vivo Internet Security Team – Xie Peng
With the advent of the era of big data on the Internet, web crawler has also become an important industry in the Internet. It is a crawler program that automatically obtains web page data and information, and is an important part of website search engines. Through the crawler, you can obtain the relevant data information you want, and let the crawler assist you in your work, thereby reducing costs, improving business success rate and improving business efficiency.
On the one hand, this article explains how to efficiently crawl open data on the network from the perspective of crawlers and anti-anti-crawlers. On the other hand, it also introduces the technical means of anti-crawlers. Provides some advice on overloading the server.
Crawler refers to a program that automatically grabs information from the World Wide Web according to certain rules. This time, we will briefly introduce the technical principle and implementation of crawler, anti-crawler and anti-anti-crawler. The introduced cases are only used for security research. And learning, and not doing a lot of crawling or applying to business.
First, the technical principle and implementation of crawler
1.1 Definition of crawler
Crawlers are divided into two categories: general-purpose crawlers and focused crawlers. The goal of the former is to crawl as many sites as possible while maintaining a certain content quality. For example, search engines such as Baidu are this type of crawlers. Figure 1 is a general-purpose crawler. Search engine infrastructure:
First, select a part of web pages in the Internet, and use the link addresses of these web pages as the seed URL;
Put these seed URLs into the URL queue to be crawled, and the crawler reads them in sequence from the URL queue to be crawled;
The URL is resolved through DNS, and the link address is converted into the IP address corresponding to the website server;
The webpage downloader downloads the webpage through the website server, and the downloaded webpage is in the form of a webpage document;
Extract URLs in web documents and filter out URLs that have been crawled;
Continue to crawl the URLs that have not been crawled until the queue of URLs to be crawled is empty.
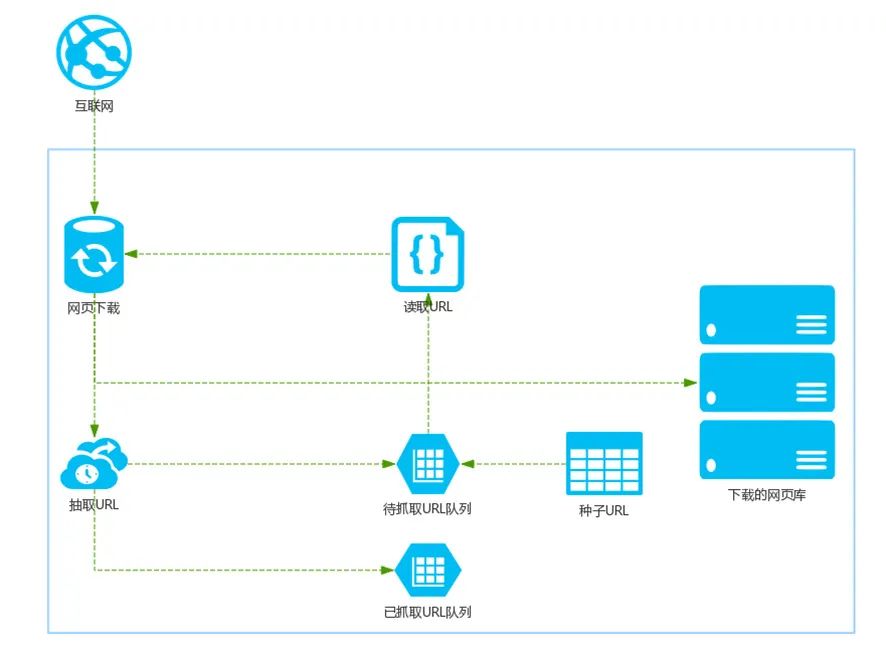
Figure 1. Infrastructure of a general search engine
The crawler usually starts from one or more URLs, and continuously puts new URLs that meet the requirements into the queue to be crawled during the crawling process until the stopping conditions of the program are met.
The crawlers we see every day are basically the latter, and the goal is to maintain accurate content quality as much as possible while crawling a small number of sites. A typical example is shown in Figure 2, the ticket grabbing software, which uses crawlers to log in to the ticketing network and crawl information to assist business.

Figure 2. Ticket grabbing software
After understanding the definition of crawler, how should we write crawler programs to crawl the data we want. We can first understand the currently commonly used crawler framework, because it can write the implementation code of some common crawler functions, and then leave some interfaces. When doing different crawler projects, we only need to write a small amount of changes according to the actual situation. , and call these interfaces as needed, that is, you can implement a crawler project.
1.2 Introduction to the crawler framework
The commonly used search engine crawler framework is shown in Figure 3. First of all, Nutch is a crawler specially designed for search engines and is not suitable for precise crawling. Both Pyspider and Scrapy are crawler frameworks written in the python language, and both support distributed crawlers. In addition, due to its visual operation interface, Pyspider is more user-friendly than Scrapy’s full command line operation, but its functions are not as powerful as Scrapy.
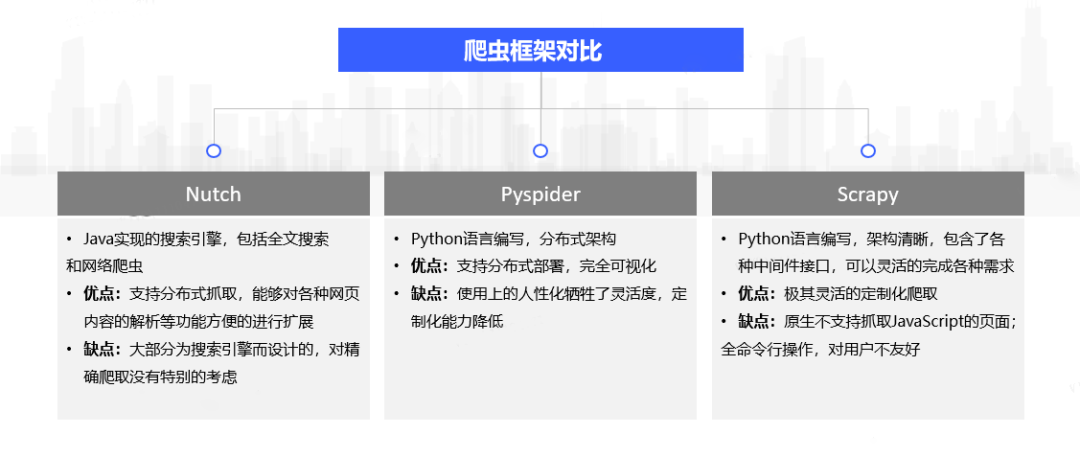
Figure 3. Crawler framework comparison
1.3 Simple example of crawler
In addition to using the crawler framework for crawling, you can also write crawler programs from scratch. The steps are shown in Figure 4:
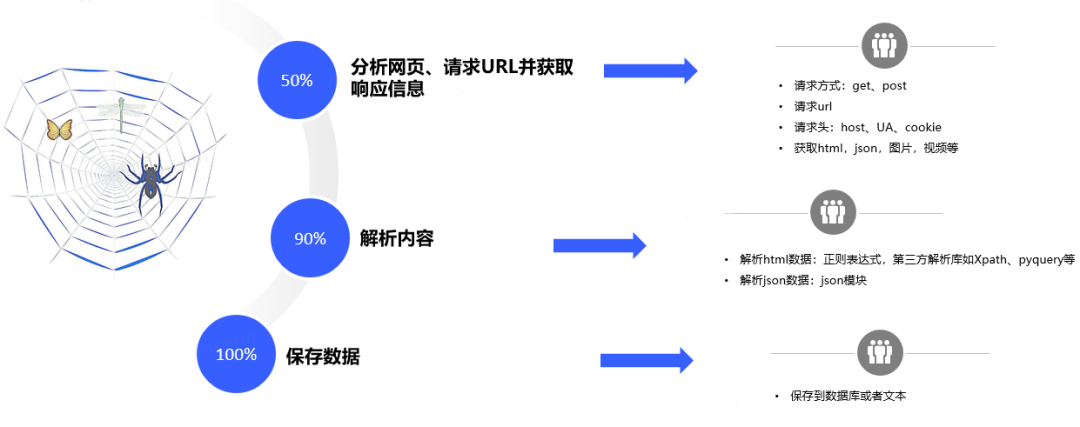
Figure 4. The basic principle of crawler
Next, we will demonstrate the above steps through a simple example. What we want to crawl is the list of a certain application market. We take this as an example because this website does not have any anti-crawling means. We can easily pass the above steps. Crawl to content.


Figure 5. Web page and its corresponding source code
The web page and its corresponding source code are shown in Figure 5. For the data on the web page, it is assumed that we want to crawl the name of each app on the leaderboard and its classification.
We first analyzed the source code of the web page and found that we can directly search for the name of the app such as “Douyin” in the source code of the web page, and then see that the app name, app category, etc. are all in a
def get_one_page(url):try:response = requests.get(url)if response.status_code == 200:return response.textreturn Noneexcept RequestException:return Nonedef parse_one_page(html):pattern = re.compile('<li>.*?data-src="https://my.oschina.net/vivotech/blog/(.*?)".*?<h5>.*?det.*?>(.*?)</a>.*?p.*?<a.*?>(.*?)</a>.*?</li>',re.S)items = re.findall(pattern, html)j = 1for item in items[:-1]:yield {'index': str(j),'name': item[1],'class':item[2]}j = j+1def write_to_file(content):with open(r'test.txt', 'a', encoding='utf-8') as f:f.write(json.dumps(content, ensure_ascii=False)+'\n')

Figure 6. Crawler code and results
2. Anti-reptile related technologies
Before understanding the specific anti-crawling measures, let’s first introduce the definition and meaning of anti-crawling. The behavior of restricting crawler programs to access server resources and obtain data is called anti-crawling. The access rate and purpose of crawlers are different from those of normal users. Most crawlers will crawl the target application without restraint, which brings huge pressure to the server of the target application. Network requests made by bots are called “junk traffic” by operators. In order to ensure the normal operation of the server or reduce the pressure and operating cost of the server, developers have to resort to various technical means to limit the access of crawlers to server resources.
So why do anti-crawlers? The answer is obvious. The crawler traffic will increase the load of the server. Excessive crawler traffic will affect the normal operation of the service, resulting in loss of revenue. On the other hand, the leakage of some core data will cause Make data owners uncompetitive.
Common anti-reptile methods are shown in Figure 7. It mainly includes text obfuscation, dynamic page rendering, verification code verification, request signature verification, big data risk control, js obfuscation and honeypot, etc. The text obfuscation includes css offset, image camouflage text, custom fonts, etc. The formulation of control strategies is often based on parameter verification, behavior frequency and pattern anomalies.

Figure 7. Common anti-reptile methods
2.1 CSS offset anti-crawler
When building a web page, you need to use CSS to control the position of various characters. This is also the case. You can use CSS to store the text displayed in the browser in HTML in an out-of-order manner, thereby limiting crawlers. CSS offset anti-crawling is an anti-crawling method that uses CSS styles to typeset out-of-order text into normal human reading order. This concept is not well understood. We can deepen our understanding of this concept by comparing two paragraphs of text:
In the above two paragraphs, the browser should display the correct information. If we follow the crawler steps mentioned above and analyze the webpage and extract the information regularly, we will find that the student number is wrong.
Looking at the example shown in Figure 8, if we want to crawl the air ticket information on this webpage, we first need to analyze the webpage. The price of 467 shown in the red box corresponds to the air ticket from Shijiazhuang to Shanghai of China Civil Aviation, but analyzing the source code of the web page found that there are 3 pairs of b tags in the code, the first pair of b tags contains 3 pairs of i tags, and the i tags in the The numbers are all 7, which means that the display result of the first pair of b labels should be 777. The number in the second pair of b labels is 6, and the number in the third pair of b labels is 4, so we will not be able to get the correct ticket price directly through regular matching.
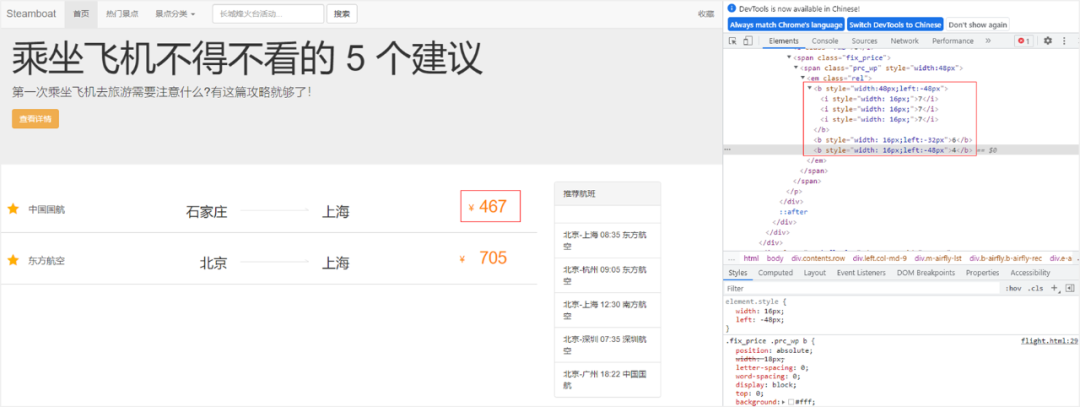
Figure 8. CSS offset anti-crawler example
2.2 Picture camouflage anti-reptile
Picture camouflage anti-crawler, its essence is to replace the original content with pictures, so that the crawler program cannot be obtained normally, as shown in Figure 9. The principle of this anti-crawler is very simple, that is, the part that should be ordinary text content is replaced with pictures in the front-end page. In this case, you can directly use ocr to identify the text in the picture and bypass it. And because it is displayed with pictures instead of text, the pictures themselves will be relatively clear, without a lot of noise interference, and the results of ocr recognition will be very accurate.
Figure 9. Image camouflage anti-reptile example
2.3 Anti-crawlers with custom fonts
In the CSS3 era, developers could use @font-face to specify fonts for web pages. Developers can put their favorite font file on the web server and use it in CSS styles. When a user uses a browser to access a web application, the corresponding font will be downloaded by the browser to the user’s computer, but when we use a crawler program, since there is no corresponding font mapping relationship, we cannot get valid data by direct crawling.
As shown in Figure 10, the information such as the number of evaluations, per capita, taste, and environment of each store in the webpage are all garbled characters, and the crawler cannot directly read the content.
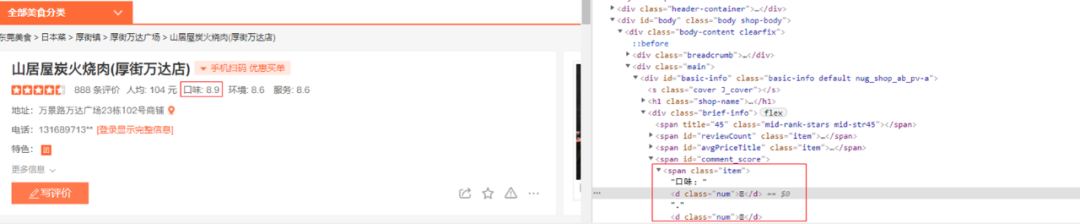
Figure 10. Custom font anti-crawler example
2.4 Page dynamic rendering anti-crawler
According to different rendering methods, web pages can be roughly divided into client-side and server-side rendering.
server-side renderingthe result of the page is returned by the server after rendering, and the valid information is included in the requested HTML page. By viewing the source code of the web page, you can directly view the data and other information;
client-side renderingthe main content of the page is rendered by JavaScript, the real data is obtained through Ajax interface and other forms, and there is no valid data information by viewing the source code of the web page.
The most important difference between client-side rendering and server-side rendering is who will complete the complete splicing of html files. If it is done on the server side and then returned to the client, it is server-side rendering. A lot of work completes the splicing of html, which is client-side rendering.
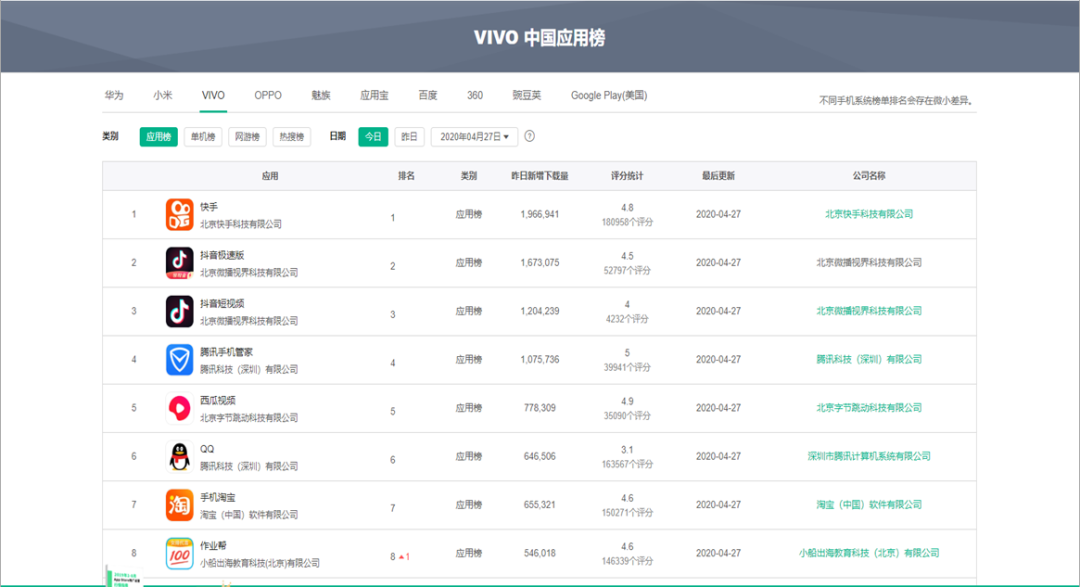
Figure 11. Client-side rendering example
2.5 Verification code anti-crawlers
Almost all applications will pop up verification codes for users to identify when it comes to the security of user information, to ensure that the operation is human behavior, not a large-scale machine. Then why does the verification code appear? In most cases it is because the website is visited too frequently or behaves abnormally, or to directly limit certain automated actions. Categorized as follows:
In many cases, such as login and registration, these verification codes are almost always available, and their purpose is to limit malicious registration, malicious blasting, etc., which is also a means of anti-crawling.
When some websites encounter behaviors with high access frequency, a login window may pop up directly, requiring us to log in before continuing to visit. At this time, the verification code is directly bound to the login form, even if an abnormality is detected. Anti-crawling by means of forced login.
Some more conventional websites will actively pop up a verification code for users to identify and submit if they encounter a situation with a slightly higher frequency of visits to verify whether the current visitor to the website is a real person. reptile.
Common verification codes include graphic verification codes, behavior verification codes, text messages, scanning verification codes, etc., as shown in Figure 12. For whether or not to successfully pass the verification code, in addition to being able to accurately complete the corresponding clicks, selections, inputs, etc. according to the requirements of the verification code, it is also crucial to pass the verification code risk control; for example, for the slider verification code, the verification code risk control may be Detecting the sliding trajectory, if the trajectory is detected to be non-artificial, it will be judged as a high risk, resulting in failure to pass successfully.
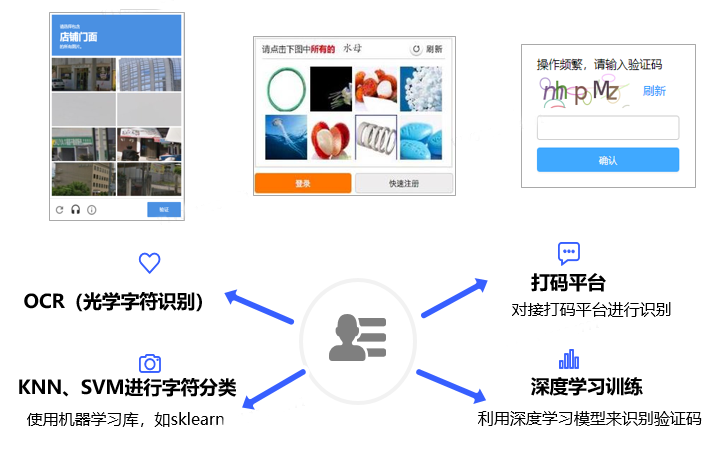
Figure 12. Captcha anti-crawler means
2.6 Request signature verification anti-crawlers
Signature verification is one of the effective ways to prevent the server from being maliciously linked and tampered with data, and it is also one of the most commonly used protection methods for back-end APIs. Signature is a process of calculating or encrypting according to the data source. After the user signs, a consistent and unique string will be generated, which is the identity symbol of your access to the server. Due to its two characteristics of consistency and uniqueness, it can effectively prevent the server from processing forged data or tampered data as normal data.
The website mentioned above in Section 2.4 renders the web page through the client, and the data is obtained through the ajax request, which increases the difficulty of the crawler to a certain extent. Next, analyze the ajax request, as shown in Figure 13, you will find that the ajax request is signed with the request, analysis is the encrypted parameter, and if you want to crack the request interface, you need to crack the encryption method of the parameter, which is undoubtedly further increased the difficulty.

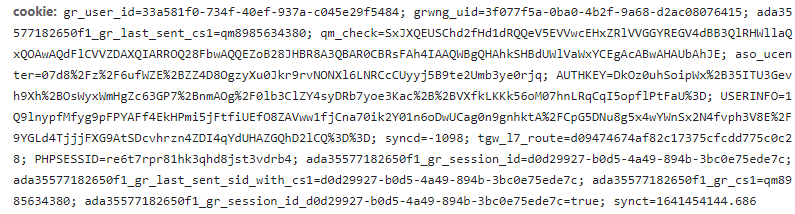
Figure 13. Ajax request for ranking data
2.7 Honeypot Anti-Crawler
Honeypot anti-crawler is a means of hiding links used to detect crawler programs in web pages. The hidden links will not be displayed on the page and cannot be accessed by normal users, but the crawler program may put the link to be crawled. Queue, and initiate a request to the link, developers can use this feature to distinguish normal users and crawlers. As shown in Figure 14, looking at the source code of the webpage, there are only 6 products on the page, but there are 8 pairs of
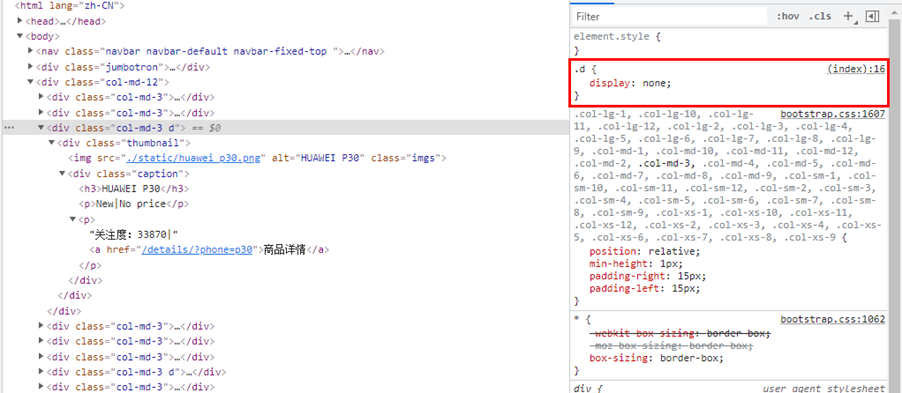
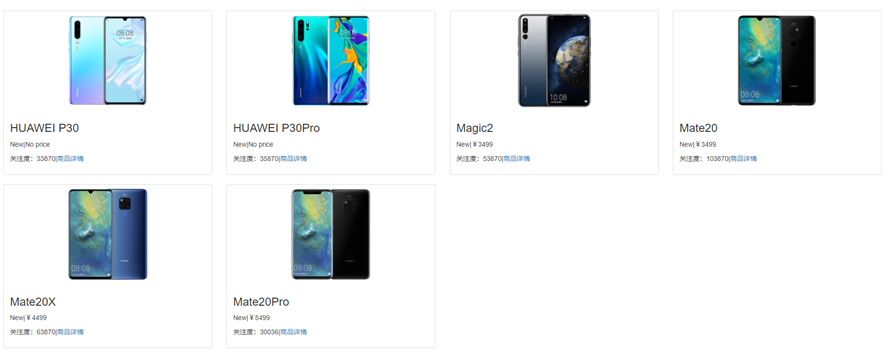
Figure 14. Honeypot anti-crawler example
3. Anti-anti-climbing related technologies
For the anti-crawling-related technologies mentioned in the previous section, there are the following types of anti-anti-crawling technical means: CSS offset anti-crawling, custom font anti-crawling, dynamic page rendering anti-crawling, verification code cracking, etc. These methods are described in detail.
3.1 CSS offset anti-climbing
3.1.1 Introduction to CSS Offset Logic
So for the above example of 2.1css offset anti-crawlers, how can we get the correct air ticket price? Looking closely at the CSS style, you can find that each tag with a number has a style set, and the style of the i tag pair in the first pair of b tags is the same, both width: 16px; in addition, also notice that the outermost layer The style of the span tag pair is width:48px.
If analyzed according to the clue of CSS style, the three pairs of i tags in the first pair of b tags just occupy the position of the span tag pair, and their positions are shown in Figure 15. At this point the price displayed in the web page should be 777, but since the 2nd and 3rd pairs of b tags have values in them, we also need to calculate their positions. Since the position style of the second pair of b tags is left:-32px, the value 6 in the second pair of b tags will overwrite the second number 7 in the original first pair of b tags, and the page should display The number is 767.
According to this rule, the position style of the third pair of b tags is left:-48px, the value of this label will cover the first number 7 in the first pair of b tags, and the final displayed fare is 467.
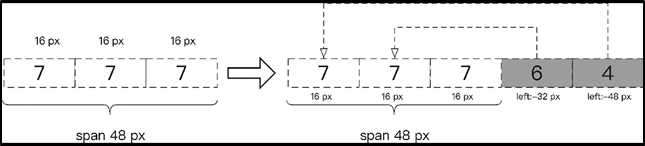
Figure 15. Offset logic
3.1.2 CSS offset anti-climbing code implementation
Therefore, we will write the code according to the rules of the above CSS style to crawl the webpage to obtain the correct air ticket price. The code and result are shown in Figure 16.
if __name__ == '__main__':url = 'http://www.porters.vip/confusion/flight.html'resp = requests.get(url)sel = Selector(resp.text)em = sel.css('em.rel').extract()for element in range(0,1):element = Selector(em[element])element_b = element.css('b').extract()b1 = Selector(element_b.pop(0))base_price = b1.css('i::text').extract()print('css偏移前的价格:',base_price)alternate_price = []for eb in element_b:eb = Selector(eb)style = eb.css('b::attr("style")').get()position = ''.join(re.findall('left:(.*)px', style))value = eb.css('b::text').get()alternate_price.append({'position': position, 'value': value})print('css偏移值:',alternate_price)for al in alternate_price:position = int(al.get('position'))value = al.get('value')plus = True if position >= 0 else Falseindex = int(position / 16)base_price[index] = valueprint('css偏移后的价格:',base_price)

Figure 16. CSS offset anti-crawl code and results
3.2 Anti-climbing of custom fonts
For the above 2.3 custom font anti-crawling situation, the solution is to extract the custom font file (usually WOFF file) in the web page, and include the mapping relationship into the crawler code to obtain valid data. The steps to resolve are as follows:
Find the problem: Check the source code of the web page and find that the key characters are replaced by encoding, such as 

Analysis: Check the web page and find that css custom character set hiding is applied
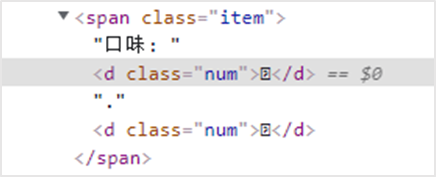
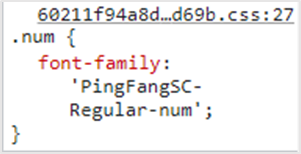
Find: Find the url of the css file and get the url corresponding to the character set, such as PingFangSC-Regular-num
Find: Find and download charset urls

Comparison: Compare the characters in the character set with the code in the source code of the webpage, and find that the last four digits of the code correspond to the characters, that is, the taste corresponding to the source code of the webpage is 8.9 points

3.3 Page dynamic rendering and anti-crawling
Anti-crawlers for client-side rendering, the page code cannot be seen in the browser source code, it is necessary to perform rendering and further obtain the rendered results. For this anti-reptile, there are several ways to crack:
In the browser, directly view the specific request method, parameters, etc. of ajax through the developer tool;
Use selenium to simulate a real person operating the browser to obtain the rendered result. The subsequent operation steps are the same as the server-side rendering process;
If the rendered data is hidden in the JS variable of the html result, it can be directly extracted regularly;
If there are encrypted parameters generated by JS, you can find out the code of the encrypted part, and then use pyexecJS to simulate the execution of JS, and return the execution result.
3.4 Verification code cracking
The following is an example of identifying a slider verification code. As shown in Figure 17, it is an example of the result of using the target detection model to identify the position of a slider verification code gap. This method of cracking the slider verification code corresponds to simulating a real person. Way. The reason for not using interface cracking is that it is difficult to crack the encryption algorithm, and the encryption algorithm may change every day, so the time cost of cracking is relatively large.

Figure 17. Identifying gaps in slider captcha through object detection model
3.4.1 Crawling the slider verification code picture
Because the target detection model yolov5 used is supervised learning, it is necessary to crawl the picture of the slider verification code and mark it, and then input it into the model for training. Crawling some verification codes in a scene by simulating a real person.

Figure 18. Crawled slider verification code picture
3.4.2 Manual marking
This time, labelImg is used to manually label the pictures. Manual labeling takes a long time. It usually takes about 40 minutes for 100 pictures. The automatic marking code is more complicated to write, mainly because all the background pictures and gap pictures of the verification code need to be extracted separately, and then the gap position is randomly generated as a label, and the gap is placed in the corresponding gap position to generate a picture as input.

Figure 19. Tag the verification code image and the xml file generated after tagging
3.4.3 Target detection model yolov5
Download the official code of clone yolov5 directly from github, which is based on pytorch.
The next steps are as follows:
data format conversion: Convert the manually labeled pictures and label files to the data format received by yolov5, and get 1100 pictures and 1100 label files in yolov5 format;
New dataset: Create a new custom.yaml file to create your own dataset, including the directory, number of categories, and category name of training set and validation set;
training tuning: After modifying the model configuration file and training file, perform training and tune hyperparameters based on the training results.
Part of the script to convert the xml file to yolov5 format:
for member in root.findall('object'):class_id = class_text.index(member[0].text)xmin = int(member[4][0].text)ymin = int(member[4][1].text)xmax = int(member[4][2].text)ymax = int(member[4][3].text)center_x = round(((xmin + xmax) / 2.0) * scale / float(image.shape[1]), 6)center_y = round(((ymin + ymax) / 2.0) * scale / float(image.shape[0]), 6)box_w = round(float(xmax - xmin) * scale / float(image.shape[1]), 6)box_h = round(float(ymax - ymin) * scale / float(image.shape[0]), 6)file_txt.write(str(class_id))file_txt.write(' ')file_txt.write(str(center_x))file_txt.write(' ')file_txt.write(str(center_y))file_txt.write(' ')file_txt.write(str(box_w))file_txt.write(' ')file_txt.write(str(box_h))file_txt.write('\n')file_txt.close()
Training parameter settings:
parser = argparse.ArgumentParser()parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')parser.add_argument('--cfg', type=str, default='./models/yolov5s.yaml', help='model.yaml path')parser.add_argument('--data', type=str, default='data/custom.yaml', help='data.yaml path')parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')parser.add_argument('--epochs', type=int, default=50)parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs')parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')parser.add_argument('--rect', action='store_true', help='rectangular training')parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')parser.add_argument('--notest', action='store_true', help='only test final epoch')parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')parser.add_argument('--project', default='runs/train', help='save to project/name')parser.add_argument('--entity', default=None, help='W&B entity')parser.add_argument('--name', default='exp', help='save to project/name')parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')parser.add_argument('--quad', action='store_true', help='quad dataloader')parser.add_argument('--linear-lr', action='store_true', help='linear LR')parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')opt = parser.parse_args()
3.4.4 Training results of target detection model
The model has basically reached the bottleneck in precision, recall and mAP at 50 iterations. The prediction results also have the following problems: most of the gaps can be accurately framed, but there are also a small number of frame errors, two gaps, and no gaps.
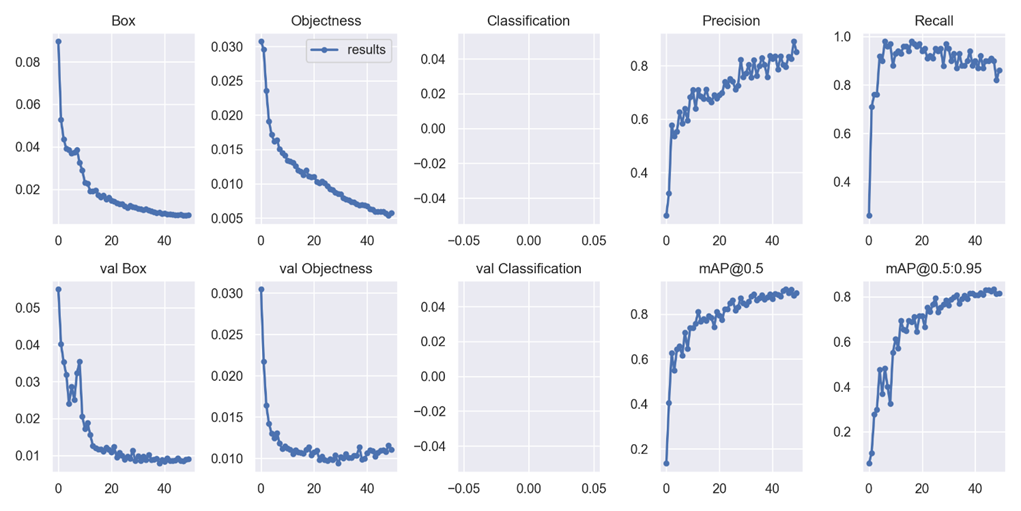

Figure 20. Above: The model’s training result chart;
Bottom: Model predictions on part of the validation set
4. Summary
This time, I briefly introduce the technical means of crawlers and anti-crawlers. The technologies and cases introduced are only used for security research and learning, and will not be used for a large number of crawlers or commercial applications.
For crawlers, for the purpose of crawling public data on the Internet for data analysis, etc., we should abide by the website robots protocol, and crawl data without affecting the normal operation of the website and complying with the law; for anti-crawlers, because as long as Web pages that humans can access normally can be crawlable by crawlers with the same resources. Therefore, the purpose of anti-crawlers is to prevent the crawlers from overloading the server in the process of collecting website information in large quantities, so as to prevent the crawler behavior from hindering the user’s experience, and to improve the user’s satisfaction with the use of website services.
END
you may also like
#Introduction #Crawler #AntiCrawler #Technology #vivo #Internet #Technology #News Fast Delivery