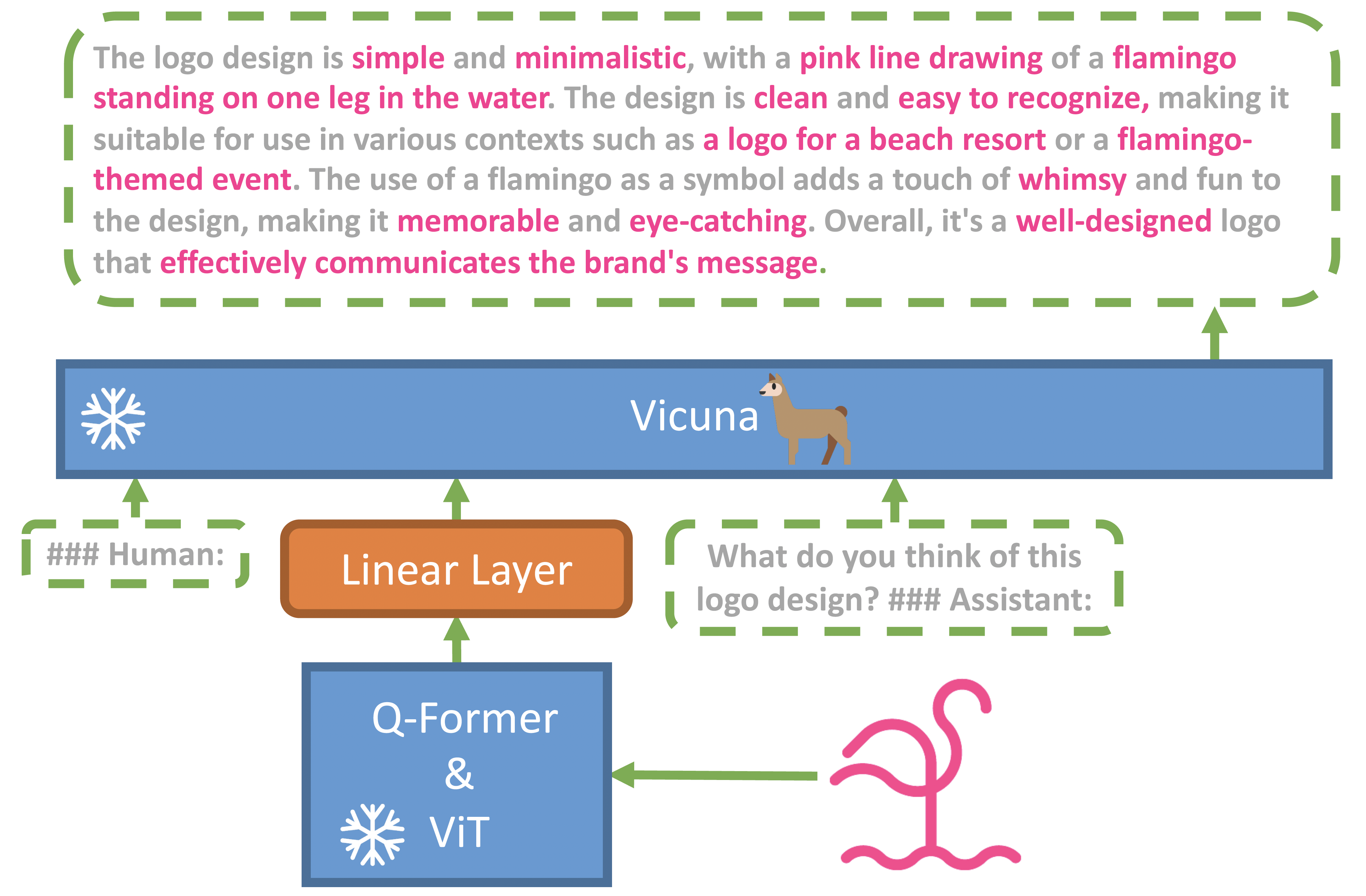
MiniGPT-4 aligns the frozen vision encoder from BLIP-2 with the frozen LLM Vicuna using only one projection layer. The training of MiniGPT-4 is divided into two stages:
- The first traditional pre-training stage is trained using about 5 million aligned image-text pairs in 10 hours using 4 A100s. After the first stage, Vicuna was able to understand the image. But Vicuna’s generation ability has been greatly affected.To solve this problem and improve usability, the development team proposed a new method to create high-quality image-text pairs through the model itself and ChatGPT together. Based on this, a small (3500 pairs in total) but high-quality dataset was subsequently created.
- The second fine-tuning stage trains this dataset on dialogue templates to significantly improve its generation reliability and overall usability. This stage is computationally efficient, taking about 7 minutes with a single A100. MiniGPT-4 yields many emerging visual-language features similar to those exhibited in GPT-4.
online demo
Choose one of the eight links belowfewer tasks queueddemo to chat.
Link1 / Link2 / Link3 / Link4 / Link5 / Link6 / Link7 / Link8
Upload an image first, then chat with MiniGPT-4 around your image
example
getting Started
Install
1. Prepare code and environment
Git clone our repository, create a python environment and activate it with the command
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigpt42. Prepare the pre-trained Vicuna weights
The current version of MiniGPT-4 is built on the v0 version of Vicuna-13B.Please refer toillustrateto prepare the Vicuna weights. The final weights will be in a single folder with the following structure:
vicuna_weights
├── config.json
├── generation_config.json
├── pytorch_model.bin.index.json
├── pytorch_model-00001-of-00003.bin
...
Then, set the path to the vicuna weights in the model configuration file on line 16.
3. Prepare the pre-trained MiniGPT-4 checkpoint
To use the official pretrained model, go todownload herePretrained checkpoints.
Then, set the path to the pretrained checkpoint in the evaluation configuration file in eval_configs/minigpt4_eval.yaml on line 11.
Start the demo locally
Try the demo on your local computer by running demo.py
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
Here Vicuna is loaded as 8-bit by default to save some GPU memory usage. Also, the default beam search width is 1.
At this setting, the demo consumes about 23G of GPU memory. If you have a more powerful GPU and more GPU memory, you can run the model in 16-bit by setting low_resource to False in the configuration file minigpt4_eval.yaml and use a larger beam search width.
train
The training of MiniGPT-4 consists of two alignment stages.
1. The first pre-training stage
In the first pre-training stage, the model is trained using image-text pairs from the Laion and CC datasets to align the vision and language models.
To download and prepare the dataset, see Phase 1 datasetspreparation instructions. After the first stage, the visual features are mapped and can be understood by the language model. To start the first phase of training, run the following command: (4 A100s were used in the experiment)
The save path can be changed in the configuration file train_configs/minigpt4_stage1_pretrain.yaml
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/minigpt4_stage1_pretrain.yamlallowablehereDownload the MiniGPT-4 checkpoint with only the first stage training.
Compared to models after the second stage, this checkpoint often generates incomplete and repetitive sentences.
2. The second fine-tuning stage
In the second stage, we use a self-created small high-quality image-text pair dataset and convert it into a dialogue format for further alignment with MiniGPT-4.
To download and prepare the Phase 2 dataset, seeInstructions for the preparation of the second stage dataset.To start the second-stage comparison, first specify the path to the checkpoint file for the first-stage training in train_configs/minigpt4_stage1_pretrain.yaml,Here you can also specify the output path at the same time.
Then, run the following command: (1 A100 is used in the experiment)
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/minigpt4_stage2_finetune.yamlAfter the second stage of alignment, MiniGPT-4 is able to talk about images coherently and user-friendly.
#MiniGPT4 #Homepage #Documentation #Downloads #Enhancing #Visual #Language #Understanding #LLM #News Fast Delivery