
Author | Wang Yuekai
guide
Having been engaged in the research and development of B-end business systems for many years, it is inevitable to have this kind of thinking: What are the technical challenges of B-end systems? What kind of business architecture is considered a good architecture? Based on the development history of Baidu’s contract advertising business, this article introduces the problems and thinking encountered in the evolution of the advertising platform from a single architecture to a microservice architecture. I hope that through the introduction of this article, everyone can have a more comprehensive understanding of the technical challenges of the B-end system.
The full text is 11,653 words, and the expected reading time is 30 minutes.
1.1 Concept of Contract Advertising
Compared with bidding advertisements, the biggest feature of contract advertising is that the advertising price is pre-agreed, that is, the price is predetermined. Based on such characteristics, the delivery process of contract advertisements can be roughly summarized into four steps: Inquiry -> Order -> Delivery -> Settlement.
Inquiry, sales select the appropriate marketing products according to the customer’s marketing goals, and submit the specific delivery orientation and duration, the system will automatically calculate and output the price of each resource in combination with the sales policy
When placing an order, the customer confirms the resources to be purchased and the specific payment method according to the quotation result in 1, and generates an order after completing the order, and the amount of each order is confirmed
Delivery, after the approval of the order in 2, the system will deliver the advertisement according to the price agreed in advance, and the customer can manage the delivery and creativity through the system during the casting process, and can obtain the delivery data in real time
For settlement, contract advertisements are divided into time-based billing and impression-based billing according to the delivery mode. The frequency of the two billing methods is every day, and finally the full amount of the order is gradually deducted within the delivery cycle. Settlement by day is a guarantee for the rights and interests of the part that has been delivered. After all, there are scenarios for contract advertisements to be changed or even refunded.
Generally speaking, the advertising procurement method of contract advertising is more suitable for brand display advertising, and real-time bidding is more used for performance advertising. Compared with bidding advertisements, contract advertisements are more focused on the business process. Combining the three stages of brand advertising business development, the following introduces the change process of the delivery platform.
1.2 Business Development
The first stage, the period of rapid development of brand advertising business
In 2011, the products in the brand zone began to be sold on a platform, and gradually established a brand launch platform: Kit. During the six years from 2013 to 2018, the brand business developed rapidly, and 10+ product lines such as Ax, Bx, and Cx were born. Although the kit platform serves as a unified entrance for launch, the launch capabilities of each product line are still built independently. their own independent delivery platforms. In this mode, it quickly and flexibly responds to market changes and needs, but at the same time, it also causes the problems of multiple delivery platforms and fragmented business processes.
The second stage is to seek product integration and process unification
In 2019, we began to try to integrate the contract platform and unify the sales process of each product, including the closure and transfer of product lines, integration of launch platforms, unification of accounts, unification of capital pools, and standardized order placement. Gradually implement the construction of a one-stop platform for contract advertising – Apocalypse Platform, truly realize the standardized delivery process of contract advertising, improve the efficiency of large-scale delivery, and support business development. At this stage, the entrances of each advertising platform are gradually converged, and the unified operation entrance has been realized.
The third stage, satisfying complex marketing scenarios, integrated marketing
With the accelerated growth of the overall trend of contract integration sales (combined sales plans of different advertising products selected according to marketing scenarios, that is, multiple types of advertisements can be ordered under the same contract and enjoy corresponding preferential policies), the original non-standard breakpoint The support method can no longer meet the growth of the business, and a platform-based solution is a necessary condition for the scale of integrated sales. Officially launched from Q3 in 2021, Apocalypse Platform is officially positioned as a unified contract product integration sales platform, which can meet the full delivery link service capabilities from simple scenarios to complex marketing scenarios. From a technical perspective, it aims to realize the unification of multi-resource advertising sales scenarios through one platform (Apocalypse), including one process, one set of accounts, one set of capital system, and one set of delivery expressions.
1.3 Architecture Evolution
Corresponding to the above three stages of business development, the technical architecture of the contract platform has also undergone multiple versions of evolution. After condensing, it can be summarized into two categories, the single architecture before 2019 and the microservice architecture later.
monolithic architecture
The single architecture before 2019 (referred to as “1.0 architecture”) is shown in the figure below, which is divided into three layers as a whole. 1) Unified entry layer, providing user rights management functions; 2) Independent construction of various advertising platforms and independent deployment of services ;3) Abstract and deposit the basic tool library to avoid repeated development of each delivery platform.
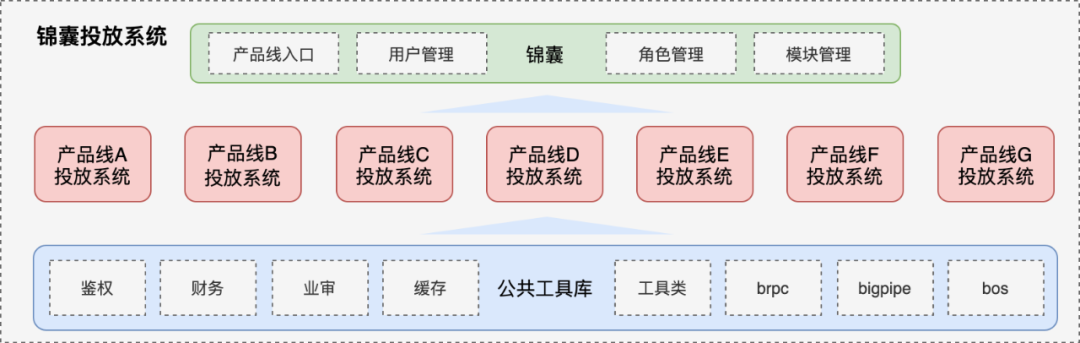 △1.0 chimney structure
△1.0 chimney structure
The essence of brand 1.0 architecture is achimney architecture, Each product line is launched through an independent platform, and development, testing, and launch do not affect each other, and product line dimensions can be isolated, including development specifications and iteration cycles. This structure matched the organizational structure of the brand team at that time, and played an important role in the initial stage of the brutal growth of brand products, successfully incubating some innovative products. However, a big disadvantage of the chimney architecture is “information islands”. With the development of business, each delivery platform diverges and iterates, gradually forming isolated islands one by one. From a technical perspective, the major processes of each platform are similar, but the implementation details are different. What’s more, there are a lot of repetitive construction work, and there is a lot of room for optimization in terms of maintenance costs and human efficiency. From a business perspective, each product is played in its own way, lacking horizontal linkage, not forming a 1+1>2 situation, and lacking planning from an overall perspective.
microservice architecture
In terms of business, the demand for scenario-based marketing and refined services of contract advertising is significant; in terms of team, various contract advertising platforms are deeply integrated, and the boundaries of isolated islands are gradually broken. The original chimney structure has encountered bottlenecks in terms of business complexity, service stability and quality assurance, and R&D efficiency improvement. The biggest goal based on software design: “Design an evolutionary method that conforms to the structural laws of the business, a method that can make the business develop faster and better with the minimum development and maintenance costs』, 19 years later, the contract platform architecture has gradually evolved into a micro-service architecture. Based on domain-driven design, micro-services are divided according to the domain model of contract advertising, and four layers of business front desk, business middle desk, technical components, and infrastructure are built. business architecture. In addition, decoupling various services based on the message mechanism, supplemented by the concept of assembled business processes, disassembles various complicated business processes, abstracts and precipitates the meta features of the system, flexibly constructs a variety of differentiated business solutions, and improves the system “Playability” manages system risk and business complexity from the architectural level (hundred levelDifferent types of sales and delivery scenarios).
Speaking of this, some people may have doubts, is the evolution of microservice architecture necessary for brand business? Is there over-engineering?
Of course, if performance, robustness, portability, modifiability, development cost, time constraints and other factors are not considered, the functions of the system can always be realized with any architecture and any method, and the project can always be developed. Yes, but the development time, future maintenance costs, and ease of function expansion are different. From the posterior point of view (including system availability, scalability, and flexibility), the decision to adopt the microservice architecture is correct, or the advantages far outweigh the disadvantages.
During the evolution of the architecture, many technical challenges were encountered. The following content focuses on several aspects for detailed elaboration.
2.1 Service Architecture
First, look at the microservice architecture of the contract advertising platform as a whole, as shown in the figure below:
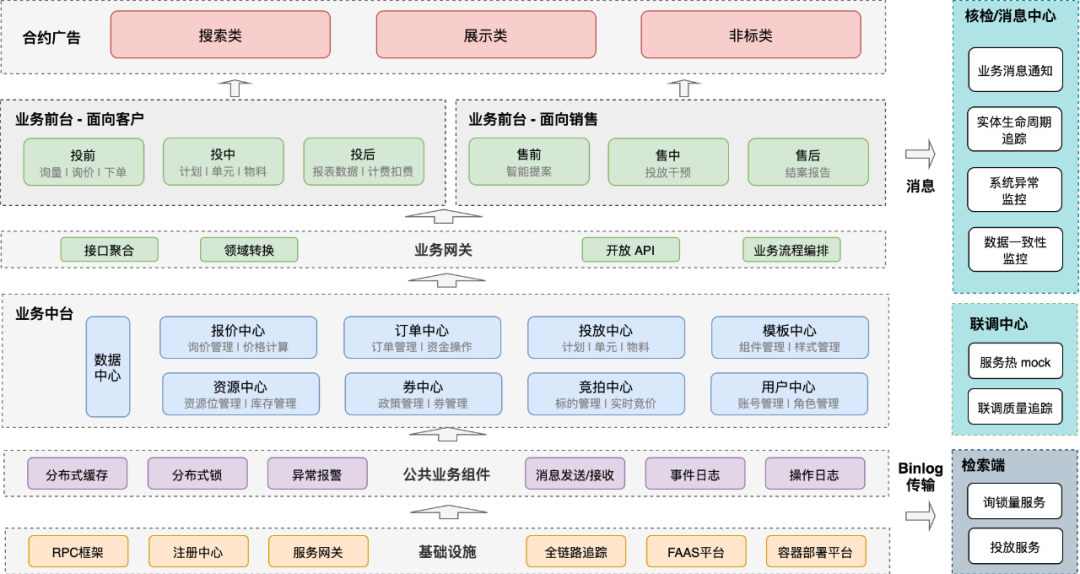
△Microservice Architecture of Contract Advertising Platform
It is divided into four layers in total, business front desk, business middle desk, technical components (PAAS), and infrastructure (IAAS).
- Business front deskis divided into three modules in total, Tianqi platform, operation platform, and business front desk.
Apocalypse Platform: For advertisers, it provides core capabilities such as contract advertising inquiry, resource reservation, resource order, delivery setting, and material production, and supports three major product matrices: product matrix, display matrix, and brand panorama, with up to 300+ advertising resources sell.
Operating platform: For sales and internal operations, help them fine-tune the operation of each stage of advertising sales. At present, the intervention in sales and the construction of operational control capabilities are relatively complete, and the efficiency and safety of operations have been greatly improved in the promotion of the screen and the daily operation of brand advertising. feature, allowing some “non-standard” operations to realize self-service through platform capabilities.
Business front desk: Mainly two functions, 1) abstract and sink the public part of Tianqi platform and operation platform, avoid duplication of business logic and process spread in two modules, reduce development and operation and maintenance costs; 2) for each business platform The public part of the system is pumped up, and unified into this module, such as batch processing, so that the responsibilities of each business center are more pure, and they focus on modeling in their own fields. In addition, the reading and writing logic for cross-multiple middle stations is also implemented in this layer, which plays the role of business process orchestration.
Business centerAccording to the business process and domain knowledge of contract advertising, business services are divided into 9 business centers and 2 technology centers. Each business center is developed around a specific business field, and the business boundary is very clear. It should be noted that the nine business centers are only defined and divided from a business perspective, and it does not mean that each center has only one service. Based on the technical architecture and business responsibilities, each business center can be further divided into multiple modules. For example, the delivery center is further divided into search and adaptation services, material review services, and experiment delivery services. In addition, the upstream and downstream relationships are strictly defined between services (upstream and downstream concepts are defined according to the response data flow direction), downstream services can call upstream services, upstream services are strictly prohibited from calling downstream services, changes in upstream services must affect downstream services through domain events ( Asynchronous) to avoid service cycle dependencies (introduced in the service governance chapter). Therefore, a large number of asynchronous messages are used in the overall system, and the state changes of business entities are regarded as events to drive upstream services. Although the complexity of the testing phase is increased, the order of the relationship between services is effectively guaranteed.
technical componentsAfter the micro-service architecture, the code base of each module is also independent. For some public capabilities, how to make the access of each service low-cost and without threshold, so as to achieve the goal of unifying the business solutions of each module and slow down the corruption of the business architecture and entropy increase. In view of this, the brand team’s business middleware brand-starters was built through the springboot starter, and the implementation details of 30+ modules were successfully converged, making great contributions to system stability and architecture health, including message sending and consumption, Asynchronous event processing, abnormal alarm, distributed lock, hierarchical cache, common tools and auxiliary classes, etc.
infrastructuremainly refers to department-level infrastructure and middle-end, such as micro-service solutions, including RPC framework, registration center, full-link tracking, service gateway, virtualized container deployment, and FAAS.
2.2 Module structure
The previous section introduced the business structure of the contract advertising platform from an overall perspective, and this section introduces the business structure of each middle platform from a micro perspective. Each business center adopts a multi-module code structure, and the specific modules are divided as follows:

The dependencies of each module are as follows:
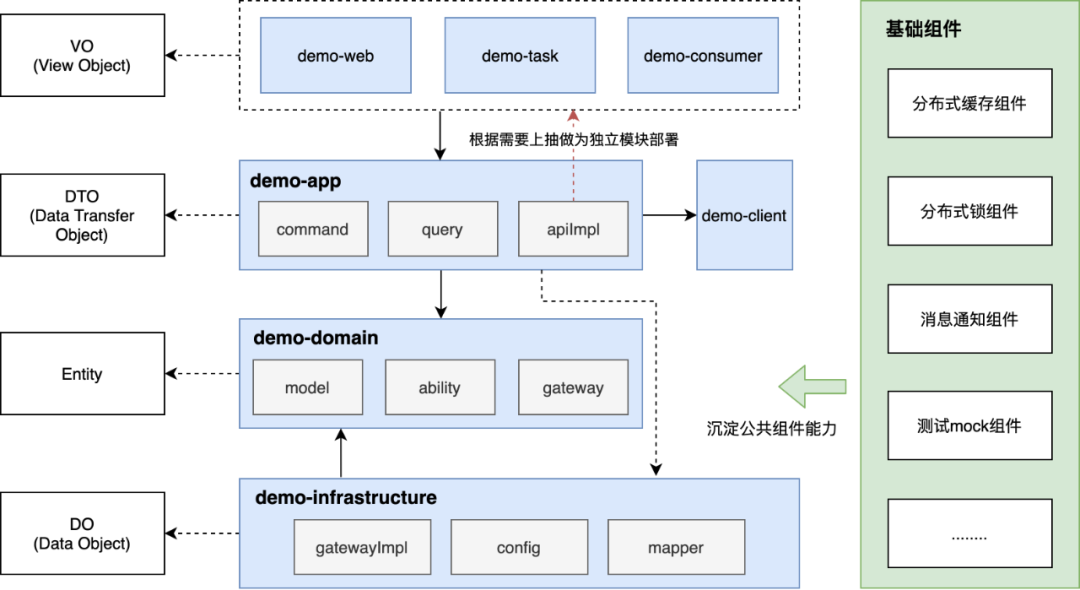
△Modular structure
It is worth noting that:
The dependencies between modules, demo-web, demo-task, and demo-consumer are the top-level modules, which are very thin. The main function of this layer isIndependent publishing and deployment to achieve application-level isolation. The top-level module calls demo-app, and the app module is used as the implementation of the service, storing the implementation classes of each business, mainly divided into command and query (CQRS concept). The demo-app can call the demo-domain, or the infrastructure layer demo-infrastructure. The domain is mainly divided into three parts as the domain layer. The model domain entity can be a congestion model (the concept of DDD); the ability domain capability is the domain external Exposed service capabilities; gateway Domain gateway, mainly interface definition, the interface here can be roughly understood as a kind of SPI, that is, the interface handed over to the infrastructure layer to implement.
demo-client is the API that the service exposes to the outside world, and the implementation of the API is stored in the demo-app module. For operation and maintenance considerations, or the design of read-write separation, APIs that need to be independently deployed can be easily extracted from the app module to the top layer, and released and deployed as independent modules in a pipeline.Enable isolated deployment of services while gaining the benefits of sharing the same code base.
The aforementioned domain and infrastructure layersDependency Inversion, is a very useful design, which further decouples the implementation of fetch logic. The domain layer relies on the interface and is not aware of the specific implementation. For example, the interface getByById is defined in CustomerGateway, which requires the implementation class of the infrastructure to define how to obtain consumer entity information through the consumer Id, while the infrastructure layer can implement any data source logic, for example, from MySQL Get it, get it from Redis, or get it from an external API, etc.
The subcontracting strategy of domains and functions, the subcontracting strategy of each module follows the guidelines:First subcontract according to field, and then subcontract according to function, one of the advantages of doing so is that it can control the rot within the business domain. For example, two domains, customer and order, are first divided into two packages of customer and order under the domain module, and then divided into functions according to model, ability, and gateway. Assuming that customer and order are developed in parallel by two back-end developers, and the two people have different naming habits for dto and util folders, then they will only rot under their respective business packages, and will not store dto, util, config and other files folders together, it is very easy to cause file conflicts.
Through the above division of application architecture, the sub-modules and subcontracting strategies of each business center are unified, the learning and hands-on costs of each module are successfully reduced, and the corruption of business architecture and module codes is better controlled. At the same time, through the division of top-level modules, the ability to deploy multiple applications in the same code base is flexibly realized, and web services, timing tasks, message consumption, and rpc services are isolated from the physical level, so that the services have the ability to flexibly expand on demand and further improve service stability. sex.
2.3 Service Governance
After the microservice architecture, the interaction between services is carried out through the network instead of the memory method of the single era, so the system as a whole will become more fragile, and service governance is to solve such problems. Conventional service governance has four tricks: first, the timeout period for service calls must be set; second, the logic of retrying must be considered; third, the logic of fusing must be considered, so as not to be dragged down by downstream; fourth, it must be limited The logic of flow, don’t be killed by the upstream. That is, timeout, retry, circuit breaker and current limit. Yes, these four axes are indeed common means in service governance, but in my opinion, service governance is not limited to this. Let’s start with the end, what is the ultimate goal of service governance? I think there are mainly 3 aspects:Service availability, system observability, and architecture anti-corrosion.
availability
The construction of service availability includes system performance optimization, service self-healing and self-inspection capacity building.
service performance
1. Microservice framework upgrade
The overall service RPC framework is migrated to the department’s latest cloud-native solution gravity+starlight, replacing the original zookeeper+stargate. Significant improvements in service performance and governance:
Improved communication performance: starlight uses a new version of the network communication library and a more flexible thread pool model.Improve communication interaction performance by 2 times
Enhanced stability: starlight builds a more efficient and stable registration center based on gravity, and can customize non-destructive upgrades and remove abnormal instances. Easy empowerment reaches 99.99%+ stability.
Cross-language capability: starlight uses the more reasonably designed brpc protocol as the main protocol, which can communicate with brpc services such as C++ Go across languages. Reduce the cost of cross-language communication learning.
Cloud-native governance: starlight+gravity supports more cloud-native governance capabilities, accessing a unified control center to enhance controllability and achieve grayscale release.
Speed up log specification troubleshooting: standardized logs.Second-level positioning timeout problem, serialization failure problem
During the migration process, Gravity and ZK bidirectionally synchronize service registration information to achieve smooth and senseless migration of business.
2. Deep optimization of system performance
A comprehensive performance inventory and optimization of the contract advertising system has been carried out, and the overall performance has been improved by 2 times. It is summarized as the following 7 optimization points:
Unitization, splitting and thinning a single service (the top-level module mentioned in the module structure chapter separates timing tasks, message consumption and web services), realizes resource isolation, and reduces time-consuming waiting for connection acquisition
Network transmission, unified team service deployment to the northern computer room, reducing the noise level by 60%
Cyclic IO, IO includes remote service calls and database operations, greatly reducing time-consuming through batch transformation and multi-threaded concurrency
Multi-level cache, build a second-level cache through local + redis, greatly reducing the time-consuming reading interface
Asynchronous, for time-consuming write operations, use the eventlog component to achieve asynchronous + automatic retry (will be expanded in detail in the next section), such as material submission for review, batch creation and delivery, etc.
Slow SQL, based on business query scenarios, optimize data table index definition
Interface splitting, joint front-end, interface splitting for time-consuming data of non-backbone processes, to achieve non-blocking requests
Service self-healing and self-checking
In order to better guarantee the availability of the system, the service needs to have self-healing and self-checking capabilities. The service self-healing capability is mainly realized through idempotent processing + event persistence + logic retry. Through the construction of the self-healing capability, the IO communication instability problem caused by the upgrade of the microservice architecture can be greatly reduced, and at the same time, the system has no impact on performance and External services with poor stability have better tolerance, effectively improving the overall availability of the system. The self-healing ability of the system mainly solves “sporadic” technical problems, such as remote call failures caused by network jitter, optimistic lock conflicts caused by transaction concurrency, etc. It is powerless to solve problems such as code bugs, business logic errors, and data inconsistencies. Therefore, in addition to the self-healing ability, the service also needs to have the self-inspection ability, which can automatically detect errors and notify the corresponding personnel in time for processing.
The idempotent processing of services is briefly mentioned here without too much expansion. There are mainly several solutions:
The unique key of the database realizes the idempotence of adding and deleting operations through the constraints of the database.
Optimistic locking of the database, by adding an additional field (version number) to achieve idempotent update operations.
Anti-heavy token token, the caller first requests a global ID as a token from the backend when calling the interface, and this token is included in subsequent requests (it is recommended to put it in Headers), which can solve the problem of continuous clicking or calling by the client Applicable to add, update and delete operations
The unique serial number is passed downstream. The difference from 3 is that this unique serial number is generated by the caller. The generation method can be a global ID with no business meaning, or an ID with business meaning, such as an order line ID.The service party performs existence and non-existence operations through this ID record (combined with redis to realize the operation record), which is suitable for adding, updating and deleting operations
Self-healing ability – eventlog basic component
Use the springboot-starter mechanism to precipitate eventlog basic components, allowing business parties to access at low cost, and enabling services to have self-healing capabilities. The overall structure diagram of the components is as follows:
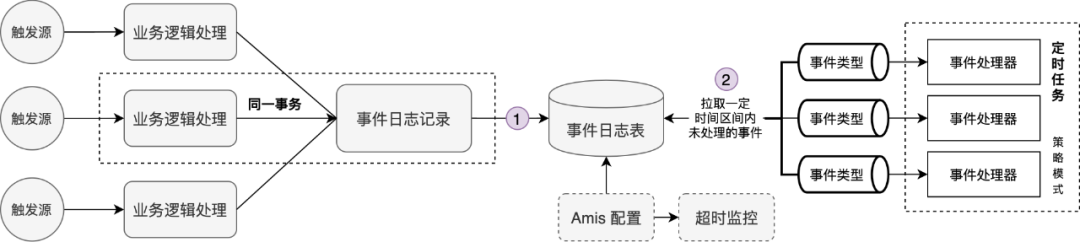
△eventlog basic components
Step 1 is a synchronous persistent event, which is realized by calling a ready-made method after the business party introduces components; Step 2 is an asynchronous consumption and processing event. The overall processing process adopts the template mode + strategy mode, and the business arrangement of the processing process is realized through the template mode, and the event processing Extension points are set at the front, middle, and rear, taking into account the access cost and expansion flexibility of business modules. The event processing adopts the policy mode, and the event type is used as a policy route to realize mutual isolation and high scalability of various event processing. In addition, through visual configuration (amis configuration, i.e. Aispeed, a low-code front-end page building platform), the event log table is uniformly monitored, and operations such as alarming and cleaning are performed on overtime-processed events.
The event log entity model adopts the secondary model of event_type + biz_code. event_type uniquely identifies a type of event and is the strategic routing key during event processing. biz_code is customized by the business side to uniquely identify a certain type of entity. attach is an extension field, which can be customized by the business side. Attach should not be too large. If it is too large, it is recommended to check the business data after biz_code.
Self-inspection capability- Nuclear Inspection Center
The self-inspection capability of the service is mainly realized through the verification center. The function of the verification center is divided into two parts, verification task + message center. The verification task checks and verifies the data according to the business scenario, and solves the data inconsistency caused by the distributed transaction after the micro-service architecture. The center notifies the corresponding personnel of the abnormality. At the same time, in the face of a large amount of alarm information (system errors, data consistency, business correctness, etc.), the message center, as a unified management terminal, provides alarms grouped by scene, historical alarm information query, alarm priority setting, error Functions such as thermal alarm shielding, alarm group entry and group thermal modification, etc., improve the effectiveness of monitoring and processing efficiency.
The overall module diagram of the inspection center is as follows:
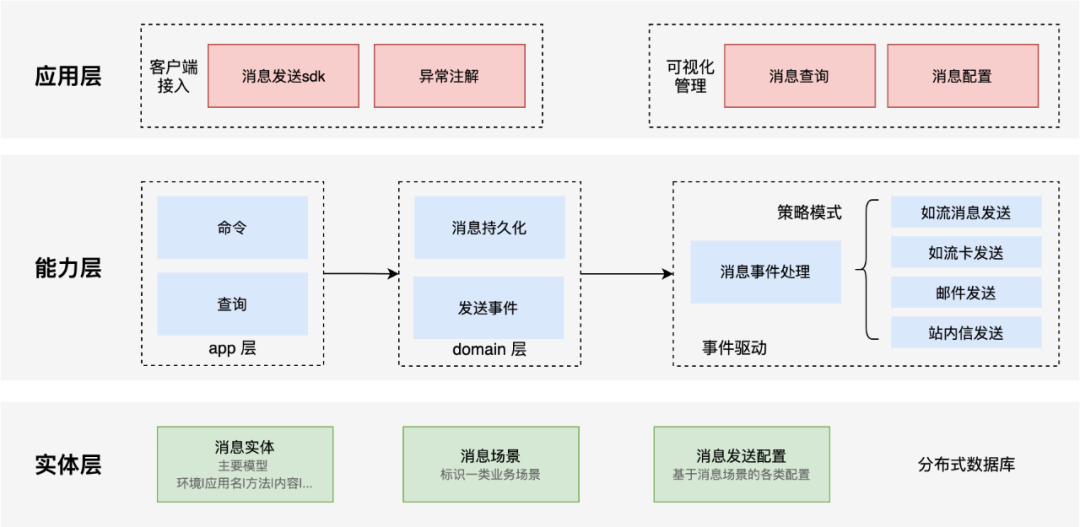
△Module Diagram of Nuclear Inspection Center
The application layer has two main functions, client access and visual management.
Client access, for the springboot application, is the same as the eventlog component. By introducing the starter, the notification of the alarm message can be realized at low cost (declarative annotation and imperative sdk).
Visual management, through the message center console, collects the scattered inspection tasks, greatly improving the efficiency of schedule maintenance. At the same time, historical messages can be queried, so that the messages can be traced back and tracked.
The capability layer corresponds to the server of the inspection center. The overall module structure follows the COLA mentioned above, and uses CQRS and event-driven design concepts to improve the usability of the module. In the processing module of the message sending event, the strategy mode is used to realize various types of message sending, which greatly improves the scalability of the module and follows the principle of opening and closing.
In the physical layer, model design and database selection are carried out according to the billion-level data volume. In entity design, abstracting the business concept of message scenarios better aggregates a class of messages with common characteristics. The “common characteristics” are completely defined by the business side, which balances business flexibility and message manageability. In terms of database selection, the department’s open source solution BaikalDB (a distributed and scalable HTAP storage system with a spanner-like architecture that supports random real-time reading and writing of PB-level structured data) is adopted.
Observable
System observability is also a very important goal of service governance. When it comes to the observability of services, what everyone tends to think of are: microservice call relationship (topology diagram presentation), interface performance (various quantile value indicators, performance optimization tools), system exceptions (various monitoring configurations), Resource utilization, log link tracking (online investigation is essential), etc. This part is mainly implemented by the department’s microservice solution Jarvis platform, so I won’t introduce too much here. The main service I want to introduce here is observable It mainly refers to the upper layer business application.
Enterprise-level micro-service solution Jarvis is an application hosting platform for complex business systems developed by the basic technology team of the business platform department, providing high-availability and distributed micro-service architecture solutions for business applications. Jarvis provides a series of powerful functions, fully utilizes Baidu’s resource virtualization capabilities, and provides functions such as distributed service framework, service governance, unified configuration management, distributed link tracking, capacity planning, high availability and data-based operations.
As mentioned earlier, the overall business link of contract advertising is relatively long. After pre-sales inquiry -> order -> contract approval -> material production -> delivery -> billing, each link may become an advertisement If there is a problem with the stuck point of delivery, such as process blockage, how can we quickly locate the problem, or even perceive the problem in advance, so that the entire process is transparent and observable?
The overall idea is to center on the business entity and record the changes in the entire life cycle of the entity. When a certain stage (entity status) stays longer than expected, there may be potential abnormalities. Through the service kanban and message center, the corresponding operation is notified in time Follow up processing. By tracking the life cycle of business entities, the observability of system business processes is realized, and data analysis basis is provided for subsequent process optimization and business efficiency improvement.
The tracking implementation scheme of the business entity life cycle is mainly as follows:

△Business entity life cycle tracking
In summary, there are three options:
By subscribing to mysql binlong, the core status field of the business entity is monitored (the corresponding department has an existing solution WATT). Once the field changes, an incremental message will be triggered, which will be persisted after consumption by the server, and then presented externally in the form of a service kanban.The advantage of this method is that there is no intrusion into the business module, and the disadvantage is that it depends on the database design of the business module. In addition, the life cycle of some entities is not necessarily reflected in the field changes of the data table, and cannot be perceived by subscribing to binglog
Realize the tracking of the entire life cycle of entities through log printing -> collection -> analysis.The advantage of this approach is that Baidu already has a complete set of ready-made solutions that can be reused directly; the disadvantage is that it needs to intrude into the business code and print logs according to the specifications. At the same time, the configuration threshold for log collection and analysis is relatively high, and debugging is difficult, and it is not easy to get started.
Provide tracking sdk for tracking the life cycle of entities, and bury points where monitoring is required.The advantage of this method is that it is very flexible and can realize any tracking requirements; the disadvantage is that it invades the business code and requires the business module to call it explicitly
In the end, we adopted 1 and 3. The tracking of business entities is mainly realized through solution 3, and some additional auxiliary information is synchronized through solution 1.
Corrosion
The law of entropy increase mentioned by many scientists very well reveals the essence of natural phenomena: any isolated system, in the absence of external forces, its total disorder (entropy) will continue to increase. Of course, the same is true for software systems. As the functions of software systems continue to increase, the degree of confusion in the system is also increasing. In order to slow down the rate at which software systems become chaotic, external forces must be applied to them. So where can we start with the “external force” here?
Analyze the modification frequency of each application, which applications are frequently modified, and which applications are relatively stable. For applications that are frequently modified, the business requirements that cause modification are the same. So whether it is unreasonable for these services that are highly likely to be bound together to be modified to be split into different applications is worthy of further discussion. If an application needs to be upgraded no matter what the requirements are, is the application small enough? Does it need to be further dismantled, separated from the changed and unchanged, and separated and precipitated?
Regularly observe the invocation of each service, including the number, performance and topology. Are there some redundant services that can be cleaned up? Are there some service performances that are deteriorating and need to be optimized in time? Are there situations where there are repeated calls in some business processes? If there is, a plan needs to be formulated for governance, otherwise historical debt will be established and the business structure will gradually rot.
It is necessary to scan and check the application code regularly, including whether the repeated logic is spread across multiple applications, whether there is non-standard code logic (each team summarizes and precipitates according to practice, such as the use of enumeration classes, IO loop calls, etc.), whether there is redundancy The rest of the code needs to be cleaned up, whether the module structure and subcontracting strategy conform to the specification
Periodic CR application codes, whether there is cross-domain logic, such as the quotation center processing the logic of the order center (the logic of the non-quotation domain), resulting in blurred division boundaries of microservices
The work of anti-corrosion is actually very important, and it is still in the initial stage of exploration. It needs to further integrate business reality and accumulate best practices. Here we first take microservice circular dependency governance as an example to give a brief introduction.
When the circular dependency in the microservice forms a closed loop, it will cause two main types of hazards:
The strong coupling between services makes it difficult for each service to be deployed independently, which violates the original design intention of microservices “autonomy and isolation”. Eventually, the microservice architecture will gradually evolve into a “distributed large monomer”, which loses the significance of the evolution of the microservice architecture.
Circular dependencies may lead to some circular calls or concurrency problems, causing some complex and difficult-to-locate problems. The following uses the user center and order center as examples to illustrate
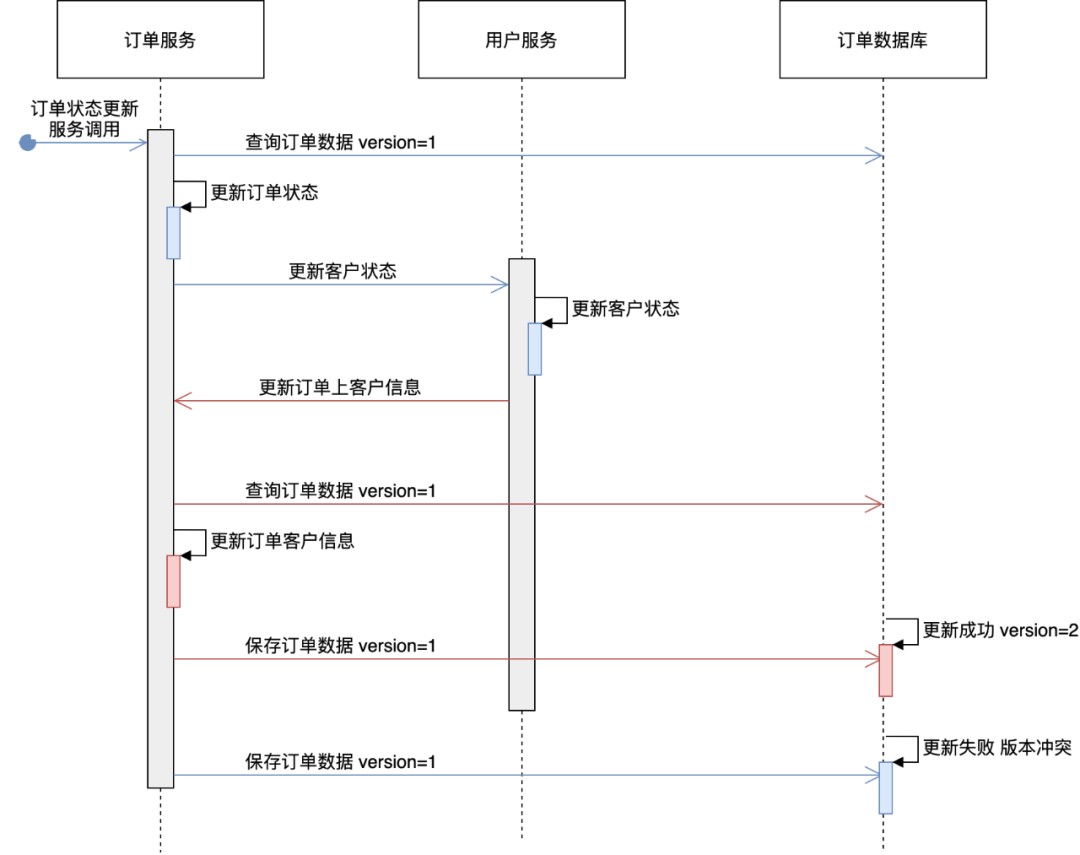
△ Concurrency problems caused by circular dependencies
In the above figure, there are two services, order and user center. The blue arrow indicates the service provided by the order center to update the order status. The user service will be called to update the customer status, marking that the customer has placed an order record. The red arrow indicates that the user center calls the order center, and the user service calls the order service in turn after marking the customer status to persist the customer information on the order. The above calls form a closed loop, which will eventually cause version conflicts in the order database, resulting in update failure. So how to avoid this circular dependency? To summarize the following guidelines:
Clarify service boundaries and positioning, and divide upstream and downstream services. Downstream services can call upstream services, but upstream services cannot rely on downstream services. If you want to communicate, use domain events, such as message notifications.
The data should not be too redundant, and try to associate it through the data id (a property that can uniquely represent the data and remain unchanged), that is, only references are stored.
If there are functions that must be completed by synchronously calling downstream services through upstream services, it is necessary to reflect on whether upstream services lack corresponding business domains. If not, you can use the business front desk to realize the call arrangement of each service, or there may be unreasonable splitting of microservices. This scenario needs to be re-planned to split a more upstream service for calling.
Going back to the actual example just now, the governance solution is to adopt the transformation method of domain events. The order service is a downstream service, and the user service is an upstream service. The user service updates the order customer information from the synchronous call method to the message notification, and does not perceive the specific subscriber. , to achieve decoupling.
2.4 Service iteration
After the transformation of the microservice architecture, the iterative method of the original monolithic architecture is no longer applicable. Let’s look at a practical example:
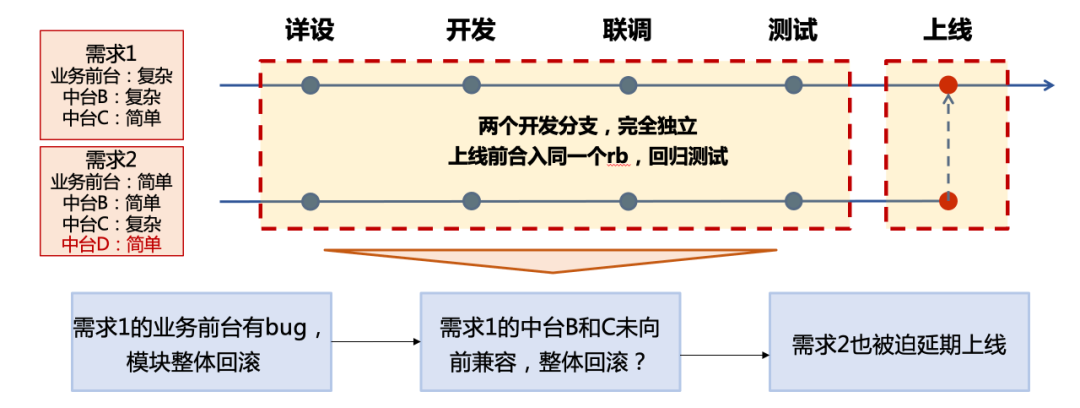
As can be seen from the above examples, after the microservice architecture, a business requirement will involve multiple modules with different complexity. If each upgrade of the middle platform service cannot be forward compatible, it will inevitably lead to discrepancies between requirements. Coupling, once the number of parallel development branches increases, the overall rollback probability caused by the coupling between modules will increase exponentially. Still the above example, if middle station B in requirement 1 has a bug and needs to be rolled back, will all modules in requirement 2 have to be rolled back, including middle station D, even if its changes are very small.
In summary, there are two main reasons for the above situation:
The perspective of iterative upgrading is only the demand dimension, and the middle-end service is separated, lacking another perspective that focuses on the middle-end
Insufficient automated testing capabilities, excessive reliance on black-box testing will lead to post-risk
For these two problems, our solution mainly has three directions:
Standardize the demand iteration process and strengthen the virtual team centered on the middle office.
From requirements review, technical detailed design, development, joint debugging, testing to launch, formulate detailed full-process specifications to ensure the orderly operation of the team. At the same time, it emphasizes the autonomy of each middle station, iterative upgrade must be forward compatible, and the rollback of dependent modules does not affect its own online plan, repeatedly emphasizing the design concept of fault tolerance, compatibility, and evolution.
Strengthen automated testing capabilities to achieve automatic quasi-exit standards. Automated testing capabilities include unit testing and integration testing of each module. The single test of the module is integrated into the pipeline through the plug-in, and the integration of the code that does not reach the coverage rate is prohibited. In special cases, the reason can be explained and the person in charge of the module can be exempted. The integration test starts from the business front desk and is gradually built according to the priority of the business scenario. The triggering method is divided into daily routine tasks and manual triggering during regression testing.
Provide service mock capability, decoupling dependencies on other services in appropriate scenarios. Land the joint debugging center, realize the dynamic mocking capability of the service level, and allow business modules to be connected at low cost through the starter method. The overall design is divided into two parts, the client end and the server end, as shown in the figure below:
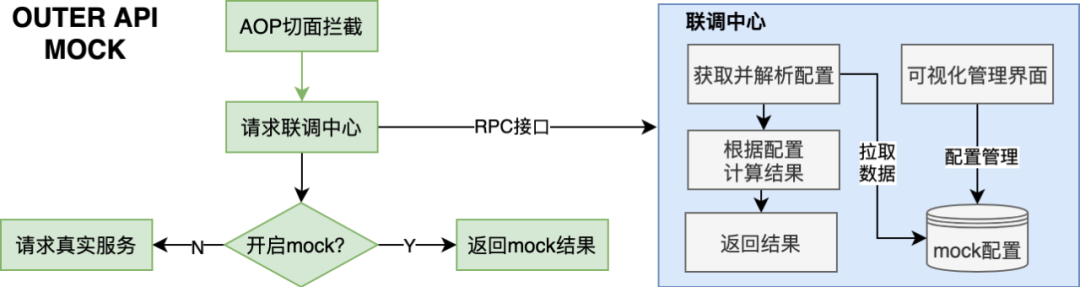
△mock center
Among them, the visual mock rule configuration on the server side supports dynamic rules, and for some requirements that cannot be described by dynamic rules, customized logic can also be realized through low-cost code development.
Ultimately, it is expected that each middle-end service can achieve “autonomy and isolation”, thereby decoupling the online of each demand point, as shown in the following figure:
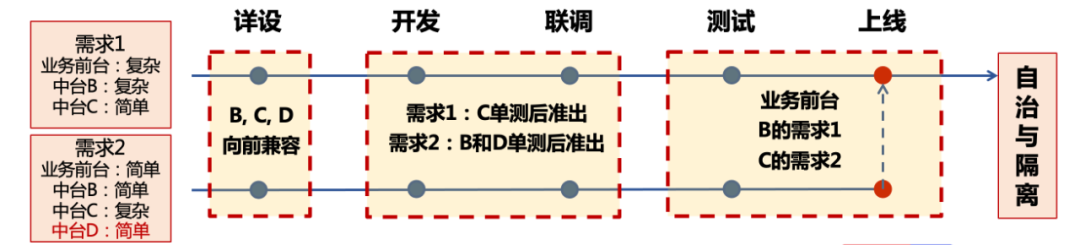
It can be seen that the online granularity has been refined from the demand dimension to the mid-stage fetaure, which has reduced the overall delivery risk exponentially. Of course, for microservice architecture systems, how to achieve efficient joint debugging and testing is still a direction that is constantly being explored.
This article mainly introduces some best practices in the evolution of contract advertising microservice architecture, and makes a brief summary.
service split: Starting from the actual business, based on the concept of domain-driven model, establish a suitable business model. This part must go deep into the details of the business, understand the principles of business operation, and abstract the essence of the business. Through reasonable service splitting, complex business problems can be solved more efficiently. If the seven business platforms are compared to orthogonal coordinate axes, then the original low-dimensional complex problems (single architecture) can be projected into high-dimensional ones (microservices) Architecture), there is a high probability that it will become less complicated; in addition, for the problem of essential business complexity, through service splitting, the complexity can be well isolated to the corresponding domain services, so as to better manage the complexity and prevent spillover.
modular structure: Learn from the COLA architecture and combine the actual situation to formulate specifications, which include a variety of design concepts: DDD, event-driven mode, CQRS mode, and dependency inversion. Compared with service splitting, the module structure formulates the code organization of each microservice from a micro perspective to slow down the rate of corruption.
Service Governance: It summarizes some experience and best practices in three aspects: system performance, business observability, and anti-corrosion. In my opinion, a good business architecture can well manage and control business complexity and identify changes in the business. ” and “unchanged”. Therefore, it is very important to regularly sort out and analyze the upgrade frequency and call relationship of each service.
service iteration: The iteration of services and architecture needs to be smooth and orderly, to be fault-tolerant, compatible, and evolutionary, and to avoid a large number of application transformations. At the same time, each microservice must achieve autonomy and isolation, reduce mutual coupling, and ensure that each service can “die” and “rebirth” smoothly during the evolution of the architecture, just like biological evolution. (The domain event method mentioned many times in this article is an effective means to reduce service coupling)
So back to the two questions at the beginning of this article, I think the biggest technical challenge of the B-end system isGovernance of business complexity, through appropriate technology selection, while enabling business, it can well manage technology and business complexity.A good business architecture standard in my mind isImprove efficiencythe efficiency here includes delivery efficiency, operation and maintenance efficiency, and evolution efficiency.
Finally, I would like to say: there is no perfect business architecture, a good architecture is one that fits the actual business, and a good business architecture must evolve in combination with the actual business.
————END————
recommended reading:
The application of AI technology in the transformation of risk-based testing mode
Summary of Go language hiding experience
PaddleBox: Baidu’s GPU-based ultra-large-scale discrete DNN model training solution
Talk about how machines “write” good advertising copy?
Baidu engineers teach you how to play design mode (adapter mode)
Baidu search service delivery unattended practice and exploration
#Evolution #Practice #Contract #Advertising #Platform #Architecture #Baidu #Geek #Personal #Space #News Fast Delivery