
OpenAI, an artificial intelligence company that has a GTP-3 language model and provides technical support for GitHub Copilot, recently opened up the Whisper automatic speech recognition system. Open AI emphasized that Whisper’s speech recognition ability has reached human level.

Whisper is an Automatic Speech Recognition (ASR) system that OpenAI trained on 680,000 hours of multilingual (98 languages) and multitask supervised data collected from the web. OpenAI believes that using such a large and diverse dataset can improve the ability to recognize accents, background noise, and technical jargon. In addition to being used for speech recognition, Whisper can also transcribe and translate these languages into English. OpenAI opens up the model and inference code, hoping that developers can use Whisper as a foundation for building useful applications and further research into speech processing technology.
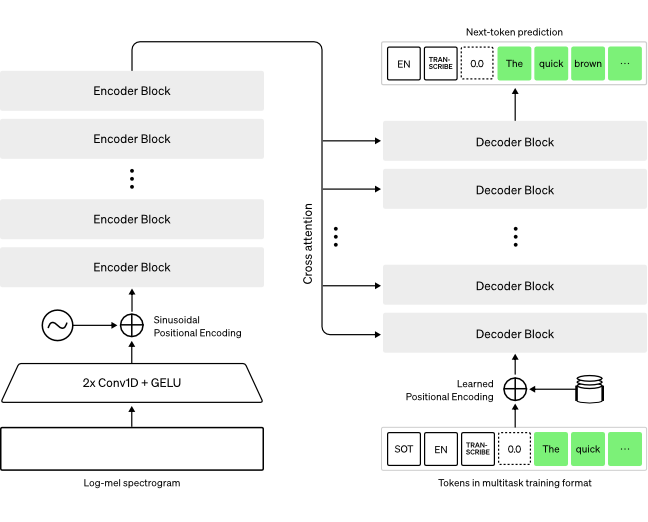
The general process of how Whisper performs an operation:
The input audio is split into 30 second segments, converted to log-Mel spectrograms, and passed to the encoder. The decoders are trained to predict the corresponding captions, mixed with special tokens that guide a single model to perform tasks such as language recognition, phrase-level timestamping, multilingual speech transcription, and speech translation.

Compared to other existing methods currently on the market, they typically use smaller, more tightly paired “audio-text” training datasets, or use extensive but unsupervised audio pretraining sets. Because Whisper was trained on a large and diverse dataset without being fine-tuned for any specific dataset, although it did not beat models that specialize in LibriSpeech performance (the well-known speech recognition benchmark), it was tested on many different When measuring the performance of Whisper’s Zero-shot (which does not require retraining on a new dataset to get good results) on the dataset, the researchers found that it was much more robust than those models, making 50% fewer errors.
At present, Whisper has 9 models (divided into pure English and multi-language), four of which are only available in English. Developers can make a trade-off between speed and accuracy according to their needs. The following are the sizes of existing models and their memory requirements. and relative velocity:
| size | parameter | English-only model | multilingual model | required video memory | Relative velocity |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550M | N/A | large | ~10GB | 1x |
OpenAI hopes that Whisper’s high accuracy and ease of use will allow developers to add speech recognition to a wider range of applications, especially to help improve accessibility tools.
Project address: GitHub
#OpenAI #Open #Source #Speech #Recognition #Model #Whisper