In the actual business of NetEase Media’s big data, there are a large number of quasi-real-time computing demand scenarios, and the business side’s requirements for the effectiveness of data are generally at the minute level; in this scenario, the traditional offline data warehouse solution cannot meet the user’s practicality. requirements, and the use of full-link real-time computing solutions will bring high resource occupation.
Based on the research on the open source data lake solution, we noticed the Arctic data lake solution based on Apache Iceberg open sourced by NetEase Shufan. Arctic can relatively well support and serve the mixed use of streams and batches, and its open overlay architecture can help us transition and upgrade Hive to data lakes very smoothly. , the cost of transforming the existing business through Arctic is low, so we are going to introduce Arctic to try to solve the pain points in the push business scenario.
1 Project Background
Taking the media push real-time data warehouse as an example, news push has high uncertainty in factors such as region, time, frequency, etc., and it is very prone to occasional traffic peaks, especially when there are sudden social hot news. If the full-link real-time computing solution is used for processing, more resource buffers need to be reserved to deal with it.
Due to the uncertainty of the push timing, the data indicators of the push business are generally not incremental, but are mainly based on various cumulative indicators from the current day to the present. The calculation window usually ranges from fifteen minutes to half an hour. The dimensions distinguish the sending type, content classification, number of votes sent, sending manufacturer, first activation method, user activity, AB experiment, etc., with the characteristics of large traffic fluctuation and various data calibers.
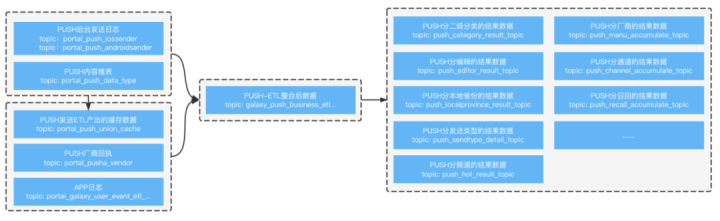
In the previous full-link Flink real-time computing solution, the following problems were mainly encountered:
(1) High resource occupation cost
In order to cope with traffic peaks, it is necessary to reserve high resources for real-time task allocation, and multiple aggregation tasks need to consume the same upstream data, which has the problem of read amplification. The real-time computing process related to push accounts for 18+% of the total real-time tasks, and the resource usage accounts for nearly 25% of the total real-time resource usage.
(2) Decreased task stability due to large state
When performing window calculations in the push business scenario, large traffic will bring about the problem of large state, and the maintenance of large state will easily affect the stability of the task while causing resource expenditure.
(3) It is difficult to repair data in time when the task is abnormal
When an abnormality occurs in a real-time task, it is slow and complicated to trace back the data in real-time; however, to correct it in an offline process, it will bring double labor and storage costs.
2 Project ideas and plans
2.1 Project idea
Through our research on the data lake, we expect to use the characteristics of real-time data entry into the lake, and use Spark and other offline resources to complete the calculation, so as to meet the needs of real-time computing scenarios in the business at a lower cost. We use the push business scenario as a pilot to explore and implement the solution, and then gradually extend the solution to more similar business scenarios.
Based on the research on the open source data lake solution, we noticed the Arctic data lake solution based on Apache Iceberg open sourced by NetEase Shufan. Arctic can relatively well support and serve the mixed use of streams and batches, and its open overlay architecture can help us transition and upgrade Hive to data lakes very smoothly. , the cost of transforming the existing business through Arctic is low, so we are going to introduce Arctic to try to solve the pain points in the push business scenario.
Arctic is a streaming lake warehouse system open sourced by NetEase Shufan, which adds more real-time scene capabilities on top of Iceberg and Hive. Through Arctic, users can implement more optimized CDC, streaming update, OLAP and other functions on Flink, Spark, Trino, Impala and other engines.
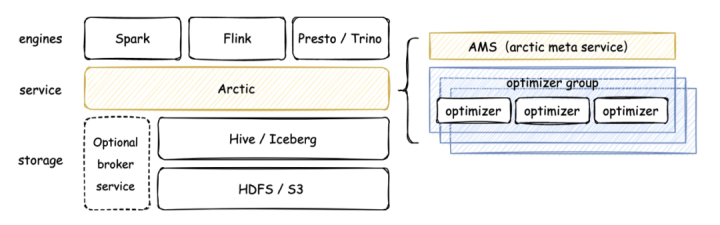
To realize the transformation of the data lake in the push business scenario, you only need to use the Flink Connector provided by Arctic to quickly realize the real-time entry of the push detailed data into the lake.
At this point, the key point that we need to pay attention to is that the data output needs to meet the minute-level business requirements. The data output delay consists of two parts:
- The data ready delay depends on the Commit interval of the Flink real-time task, usually at the minute level;
- The time-consuming of data calculation depends on the calculation engine and business logic: data output delay = data ready delay + data calculation time
2.2 Solutions
2.2.1 Real-time data entry into the lake
Arctic is compatible with existing storage media (such as HDFS) and table structures (such as Hive, Iceberg), and provides a transparent stream-batch integrated table service on top. The storage structure is mainly divided into two parts: Basestore and Changestore:
(1) The stock data of the table is stored in the Basestore. It is usually written for the first time by engines such as Spark/Flink, and then the data in the Changestore is converted and written through an automatic structure optimization process.
(2) Changestore stores the most recent change data on the table. Changestore stores the most recent change data on the table. It is usually written in real-time by Apache Flink tasks and used for quasi-real-time streaming consumption by downstream Flink tasks. At the same time, it can be directly calculated in batches or combined with the data in Basestore to provide minute-level delay batch query capability through Merge-On-Read (hereinafter referred to as MOR) query method.
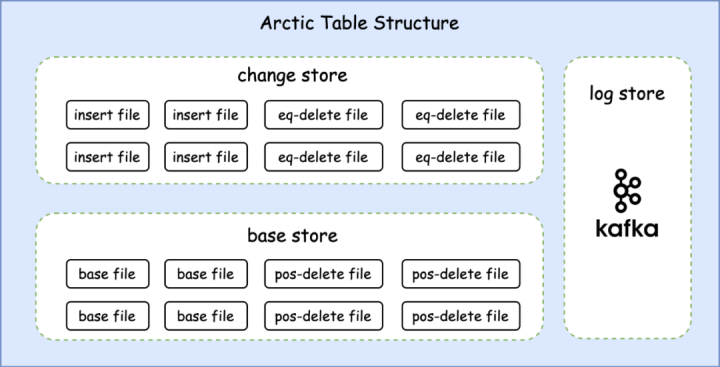
The Arctic table supports streaming writing of real-time data. In order to ensure the validity of the data during the data writing process, the writing side needs to submit data frequently, but a large number of small files will be generated, and the backlog of small files will affect on the one hand. Data query performance, on the other hand, will also put pressure on the file system. In this regard, Arctic supports row-level updates based on primary keys, and provides Optimizer for data update and automatic structure optimization to help users solve problems such as small files, read amplification, and write amplification that are common in data lakes.
Taking the media push data warehouse scenario as an example, detailed data such as push sending, delivery, click, and display needs to be written to Arctic in real time through Flink jobs. Since the upstream has already done ETL cleaning, at this stage, you only need to use FlinkSQL to conveniently write the upstream data to the Changestore. Changestore contains an insert file for storing inserted data and an equality delete file for storing deleted data. The updated data will be split into items before and after the update, which are stored in the delete file and the insert file respectively.
Specifically, for a scenario with a primary key, the insert/update_after message will be written to the insert file of Changestore, and the delete/update_before message will be written to the delete file of Arctic. When optimizing, it will first read the delete file into memory to form a delete map, the key of the map is the primary key of the record, and the value is record_lsn. Then read the insert files in Basestore and Changestore, and compare the record_lsn of the row with the same primary key. If the record_lsn in the insert record is smaller than the record_lsn of the same primary key in the deletemap, it is considered that this record has been deleted and will not be appended. into the base; otherwise, the data is written to a new file, and finally row-level updates are achieved.
2.2.2 Lake water level perception
Traditional offline computing needs a trigger mechanism in scheduling, which is generally handled by the job scheduling system according to the dependencies between tasks. When all the upstream tasks are successful, the downstream tasks are automatically activated. However, in the scenario of entering the lake in real time, downstream tasks lack a way to perceive whether the data is ready. Taking the push scenario as an example, the indicators that need to be output are mainly to calculate the various statistical values accumulated on the day according to the specified time granularity. The buffering time is required to ensure that the data is ready, or there is a possibility of data leakage. After all, the traffic changes in the push scene are very fluctuating.
The media big data team and Arctic team draw on the processing mechanism of Flink Watermark and the solution discussed by the Iceberg community, write the Watermark information into the metadata file of the Iceberg table, and then expose it by Arctic through the message queue or API, so as to achieve downstream tasks Active sensing reduces startup latency as much as possible. The specific plans are as follows:
(1) Arctic meter water level perception
Currently, only the scenario written by Flink is considered, and the business defines event time and watermark in the source of Flink. ArcticSinkConnector contains two operators, one is the multi-concurrent ArcticWriter responsible for writing files, and the other is the single-concurrent ArcticFileCommitter responsible for submitting files. When performing checkpoint, ArcticFileCommitter operator will take the smallest watermark after watermark alignment. A new AMS Transaction similar to the Iceberg transaction will be created. In this transaction, in addition to AppendFiles to Iceberg, the TransactionID and Watermark are reported to AMS through the thrift interface of AMS.

(2) Hive meter water level perception
The data visible in the Hive table is the data after Optimize. Optimize is scheduled by AMS. The Flink task abnormally executes the read-write merge of the file, and reports the Metric to AMS. AMS will commit the result of this Optimize execution. AMS naturally Knowing which Transaction the Optimize has advanced to this time, and the AMS itself also stores the Watermark corresponding to the Transaction, you can also know where the Hive table water level has advanced.
2.2.3 Data Lake Query
Arctic provides Connector support for computing engines such as Spark/Flink/Trino/Impala. By using the Arctic data source, each computing engine can read files that have been committed in real time, and the interval between commits is generally at the minute level according to business requirements. The following uses the push business as an example to introduce query solutions and corresponding costs in several scenarios:
(1) Arctic + Trino/Impala satisfies second-level OLAP query
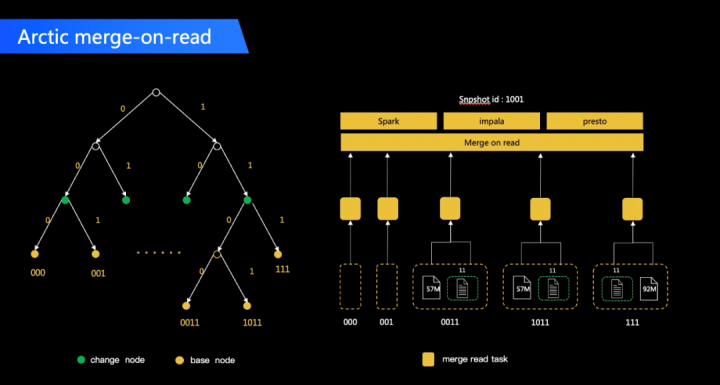
In OLAP scenarios, users generally pay more attention to the time-consuming computation, and are relatively insensitive to data readiness. For Arctic tables with small and medium-sized data or simpler queries, OLAP query through Trino/Impala is a relatively efficient solution, which can basically achieve second-level MOR query time. In terms of cost, it is necessary to build a Trino/Impala cluster. If the team is already using it, reuse can be considered according to the load situation.

Arctic released its own benchmark data at the open source conference. In the scenario of continuous streaming ingestion of database CDC, comparing the OLAP benchmark performance of each data lake format, the overall performance of Arctic with Optimize is better than Hudi, which is mainly benefited from There is a set of efficient file index Arctic Tree in Arctic, which can achieve more fine-grained and accurate merge in MOR scenarios. For a detailed comparison report, please refer to: https://arctic.netease.com/ch/benchmark/.
(2) Arctic + Spark meets minute-level pre-aggregation queries
For the scenario of providing downstream data report display, it is generally necessary to go through the pre-calculation process to persist the results, which is highly sensitive to data readiness and calculation time-consuming, and the query logic is relatively complex, and the scale of Trino/Impala clusters is relatively small. , the implementation is prone to failure, resulting in poor stability. In this scenario, we use the Spark engine with the largest cluster deployment scale, and achieve the reuse of offline computing resources without introducing new resource costs.
In terms of data readiness, through the Arctic meter water level awareness solution, a low minute-level readiness delay can be achieved.
In terms of calculation, Arctic provides some read optimizations for Spark Connector. Users can adjust the Arctic Combine Task by configuring the values of read.split.planning-parallelism and read.split.planning-parallelism-factor of the Arctic table. Quantity, and then control the concurrency of computing tasks. Since Spark’s offline computing resources are relatively flexible and sufficient, we can ensure that the computing needs of the business can be completed within 2 to 3 minutes by adjusting the concurrency as described above.

(3) Hive + Spark meets the scheduling of traditional offline warehouse production links
Arctic supports the use of Hive tables as Basestore. During Full Optimize, files are written to the Hive data directory to achieve the purpose of updating Hive’s native read content, and reduce costs through the integration of streams and batches on the storage architecture. Therefore, the traditional offline data warehouse production link can directly use the corresponding Hive table as part of the offline data warehouse link. Compared with the Arctic table in terms of timeliness, it lacks MOR, but through the Hive table water level sensing scheme, it can be done The ready delay is acceptable to the business, so as to meet the scheduling of traditional offline warehouse production links.

3 Project influence and output value
3.1 Project Influence
Through the exploration and implementation of the Arctic + X solution in the media, a new solution is provided for the quasi-real-time computing scene of the media. This idea not only relieves the real-time resource pressure and development, operation and maintenance burden brought by the full-link Flink real-time computing solution, but also better reuses existing storage computing resources such as HDFS and Spark, reducing costs and increasing efficiency. .
In addition, Arctic has also landed in multiple BUs such as Music and Youdao. For example, in Music Public Technology, it is used for the storage of ES cold data, which reduces the storage cost of user ES; and the Youdao quality course R&D team is also actively exploring and using Arctic As a solution in some of its business scenarios.
At present, Arctic has been open sourced on github, and has received continuous attention from the open source community and external users. In the construction and development of Arctic, it has also received many high-quality PRs submitted by external users.
3.2 Project output value
Through the above solution, we will push the detailed data of push ETL into Arctic in real time through Flink, and then configure minute-level scheduling tasks on the scheduling platform. After calculating according to different cross-dimensions, the cumulative indicators are written into the relational database. Continuous data display has achieved the minute-level timeliness data output required by the business side. Compared with the original full-link Flink real-time computing scheme, the modified scheme:
(1) Fully reuse offline idle computing power, reducing real-time computing resource expenditure
The scheme utilizes the offline computing resources in the idle state, and basically does not bring new resource expenditures. Offline computing business scenarios are destined to peak in the early morning, while news pushes and hot news are mostly generated during non-morning hours. On the premise of satisfying quasi-real-time computing timeliness, multiplexing improves the comprehensive utilization of offline computing clusters. Rate. In addition, this solution can help us release about 2.4T of real-time computing memory resources.
(2) Reduce task maintenance costs and improve task stability
The Arctic + Spark water level sensing trigger scheduling scheme can reduce the maintenance cost of 17+ real-time tasks, and reduce the stability problems caused by the large state of Flink’s real-time computing tasks. Through the Spark offline scheduling task, the offline resource pool can be fully utilized to adjust the computing parallelism, which effectively improves the robustness when dealing with hot news traffic peaks.
(3) Improve the repair ability when data is abnormal and reduce data repair time expenses
Through the streaming-batch integrated Arctic data lake storage architecture, when the abnormal data needs to be corrected, the abnormal data can be flexibly repaired to reduce the correction cost; if the data is traced back through the real-time calculation link or corrected through an additional offline process, Then the state accumulation or complex ETL process needs to be repeated.
4 Project future planning and outlook
At present, there are still some scenarios that Arctic cannot support well. The media big data team and Arctic team will continue to explore and implement solutions in the following scenarios:
(1) The current push detail data before entering the lake is generated by joining multiple upstream data streams, and there will also be a problem of large state. At present, Arctic can only support row-level update capabilities. If it can implement partial column update capabilities of primary key tables, it can help businesses directly realize multi-stream joins at a lower cost when entering the lake.
(2) Further improve the water level definition and perception scheme of Arctic table and Hive table, improve the timeliness, and promote it to more business scenarios. The current solution only supports the scenario where a single Spark/Flink task is written. For the scenario where multiple tasks write tables concurrently, it needs to be improved.
That’s it for this sharing, thank you all.
author: Lu Chengxiang Ma Yifan
#Lowcost #quasirealtime #computing #practice #based #Arctic #NetEase #Media #NetEase #Shufans #Personal #Space #News Fast Delivery