The ChatGPT dialogue model launched by OpenAI has set off a new wave of AI. It faces a variety of questions and answers, and seems to have broken the boundary between machines and humans. Behind this work is a new training paradigm in the field of Large Language Model (LLM) generation: RLHF (Reinforcement Learning from Human Feedback), which optimizes the language model based on human feedback by means of reinforcement learning.
Various LLMs over the past few years have been impressive in their ability to generate diverse text based on human input prompts. However, the evaluation of generated results is subjective and context-dependent. For example, we want the model to generate a creative story, a piece of real informative text, or an executable code snippet, which are difficult to achieve with existing rule-based It is measured by text generation metrics such as BLUE and ROUGE. In addition to evaluation metrics, existing models are usually modeled by predicting the next word and a simple loss function (such as cross-entropy), without explicitly introducing human preferences and subjective opinions.
if we Use human feedback of generated text as a performance metric, or go further and use this feedback as a loss to optimize the model, isn’t that better? This is the idea of RLHF: use reinforcement learning to directly optimize language models with human feedback. RLHF enables language models trained on general text data corpora to align complex human values.
See how ChatGPT interprets RLHF:
ChatGPT explains it well, but it doesn’t quite cover it; let’s be more specific!
RLHF Technology Breakdown
RLHF is a complex concept involving multiple models and different training stages, here we break it down in three steps:
- Pre-train a language model (LM);
- Aggregate question and answer data and train a reward model (Reward Model, RM);
- Fine-tuning LMs with reinforcement learning (RL).
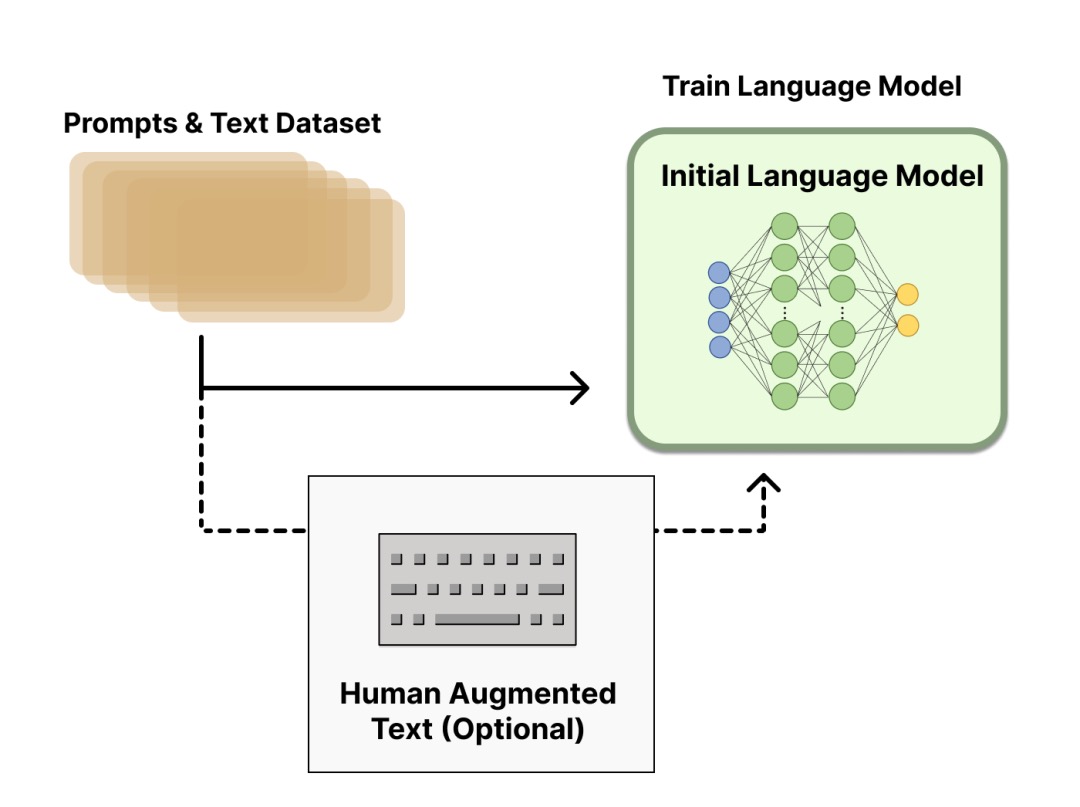
Step 1. Pre-trained language model
First, we train a language model using the classic pre-trained objective. For this step of the model, OpenAI used a smaller version of GPT-3 in its first popular RLHF model InstructGPT; Anthropic used a Transformer model with 10 million to 52 billion parameters for training; DeepMind used its own 280 billion Parametric model Gopher.
Here, this LM can be fine-tuned with additional text or conditions, for example, OpenAI fine-tuned the “preferable” (preferable) artificially generated text, while Anthropic distilled on context clues according to the “useful, honest and harmless” standard out of the original LM. Expensive data augmentation may be used here, but it is not a necessary step for RLHF. Since RLHF is still an unexplored field, there is no clear answer to “which model” is suitable as a starting point for RLHF.
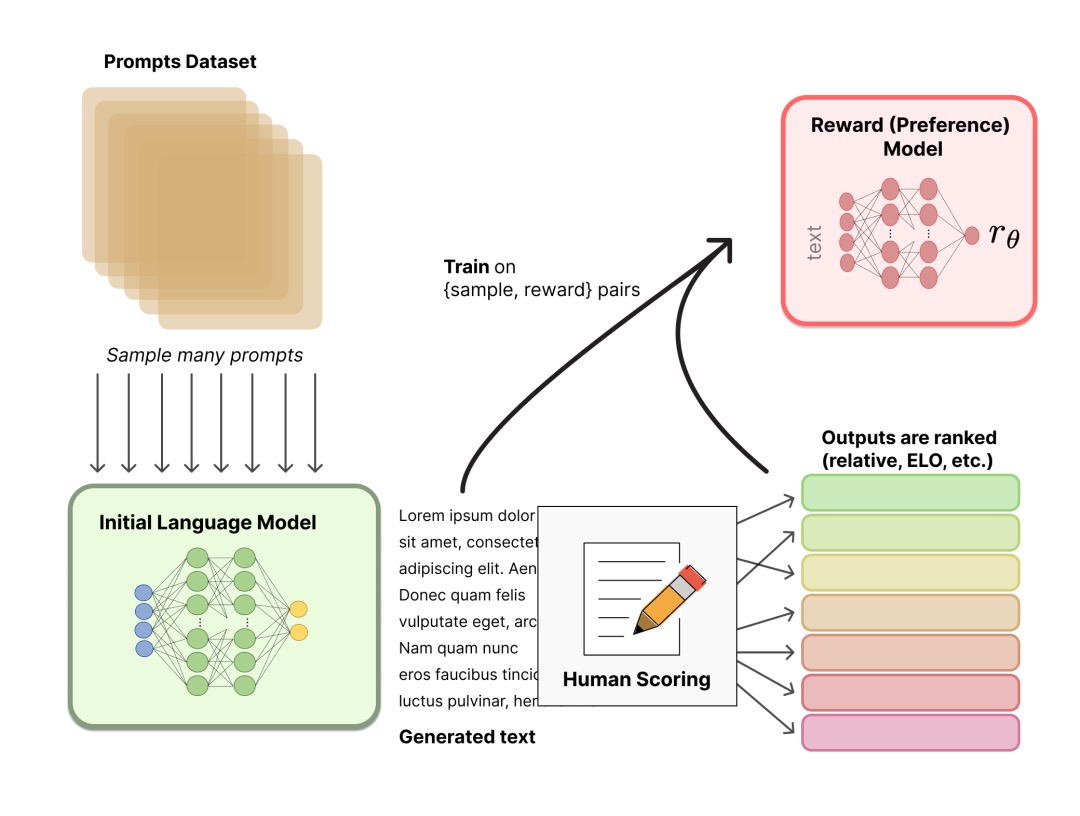
Next, we will generate training reward model (RM, also called preference model) data based on LM, and introduce human preference information in this step.
Step 2. Train the reward model
The training of RM is the beginning of the difference of RLHF from the old paradigm. This model takes a sequence of text and returns a scalar reward that numerically corresponds to the person’s preference. We can model this with LMs in an end-to-end fashion, or as a modular system (such as ranking outputs and converting the rankings to rewards). This reward value will be crucial for subsequent seamless access to existing RL algorithms.
Regarding model selection, the RM can be another fine-tuned LM, or an LM trained from scratch on preference data. For example, Anthropic proposes a special pre-training method, which uses Preference Model Pretraining (PMP) to replace the fine-tuning process after general pre-training. Because the former is considered to have a higher utilization rate of sample data. But the jury is still out on which RM is better.
Regarding the training text, the RM’s hint-generation pairs are sampled from a predefined dataset, and the initial LM is used to generate text for these hints. Anthropic’s data is mainly generated through chat tools on Amazon Mechanical Turk and available on Hub (https://huggingface.co/datasets/Anthropic/hh-rlhf), while OpenAI uses prompts submitted by users to the GPT API .
Regarding the value of training rewards, it is necessary to manually rank the answers generated by LM. At first we might think that RM should be trained directly on text annotation scores, but these scores are not calibrated and full of noise due to the different values of the annotators. Ranking allows you to compare the output of multiple models and build better canonical datasets.
For specific ranking methods, a successful approach is to compare the output of different LMs given the same prompt, and then use the Elo system to build a complete ranking. These different ranking results will be normalized to a scalar reward value for training.
An interesting artifact of this process is that currently successful RLHF systems use and generate models with different The size of LM (for example, OpenAI uses 175B LM and 6B RM, Anthropic uses LM and RM ranging from 10B to 52B, and DeepMind uses 70B Chinchilla model as LM and RM respectively). One intuition is that preference models and generative models need to have similar abilities to understand the text presented to them.
Next comes the final step: fine-tuning the LM with reinforcement learning using the rewards output by the RM.
Step 3. Fine-tuning with reinforcement learning
Training LMs with reinforcement learning has long been considered impossible for engineering and algorithmic reasons. At present, the feasible solution found by many organizations is to use Policy Gradient RL algorithm and Proximal Policy Optimization (PPO) to fine-tune some or all parameters of the initial LM. Because the cost of fine-tuning the entire 10B~100B+ parameters is too high (relevant work refers to low-rank adaptation to LoRA and DeepMind’s Sparrow LM). The PPO algorithm has been around for a relatively long time, and there is plenty of guidance on its principles, making it a favorable choice in RLHF.
It turns out that many of the core RL advances in RLHF have been figuring out how to apply familiar RL algorithms to updating such large models.
Let us first formulate the fine-tuning task as an RL problem. First, the policy is an LM that takes a prompt and returns a sequence of texts (or a probability distribution of texts). The action space of this strategy is all the tokens corresponding to the LM vocabulary (generally on the order of 50k), and the observation space is the possible input token sequence, which is also relatively large (vocabulary ^ input token quantity) . The reward function is a combination of a preference model and a policy shift constraint.
The specific calculation of the reward function determined by the PPO algorithm is as follows: Input the prompt into the initial LM and the current fine-tuned LM to get the output text respectively, and pass the text from the current policy to the RM to get a scalar reward. Comparing the generated text of the two models calculates a penalty term for the difference, designed in several papers from OpenAI, Anthropic, and DeepMind as a scaling of the Kullback–Leibler (KL) divergence between output word distribution sequences, ie. This term is used to penalize RL policies that generate large deviations from the initial model in each training batch, ensuring that the model outputs reasonably coherent text. If this penalty term is removed, the model may generate garbled text during optimization to fool the reward model into providing high reward values. In addition, OpenAI experimented with adding a new pre-training gradient to PPO on InstructGPT, and it can be predicted that the formula of the reward function will continue to evolve with the progress of RLHF research.
Finally, according to the PPO algorithm, we optimize according to the reward index of the current batch of data (from the on-policy characteristics of the PPO algorithm). The PPO algorithm is a Trust Region Optimization (TRO) algorithm that uses gradient constraints to ensure that the update step does not destabilize the learning process. DeepMind uses a similar reward setup for Gopher, but uses an A2C (synchronous advantage actor-critic) algorithm to optimize the gradient.
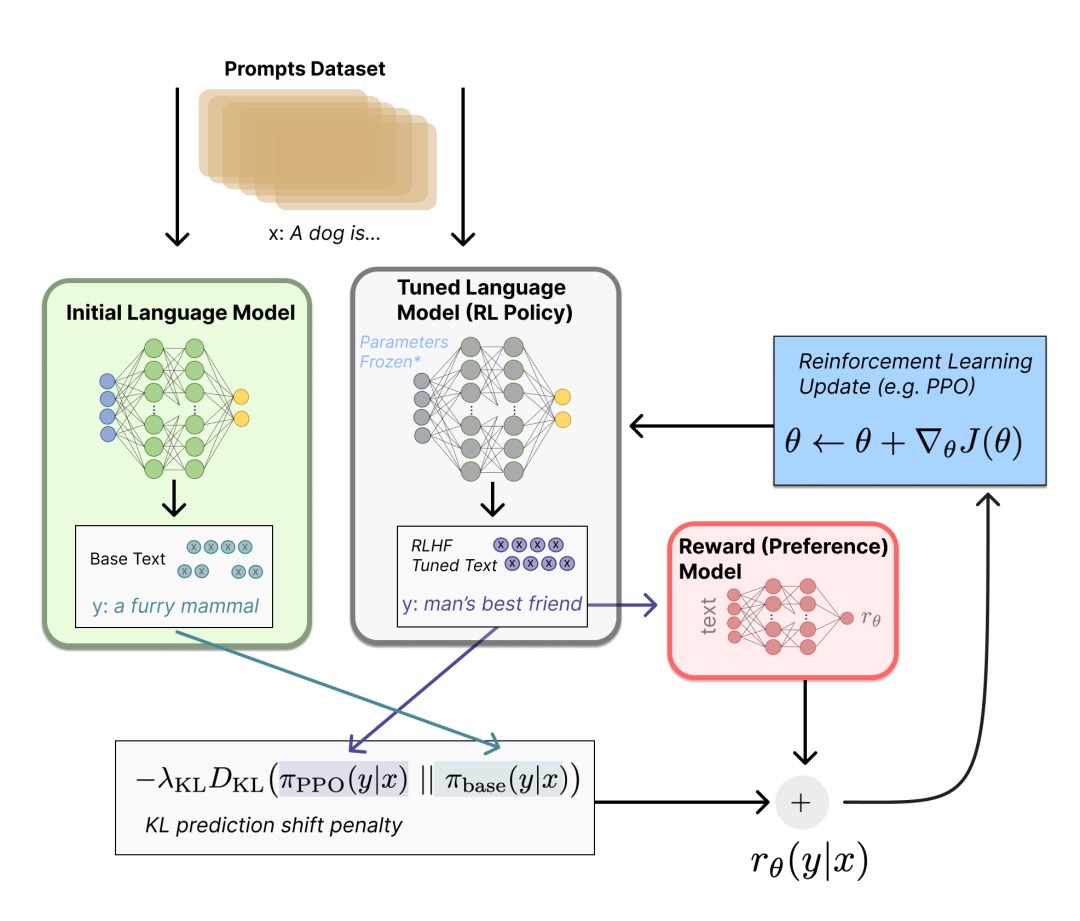
As an option, RLHF can be co-optimized by iterative RM and policy. As the policy model is updated, users can continue to rank the outputs combined with earlier outputs. Anthropic discusses iterative online RLHF in their paper, where iteration of policies is included in a cross-model Elo ranking system. This introduction of complex dynamics of strategy and RM evolution represents a complex and open research question.
The future of RLHF
Despite some success and attention in RLHF, limitations remain. These models still output harmful or inauthentic text without uncertainty. This imperfection is also a perennial challenge and motivator for RLHF – operating within the inherent realm of being human means never reaching a perfect standard.
The quality and quantity of collected human preference data determine the upper limit of RLHF system performance. RLHF systems require two kinds of human preference data: human-generated text and preference labels for model outputs. Generating high-quality answers requires hiring part-timers (instead of relying on product users and crowdsourcing). On the other hand, the size of the reward labels required to train RM is around 50k, so not that expensive (certainly well beyond the budget of an academic lab). The currently relevant datasets are only a general LM-based RLHF dataset (from Anthropic) and several smaller subtask datasets (such as the summarization dataset from OpenAI). Another challenge comes from annotator bias. Several human annotators may disagree, leading to some potential variance in the training data.
Data constraints aside, some design options remain to be explored to allow RLHF to make great strides. For example in terms of improvements to RL optimizers, PPO is an older algorithm, but there is currently no structural reason why other algorithms should have an advantage over existing RLHF work. In addition, a major cost of fine-tuning the LM strategy is that the text generated by the strategy needs to be evaluated on the RM. The offline RL optimization strategy can save the prediction cost of these large model RMs. Recently, new RL algorithms such as Implicit Language Q-Learning (ILQL) have emerged that are also suitable for current RL optimization. Other core tradeoffs in the RL training process, such as the exploration-exploitation balance, have also yet to be tried and documented. Exploring these directions can at least deepen our understanding of RLHF and further improve the performance of the system.
References
First introduce some related open source work:
The first project about RLHF, from OpenAI: https://github.com/openai/lm-human-preferencesy
Some PyTorch repo:
Also, there is a large dataset created by Anthropic on Huggingface Hub:
https://huggingface.co/datasets/Anthropic/hh-rlhf
Related papers include advances in RLHF prior to existing LMs and work on RLHF based on current LMs:
- TAMER: Training an Agent Manually via Evaluative Reinforcement (Knox and Stone 2008)
- Interactive Learning from Policy-Dependent Human Feedback (MacGlashan et al. 2017)
- Deep Reinforcement Learning from Human Preferences (Christiano et al. 2017)
- Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces (Warnell et al. 2018)
- Fine-Tuning Language Models from Human Preferences (Zieglar et al. 2019)
- Learning to summarize with human feedback (Stiennon et al., 2020)
- Recursively Summarizing Books with Human Feedback (OpenAI Alignment Team 2021)
- WebGPT: Browser-assisted question-answering with human feedback (OpenAI, 2021)
- InstructGPT: Training language models to follow instructions with human feedback (OpenAI Alignment Team 2022)
- GopherCite: Teaching language models to support answers with verified quotes (Menick et al. 2022)
- Sparrow: Improving alignment of dialogue agents via targeted human judgments (Glaese et al. 2022)
- ChatGPT: Optimizing Language Models for Dialogue (OpenAI 2022)
- Scaling Laws for Reward Model Overoptimization (Gao et al. 2022)
- Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback (Anthropic, 2022)
- Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned (Ganguli et al. 2022)
- Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning (Cohen at al. 2022)
- Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization (Ramamurthy and Ammanabrolu et al. 2022)
This article is translated from Hugging Face official blog (https://huggingface.co/blog/rlhf)
Please click on the original blog to view the link of the reference materials. You can also check out our live event replay to learn more: RLHF: From Zero to ChatGPTTranslator of this article:
Li Luoqiu, a master of computer science from Zhejiang University, mainly researches in the field of NLP.
We are recruiting more translation volunteers to help us expand the content of our official account. If you are interested, please click here to fill out the volunteer recruitment form. Thanks!
#hero #ChatGPTDetailed #explanation #RLHF #technology #Hugging #Face #News Fast Delivery