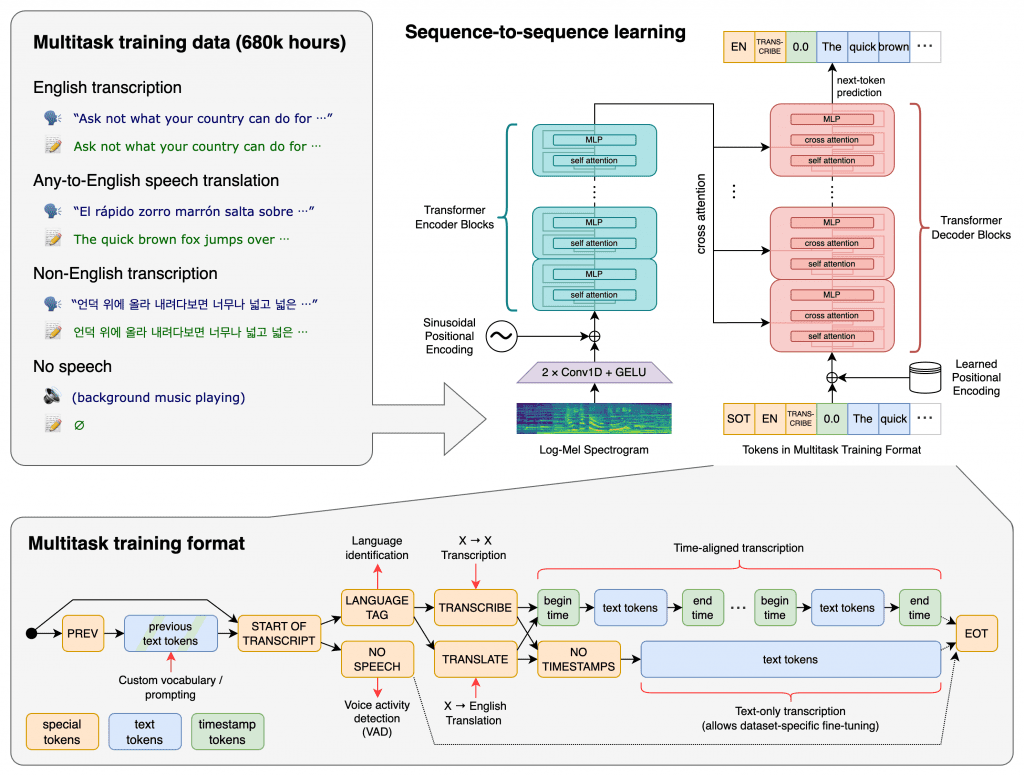
Whisper is OpenAI’s open source Automatic Speech Recognition (ASR, Automatic Speech Recognition) system. OpenAI trained Whisper on 680,000 hours of multilingual (98 languages) and multitask supervised data collected from the web. OpenAI believes that using such a large and diverse dataset can improve the ability to recognize accents, background noise, and technical jargon. In addition to being used for speech recognition, Whisper can also transcribe and translate these languages into English.

set up
We use Python 3.9.9 and PyTorch 1.10.1 to train and test our model, but the codebase is expected to be compatible with Python 3.7 or higher and the latest PyTorch version.The codebase also depends on some Python packages, the following command will pull and install the latest commit and its Python dependencies from this repository
pip install git+https://github.com/openai/whisper.git
It also requires command line tools to be installed on your system ffmpegmost package managers can use:
# on Ubuntu or Debian sudo apt update && sudo apt install ffmpeg # on MacOS using Homebrew (https://brew.sh/) brew install ffmpeg # on Windows using Chocolatey (https://chocolatey.org/) choco install ffmpeg # on Windows using Scoop (https://scoop.sh/) scoop install ffmpeg
At present, Whisper has 9 models (divided into pure English and multi-language), four of which are only available in English. Developers can make a trade-off between speed and accuracy according to their needs. The following are the sizes of existing models and their memory requirements. and relative velocity:
| size | parameter | English-only model | multilingual model | required video memory | Relative velocity |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550M | N/A | large | ~10GB | 1x |
#OpenAIWhisper #Homepage #Documentation #Downloads #OpenAI #Open #Source #Speech #Recognition #System #News Fast Delivery