Author: JD Logistics Ji Zhuozhi
At present, there are a lot of source code analysis about the jump table structure and Redis on the market, but after long-term observation, it is found that most of them just stay on the surface of the code, without systematically introducing the origin of the jump table and the origin of various constants. As a probabilistic data structure, understanding the origin of various constants can be better changed and applied to high-performance function development. This article does not repeat the code analysis of existing excellent implementations, but systematically introduces and formally analyzes the jump table, and gives the jump table expansion method in specific scenarios, so that readers can better understand Understand the skip list data structure.
jump table[1,2,3]is a probabilistic data structure used to replace balanced trees in most applications. Skip lists have the same upper bound on expected time as balanced trees, and are simpler, faster, and use less space. Faster and simpler than balanced trees for linear operations on lookups and lists.
Probabilistic balancing can also be used in tree-based data structures[4]On, such as tree piles (Treap).Like the balanced binary tree, the jump table also implements the following two operations
- cite by search[5]it is guaranteed that starting from any element, the expected time to search for any element at interval k in the list is O(logk)
- Realize the general operation of the linear list (such as _insert the element after the kth element of the list_)
These kinds of operations can also be implemented in a balanced tree, but it is simpler and very fast to implement in a jump table, and it is usually difficult to implement directly in a balanced tree (tree threading can achieve the same effect as a linked list , but this complicates the implementation[6])
Probably the simplest data structure to support lookups is a linked list. Figure.1 is a simple linked list. The time to perform a lookup in the linked list is proportional to the number of nodes that must be checked, and this number is at most N.

Figure.1 Linked List
Figure.2 represents a linked list, in which each node has an additional pointer pointing to its nodes in the first two positions in the list. Because of this forward pointer, at most ⌈N/2⌉+1 nodes are examined in the worst case.

Figure.2 Linked List with fingers to the 2nd forward elements
Figure.3 extends this idea, each node whose ordinal number is a multiple of 4 has a pointer pointing to the next node whose ordinal number is a multiple of 4. Only ⌈N/4⌉+2 nodes are examined.

Figure.3 Linked List with fingers to the 4th forward elements
The general situation of this jump amplitude is shown in Figure.4. Each 2i node has a pointer pointing to the next 2i node, and the interval between the forward pointers is at most N/2. It can be proved that the total number of pointers will not exceed 2N at most (see space complexity analysis), but now at most ⌈logN⌉ nodes are examined in one search. This means that the total time consumption in a search is O(logN), which means that the search in this data structure is basically equivalent to binary search (binary search).

Figure.4 Linked List with fingers to the 2ith forward elements
In this data structure, each element is represented by a node. Each node has a height (height) or level (level), indicating the number of forward pointers the node has. Each node’s i-th forward pointer points to the next node at level i or higher.
In the data structure described above, the level of each node is related to the number of elements. When inserting or deleting, the data structure needs to be adjusted to meet such constraints, which is very rigid and inefficient. To this end, the restriction that each 2i node has a pointer to the next 2i node can be removed, and each new node is assigned a random level when a new element is inserted regardless of the number of elements in the data structure.


Figure.5 Skip List
So far, all the necessary and sufficient conditions for the linked list to support fast search have been obtained, and this form of data structure is the jump list.Next, we will use a more formal way to define the skip table
- All elements are represented by a node in the jump list.
- Each node has a height or level, sometimes called a step, and the level of a node is a random number independent of the total number of elements. Specifies that the level of NULL is ∞.
- Each node with level k has k forward pointers, and the i-th forward pointer points to the next node with level i or higher.
- The level of each node will not exceed an explicit constant MaxLevel. The level of the entire jump table is the highest value of the levels of all nodes. If the skip list is empty, then the level of the skip list is 1.
- There is a head node head, its level is MaxLevel, and all forward pointers of levels higher than the jump table point to NULL.
It will be mentioned later that the node search process starts from the highest-level pointer at the head node and walks along this level until it finds the next node (or NULL) that is larger than the node you are looking for. Every node level is not used except the head node, soEach node does not need to store the level of the node.
In the jump table, the forward pointer with level 1 has exactly the same function as the next pointer in the original linked list structure, so the jump table supports all algorithms supported by the linked list.
The structure definition corresponding to the high-level language is as follows (all subsequent code examples will be described in C language)
#define SKIP_LIST_KEY_TYPE int
#define SKIP_LIST_VALUE_TYPE int
#define SKIP_LIST_MAX_LEVEL 32
#define SKIP_LIST_P 0.5
struct Node {
SKIP_LIST_KEY_TYPE key;
SKIP_LIST_VALUE_TYPE value;
struct Node *forwards[]; // flexible array member
};
struct SkipList {
struct Node *head;
int level;
};
struct Node *CreateNode(int level) {
struct Node *node;
assert(level > 0);
node = malloc(sizeof(struct Node) + sizeof(struct Node *) * level);
return node;
}
struct SkipList *CreateSkipList() {
struct SkipList *list;
struct Node *head;
int i;
list = malloc(sizeof(struct SkipList));
head = CreateNode(SKIP_LIST_MAX_LEVEL);
for (i = 0; i < SKIP_LIST_MAX_LEVEL; i++) {
head->forwards[i] = NULL;
}
list->head = head;
list->level = 1;
return list;
}
From the previous preview chapters, it is not difficult to see that the value of MaxLevel affects the query performance of the jump table, and the value of MaxLevel will be introduced in subsequent chapters. Here, MaxLevel is defined as 32, which is sufficient for a jump table with 232 elements. Continuing the description in the preview chapter, the probability of skipping the table is defined as 0.5, and the selection of this value will be introduced in detail in subsequent chapters.
search
The process of searching in the jump list is accomplished by zigzag traversing all forward pointers that do not exceed the target element to be sought. When there is no forward pointer to move at the current level, it will move to the next level to search. Stop searching until level 1 and there is no forward pointer that can be moved. At this time, the directly pointed node (forward pointer with level 1) is the node containing the target element (if the target element is in the list). The process of searching for element 17 in the skip list is shown in Figure.6.

Figure.6 A search path to find element 17 in Skip List
The sample code of the whole process is as follows, because the array subscript in high-level language starts from 0, so forwards[0]A forward pointer representing a node’s level 1, and so on
struct Node *SkipListSearch(struct SkipList *list, SKIP_LIST_KEY_TYPE target) {
struct Node *current;
int i;
current = list->head;
for (i = list->level - 1; i >= 0; i--) {
while (current->forwards[i] && current->forwards[i]->key < target) {
current = current->forwards[i];
}
}
current = current->forwards[0];
if (current->key == target) {
return current;
} else {
return NULL;
}
}
insert and delete
In the process of inserting and deleting nodes, the same logic as searching needs to be performed. On the basis of the search, a vector named update needs to be maintained, which maintains the rightmost value traversed at each level of the jump table during the search process, indicating that the left side of the inserted or deleted node directly points to it The node is used to adjust the forward pointers of all levels where the node is located after insertion or deletion (the same process as a naive linked list node insertion or deletion).
When the level of the newly inserted node exceeds the level of the current jump table, it is necessary to increase the level of the jump table and modify the node of the corresponding level in the update vector to the head node.
Figure.7 and Figure.8 show the process of inserting element 16 in the skip list. First, perform the same query process as the search in Figure.7, and the forward pointer of the last element traversed at each level is marked in gray at the corresponding level, indicating that the alignment will be adjusted later. Next, in Figure.8, insert element 16 after the node with element 13. The level of the node corresponding to element 16 is 5, which is higher than the current level of the jump table, so you need to increase the level of the jump table to 5, and set The forward pointer of the level corresponding to the head node is marked in gray. All dotted lines in Figure.8 represent the adjusted effect.

Figure.7 Search path for inserting element 16

Figure.8 Insert element 16 and adjust forward pointers
struct Node *SkipListInsert(struct SkipList *list, SKIP_LIST_KEY_TYPE key, SKIP_LIST_VALUE_TYPE value) {
struct Node *update[SKIP_LIST_MAX_LEVEL];
struct Node *current;
int i;
int level;
current = list->head;
for (i = list->level - 1; i >= 0; i--) {
while (current->forwards[i] && current->forwards[i]->key < target) {
current = current->forwards[i];
}
update[i] = current;
}
current = current->forwards[0];
if (current->key == target) {
current->value = value;
return current;
}
level = SkipListRandomLevel();
if (level > list->level) {
for (i = list->level; i < level; i++) {
update[i] = list->header;
}
}
current = CreateNode(level);
current->key = key;
current->value = value;
for (i = 0; i < level; i++) {
current->forwards[i] = update[i]->forwards[i];
update[i]->forwards[i] = current;
}
return current;
}
After deleting a node, if the deleted node is the node with the highest level in the skip list, then the level of the skip list needs to be reduced.
Figure.9 and Figure.10 show the process of deleting element 19 in the skip list. First, perform the same query process as the search in Figure.9, and the forward pointer of the last element traversed at each level is marked in gray at the corresponding level, indicating that the alignment will be adjusted later. Next in Figure.10, the node corresponding to element 19 is first unloaded from the jump table by adjusting the forward pointer, because the node corresponding to element 19 is the node with the highest level, so it needs to be adjusted after it is removed from the jump table The level of the jump table. All dotted lines in Figure.10 represent the adjusted effect.

Figure.9 Search path for deleting element 19

Figure.10 Delete element 19 and adjust forward pointers
struct Node *SkipListDelete(struct SkipList *list, SKIP_LIST_KEY_TYPE key) {
struct Node *update[SKIP_LIST_MAX_LEVEL];
struct Node *current;
int i;
current = list->head;
for (i = list->level - 1; i >= 0; i--) {
while (current->forwards[i] && current->forwards[i]->key < key) {
current = current->forwards[i];
}
update[i] = current;
}
current = current->forwards[0];
if (current && current->key == key) {
for (i = 0; i < list->level; i++) {
if (update[i]->forwards[i] == current) {
update[i]->forwards[i] = current->forwards[i];
} else {
break;
}
}
while (list->level > 1 && list->head->forwards[list->level - 1] == NULL) {
list->level--;
}
}
return current;
}
generate random levels

int SkipListRandomLevel() {
int level;
level = 1;
while (random() < RAND_MAX * SKIP_LIST_P && level <= SKIP_LIST_MAX_LEVEL) {
level++;
}
return level;
}
The following table shows the distribution of random levels generated after executing the above algorithm 232 times.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 2147540777 | 1073690199 | 536842769 | 268443025 | 134218607 | 67116853 | 33563644 | 16774262 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 8387857 | 4193114 | 2098160 | 1049903 | 523316 | 262056 | 131455 | 65943 |
| 17 | 18 | 19 | 20 | twenty one | twenty two | twenty three | twenty four |
| 32611 | 16396 | 8227 | 4053 | 2046 | 1036 | 492 | 249 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 |
| 121 | 55 | 34 | 16 | 7 | 9 | 2 | 1 |
The choice of MaxLevel
In Figure.4, the most ideal distribution for a jump table with 10 elements is given, where the level of 5 nodes is 1, the level of 3 nodes is 2, the level of 1 node is 3, and the level of 1 node The level is 4.
This begs the question:Since under the same number of elements, different levels of the jump table will have different performance, so what is the appropriate level of the jump table?

Space Complexity Analysis
As mentioned earlier,The score p represents the probability that the node has both the i-th layer forward pointer and the i+1-th layer forward pointer, and the level of each node is at least 1, so the number of forward pointers at level i is npi−1.Define S(n) to represent the total amount of all forward pointers, which can be obtained from the sum formula of the geometric sequence
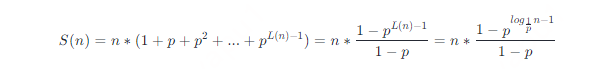
To find the limit of S(n), we have
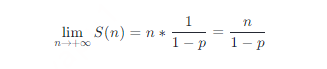
It is easy to prove that this is a monotonically increasing function on p, so the larger the value of p, the more the total number of forward pointers in the jump table. Since 1−p is a known constant, it is said that the space complexity of the skip list is O(n).
Time Complexity Analysis
informal analysis

formal analysis

The continuation_fraction p represents the definition of the probability_ that the node has both the i-th layer forward pointer and the i+1-th layer forward pointer, considering the reverse direction analysis search path.
The path searched is always less than the number of comparisons that must be performed. We first need to examine the number of pointers that need to be backtracked to climb from level 1 (the last node traversed before searching for an element) to level L(n). Although it can be determined that the level of each node is known and determined during the search, it is still considered here that it can only be determined when the entire search path is traced backwards, and it is not determined before climbing to the level L(n). Will touch the head node.
At any particular point in the climb, it is considered to be at the i-th forward pointer of element x, and the levels of all elements to the left of element x or the level of element x are not known, but it is known that the level of element x is at least i . The probability that the level of element x is greater than i is p, and this reverse climbing process can be considered as a series of random independent experiments by successfully climbing to a higher level or failing to move to the left.
During the climb to level L(n), the number of moves to the left is equal to the number of failures before the L(n)−1th success in consecutive random trials, which fits the negative binomial distribution. The expected number of upward moves must be L(n)−1. Therefore, the cost of climbing to L(n) in an infinite list can be obtained CC=prob(L(n)−1)+NB(L(n)−1,p) The infinite length of the list is a pessimistic assumption. When the head node is touched during the reverse climb, you can climb directly up without any leftward movement. Therefore, the cost C(n) of climbing to L(n) in the list of n elements can be obtained
C(n)≤probC=prob(L(n)−1)+NB(L(n)−1,p)
So the mathematical expectation and variance of the cost C(n) of climbing to L(n) in a list of n elements is
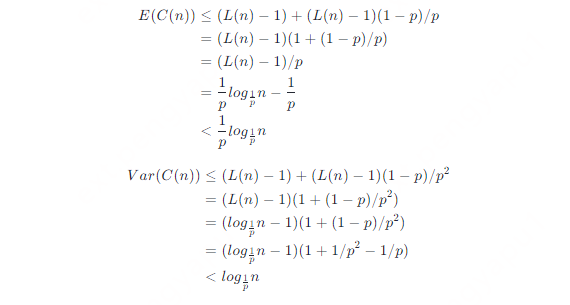
Because 1/p is a known constant, the time complexity of searching, inserting, and deleting the skip list is O(logn).
P’s choice

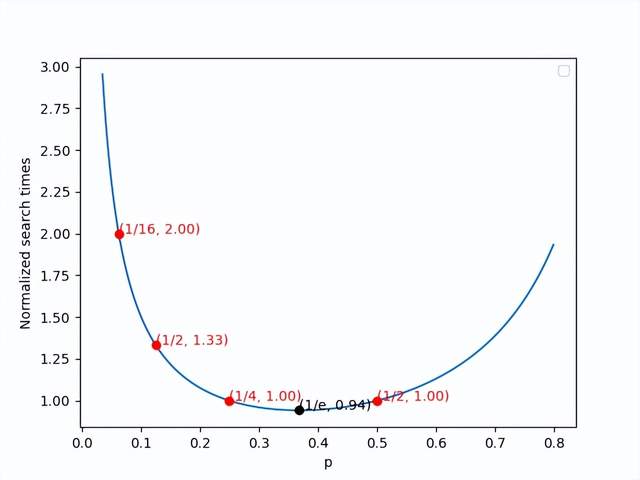
Figure.11 Normalized search times

fast random access

#define SKIP_LIST_KEY_TYPE int
#define SKIP_LIST_VALUE_TYPE int
#define SKIP_LIST_MAX_LEVEL 32
#define SKIP_LIST_P 0.5
struct Node; // forward definition
struct Forward {
struct Node *forward;
int span;
}
struct Node {
SKIP_LIST_KEY_TYPE key;
SKIP_LIST_VALUE_TYPE value;
struct Forward forwards[]; // flexible array member
};
struct SkipList {
struct Node *head;
int level;
int length;
};
struct Node *CreateNode(int level) {
struct Node *node;
assert(level > 0);
node = malloc(sizeof(struct Node) + sizeof(struct Forward) * level);
return node;
}
struct SkipList *CreateSkipList() {
struct SkipList *list;
struct Node *head;
int i;
list = malloc(sizeof(struct SkipList));
head = CreateNode(SKIP_LIST_MAX_LEVEL);
for (i = 0; i < SKIP_LIST_MAX_LEVEL; i++) {
head->forwards[i].forward = NULL;
head->forwards[i].span = 0;
}
list->head = head;
list->level = 1;
return list;
}
Next, you need to modify the insert and delete operations to ensure the data integrity of the span after the jump table is modified.
It should be noted that during the insertion process, indices need to be used to record the position of the last element traversed at each level, so that by doing a simple subtraction operation, the distance between the last element traversed at each level and the newly inserted node can be known span.
struct Node *SkipListInsert(struct SkipList *list, SKIP_LIST_KEY_TYPE key, SKIP_LIST_VALUE_TYPE value) {
struct Node *update[SKIP_LIST_MAX_LEVEL];
struct Node *current;
int indices[SKIP_LIST_MAX_LEVEL];
int i;
int level;
current = list->head;
for (i = list->level - 1; i >= 0; i--) {
if (i == list->level - 1) {
indices[i] = 0;
} else {
indices[i] = indices[i + 1];
}
while (current->forwards[i].forward && current->forwards[i].forward->key < target) {
indices[i] += current->forwards[i].span;
current = current->forwards[i].forward;
}
update[i] = current;
}
current = current->forwards[0].forward;
if (current->key == target) {
current->value = value;
return current;
}
level = SkipListRandomLevel();
if (level > list->level) {
for (i = list->level; i < level; i++) {
indices[i] = 0;
update[i] = list->header;
update[i]->forwards[i].span = list->length;
}
}
current = CreateNode(level);
current->key = key;
current->value = value;
for (i = 0; i < level; i++) {
current->forwards[i].forward = update[i]->forwards[i].forward;
update[i]->forwards[i].forward = current;
current->forwards[i].span = update[i]->forwards[i].span - (indices[0] - indices[i]);
update[i]->forwards[i].span = (indices[0] - indices[i]) + 1;
}
list.length++;
return current;
}
struct Node *SkipListDelete(struct SkipList *list, SKIP_LIST_KEY_TYPE key) {
struct Node *update[SKIP_LIST_MAX_LEVEL];
struct Node *current;
int i;
current = list->head;
for (i = list->level - 1; i >= 0; i--) {
while (current->forwards[i].forward && current->forwards[i].forward->key < key) {
current = current->forwards[i].forward;
}
update[i] = current;
}
current = current->forwards[0].forward;
if (current && current->key == key) {
for (i = 0; i < list->level; i++) {
if (update[i]->forwards[i].forward == current) {
update[i]->forwards[i].forward = current->forwards[i];
update[i]->forwards[i].span += current->forwards[i].span - 1;
} else {
break;
}
}
while (list->level > 1 && list->head->forwards[list->level - 1] == NULL) {
list->level--;
}
}
return current;
}
After fast random access is realized, the interval query function can be realized through simple pointer operations.
- Pugh, W. (1989). A skip list cookbook. Tech. Rep. CS-TR-2286.1, Dept. of Computer Science, Univ. of Maryland, College Park, MD [July 1989]
- Pugh, W. (1989). Skip lists: A probabilistic alternative to balanced trees. Lecture Notes in Computer Science, 437–449. https://doi.org/10.1007/3-540-51542-9_36
- Weiss, MA (1996).Data Structures and Algorithm Analysis in C (2nd Edition)(2nd ed.). Pearson.
- Aragon, Cecilia & Seidel, Raimund. (1989). Randomized Search Trees. 540-545. 10.1109/SFCS.1989.63531.
- Wikipedia contributors. (2022b, November 22).Finger search. Wikipedia. https://en.wikipedia.org/wiki/Finger_search
- Wikipedia contributors. (2022a, October 24).Threaded binary tree. Wikipedia. https://en.wikipedia.org/wiki/Threaded_binary_tree
- Wikipedia contributors. (2023, January 4).Negative binomial distribution. Wikipedia. https://en.wikipedia.org/wiki/Negative_binomial_distribution
- Redis contributors.Redis ordered set implementation. GitHub. https://github.com/redis/redis
- deterministic jump table
- Lock-free concurrency safe skip list
Due to the need for the integrity of the article display, some formula content is uploaded with screenshots, and I hope that the inappropriate typesetting will be forgiven.
#Jump #table #data #structure #algorithm #analysis #Cloud #developers #personal #space #News Fast Delivery