Summary:This article mainly brings four kinds of Kafka network interruption and network partition scenario analysis.
This article is shared from Huawei Cloud Community “Kafka Network Interruption and Network Partition Scenario Analysis”, author: middleware brother.
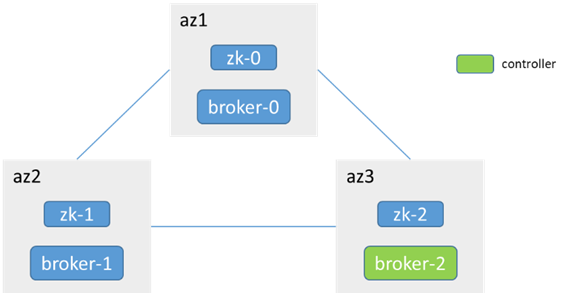
Take Kafka version 2.7.1 as an example, relying on zk deployment
3 brokers are distributed in 3 az, 3 zk (joint with broker), 3 replicas in a single partition
1. The network of a single broker node and leader node is interrupted
Before network outage:
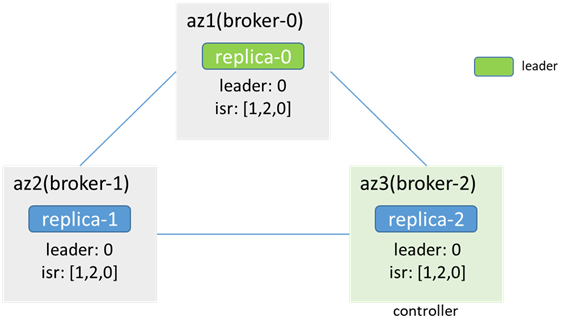
After the network between broker-1 and broker-0 (leader) is interrupted, unilateral interruption, zk is available (zk-1 is the leader, zk-0 and zk-2 are followers, zk-0 will be unavailable, but the zk cluster is available , the process may cause the broker node originally connected to zk-0 to be disconnected from zk first, and then reconnect to other zk nodes, which will cause controller switching, leader election, etc. This situation is not considered in this analysis), leader, isr, controller are unchanged
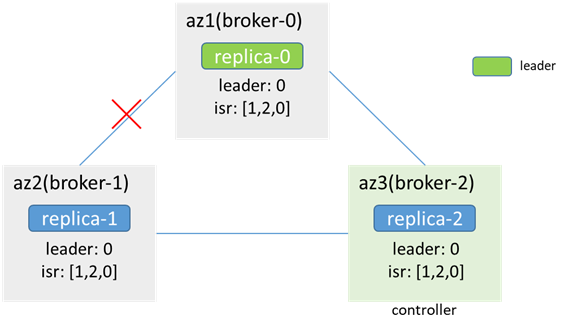
Clients in az2 cannot produce and consume (metadata indicates that the leader is broker-0, but az2 cannot connect to broker-0), clients in az1/3 can produce and consume, if acks=-1, retries=1, then production The message will fail, error_code=7 (REQUEST_TIMED_OUT) (because broker-1 is in isr, but cannot synchronize data), and it will be sent twice (because retries=1), there will be two in each of broker-0 and broker-2 Duplicate messages, but not in broker-1; because broker-0 has no synchronized data, it will be removed from isr, controller synchronize metadata and leaderAndIsr, isr updated to[2,0]
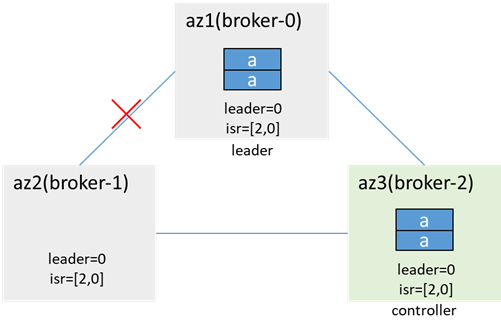
After the network is restored, the data is synchronized and the isr is updated
2. The network of a single broker node and controller node is interrupted
The disconnection between the broker and the controller does not affect production and consumption, and there will be no data inconsistency.
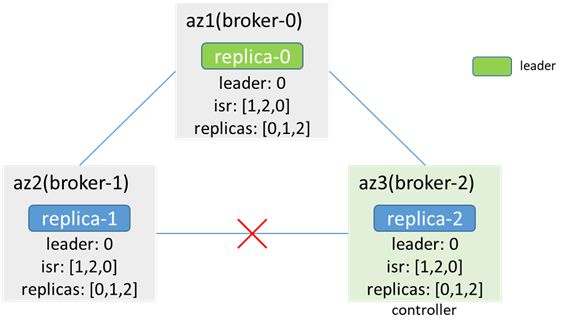
When the leader and isr changes, the controller cannot update the leader and isr changes to the broker, resulting in inconsistent metadata
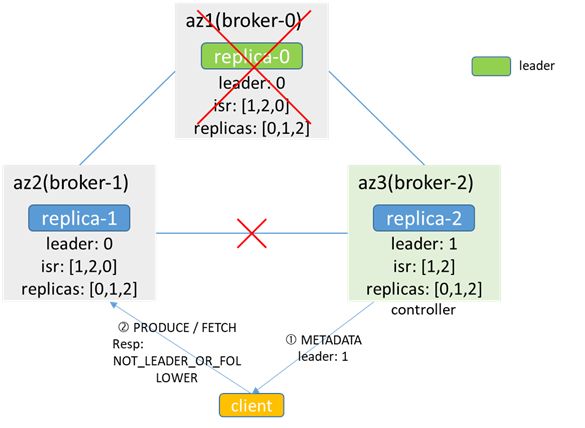
When broker-0 fails, the controller (broker-2) senses it and elects a new leader as broker-1 according to replicas, but because of network interruption with broker-1, it cannot synchronize to broker-1, and the leader cached by broker-1 is still broker-0, isr is[1,2,0]; When the client is producing and consuming, if the metadata is obtained from broker-2, the leader is considered to be 1, and access to broker-1 will return NOT_LEADER_OR_FOLLOWER; if the metadata is obtained from broker-1, the leader is considered to be 0, and access to broker-0 fails. , will lead to the failure of production and consumption
3. The az where the non-controller nodes are located is isolated (partitioned)
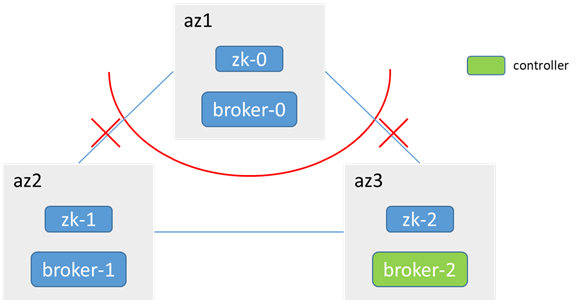
zk-0 does not work with zk-1 and zk-2, less than half, zk in az1 is unavailable, broker-0 cannot access zk, controller election will not occur, and the controller is still in broker-1
After the network is restored, broker-0 joins the cluster and synchronizes data
3.1 Three replica partitions (replicas:[1,0,2]), the original leader is broker-1 (or broker-2)
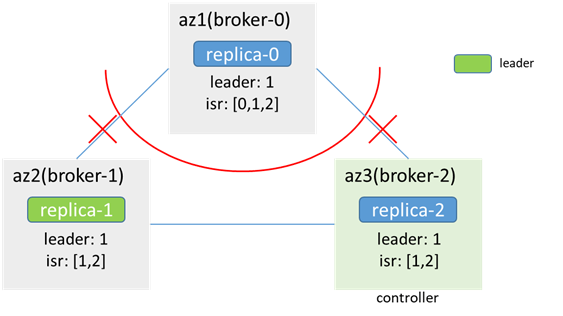
Inside az1:
broker-0 cannot access zk, cannot perceive node changes, and metadata is not updated (leader: 1, isr:[1,0,2]), still thinks that he is a follower, the leader is 1; the client in az1 cannot produce and consume
In az2/3:
zk is available, it senses that broker-0 is offline, metadata is updated, and no leader switch occurs (isr:[1,0,2] -> [1,2]leader: 1); clients in az2 and az3 can produce and consume normally
3.2 Three replica partitions (replicas:[0,1,2]), the original leader is at broker-0
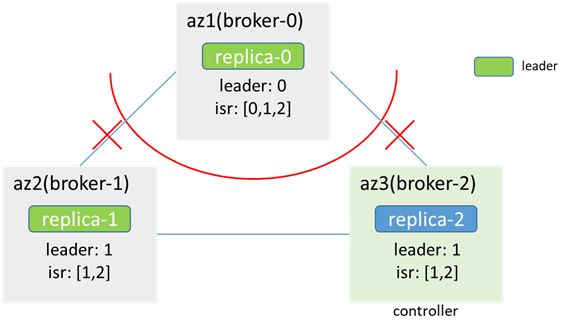
Inside az1:
The connection between zk-0 and zk-1 and zk-2 is interrupted, less than half, the zk cluster in az1 is unavailable, the broker-0 cannot connect to zk, cannot sense node changes, and cannot update isr, metadata remains unchanged, leader and isr All remain unchanged; clients in az1 can continue to produce and consume to broker-0
In az2/3:
zk-1 and zk-2 are connected, zk is available, the cluster senses that broker-0 is offline, triggers the leader switch, broker-1 becomes the new leader (the time depends on zookeeper.session.timeout.ms), and updates isr; az2 Clients in /3 can produce and consume to broker-1
At this point, the partition has a dual-master phenomenon. Both replica-0 and replica-1 are leaders, and both can be used for production and consumption.
If both clients in the two isolation domains produce messages, data inconsistency will occur
Example: (Assume there are two messages before network isolation, leaderEpoch=0)
Before network isolation:
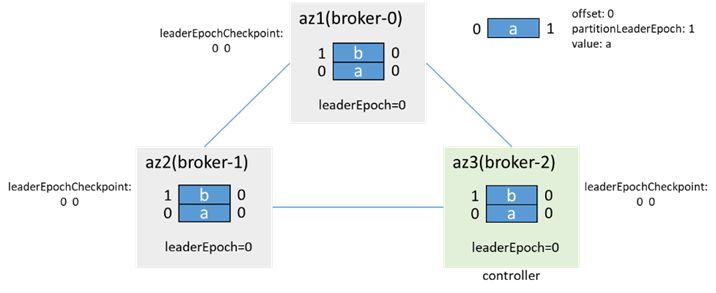
After az1 is isolated and the partition is dual-master, the client in az1 writes 3 messages: c, d, and e, and the client in az2/3 writes 2 messages: f, g:
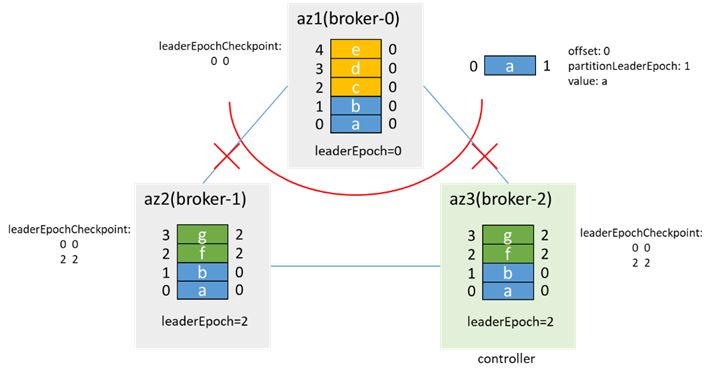
Here the leaderEpoch is increased by 2 because there are two operations to increase the leaderEpoch: one is the leader election when handleStateChanges of PartitionStateMachine goes to OnlinePartition, and the other is removeReplicasFromIsr when handleStateChanges of ReplicationStateMachine goes to OfflineReplica
After the network is restored:
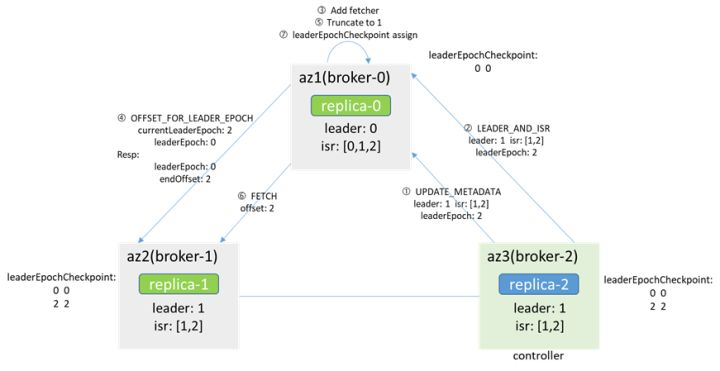
Since the controller is in broker-2, the leader in the cache and zk is broker-1, the controller will inform broker-0 makerFollower, broker-0 will add fetcher immediately, and will first obtain the endOffset corresponding to the leaderEpoch from the leader (broker-1) (via OFFSET_FOR_LEADER_EPOCH), truncate according to the returned result, then start the FETCH message, and assign according to the leaderEpoch in the message, so as to be consistent with the leader
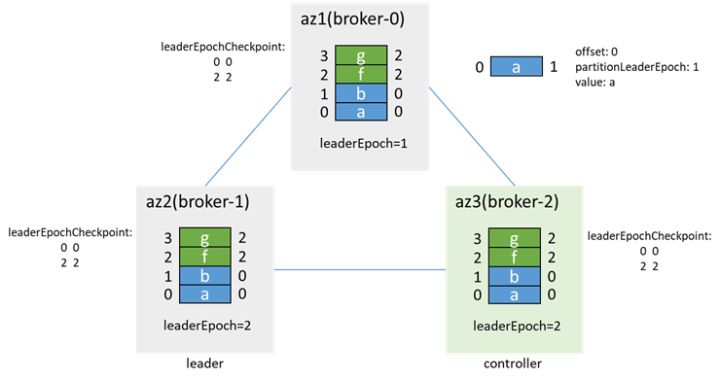
After the data is synchronized, add the isr and update the isr to[1,2,0]. Later, when the preferredLeaderElection is triggered, broker-0 becomes the leader again and increases the leaderEpoch to 3
During network isolation, if the client in az1 has acks=-1 and retries=3, it will find that the production message fails, but there are messages in the data directory, which are 4 times the number of production messages (each message is repeated 4 times)
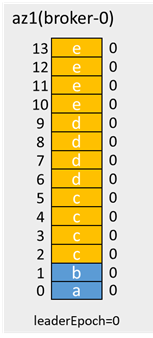
As mentioned above, after the network is restored, the messages of offset 2-13 will be overwritten, but because these messages are in production, acks=-1, the production failure is returned to the client, so it is not counted as message loss.
Therefore, considering this situation, it is recommended that client acks=-1
4. The az where the Controller node is located is isolated (partitioned)
4.1 Leader node is not isolated
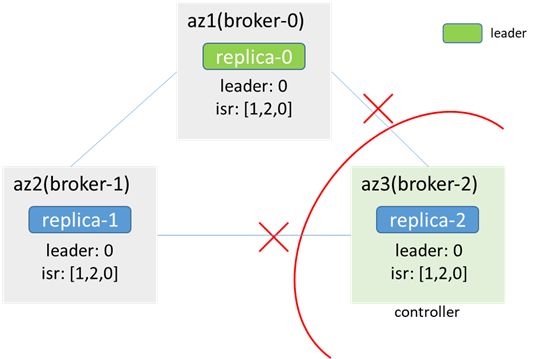
After the network is interrupted, the zk of az3 is unavailable, broker-2 (original controller) is disconnected from the zk cluster, and broker-0 and broker-1 re-elect the controller
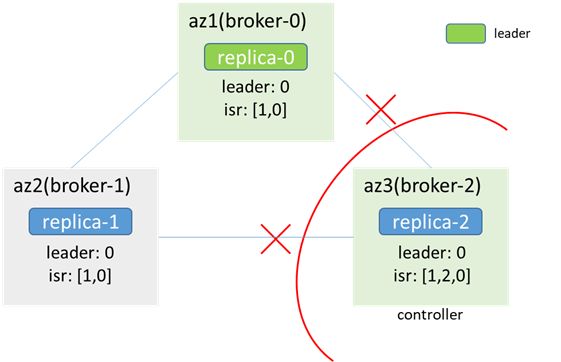
In the end, broker-0 is elected as the controller, and broker-2 also considers itself to be the controller, and the controller has dual masters. At the same time, because the zk cannot be connected, the metadata cannot be updated, the clients in az3 cannot produce and consume, and the clients in az1/2 normal production and consumption
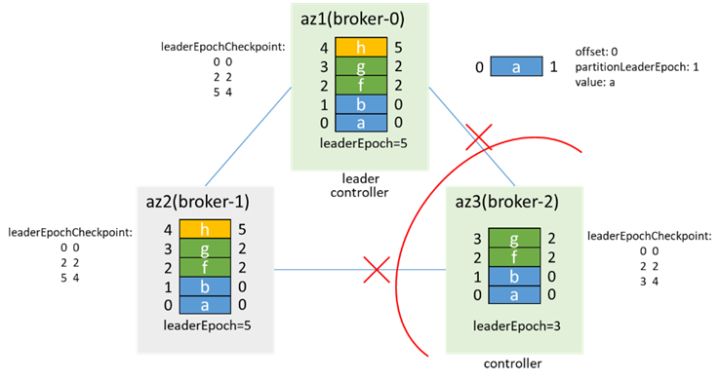
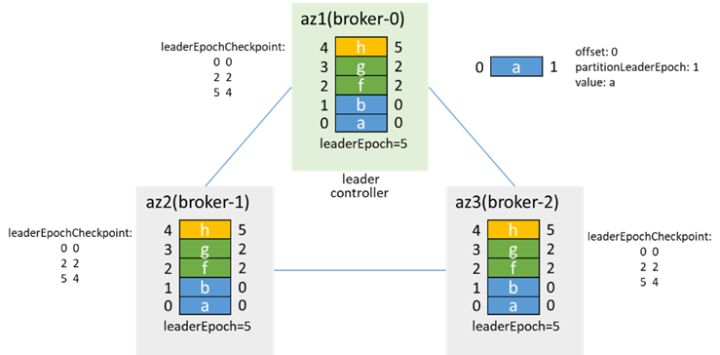
After the fault is recovered, broker-2 perceives that the zk connection status has changed, it will resign first, and then try to run for the controller. It finds that broker-0 is already the controller and gives up the election of the controller. At the same time, broker-0 will sense that broker-2 is online. Will synchronize LeaderAndIsr and metadata to broker-2, and add isr after broker-2 synchronizes data
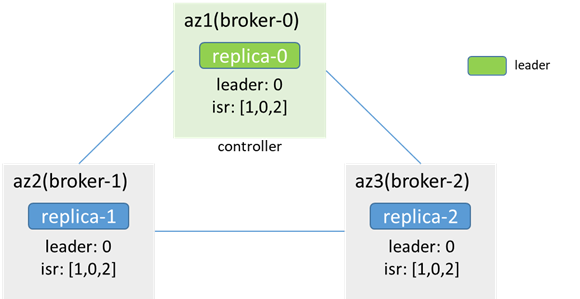
4.2 Leader node and controller are the same node and are isolated together
Before isolation, both controller and leader are in broker-0:
After the isolation, the az1 network is isolated, zk is unavailable, broker-2 is elected as the controller, and the controller has dual masters. At the same time, replica-2 becomes the leader, and the partition also has dual masters.
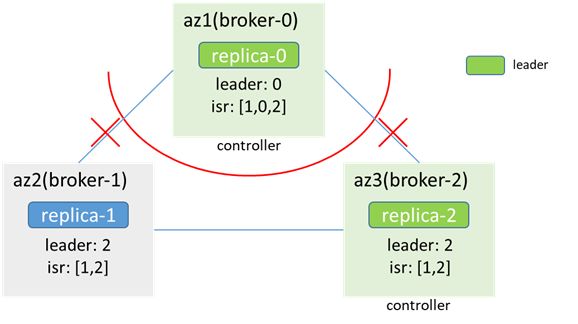
The scene at this time is similar to 3.2. At this time, the production message may have data inconsistency
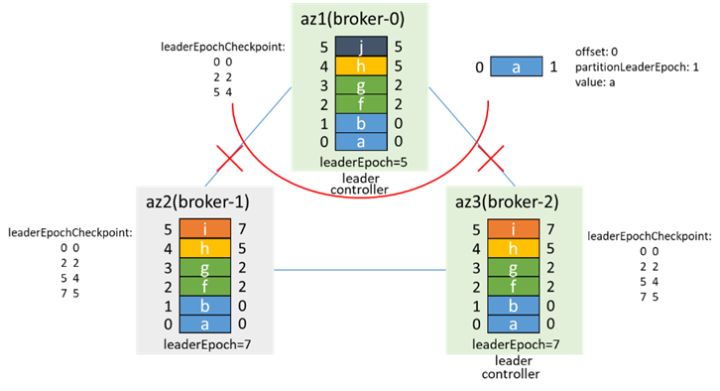
The situation after network recovery is similar to 3.2, broker-2 is the controller and leader, broker-0 truncates according to the leaderEpoch, and synchronizes data from broker-2
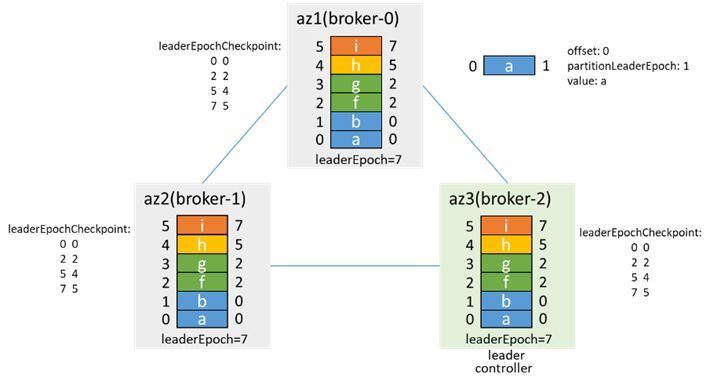
Join the isr, then become the leader again through preferredLeaderElection, and increase the leaderEpoch by 1
5. Supplement: Data inconsistency caused by failure scenarios
5.1 Instantaneous failure of data synchronization
Initially, broker-0 is the leader and broker-1 is the follower, each with two messages a and b:
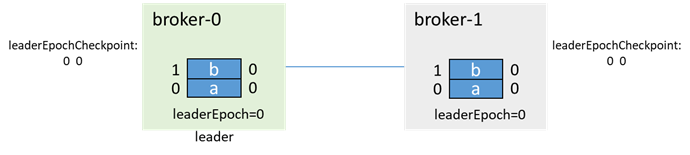
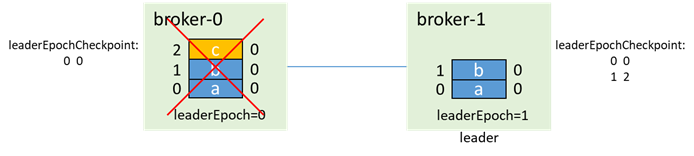
The leader writes a message c, and before it has time to synchronize to the follower, both brokers fail (as follows:
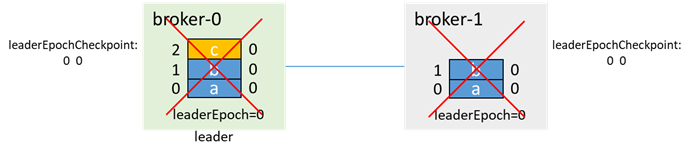
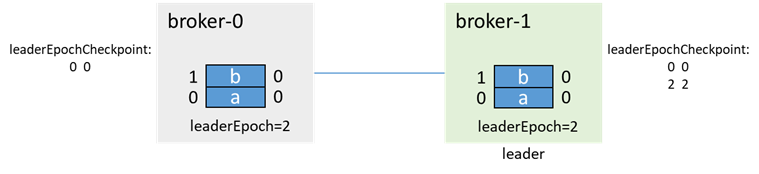
After that, broker-1 starts first and becomes the leader (both 0 and 1 are in the isr, regardless of whether unclean.leader.election.enable is true or not, it can be promoted to the master), and increments the leaderEpoch:
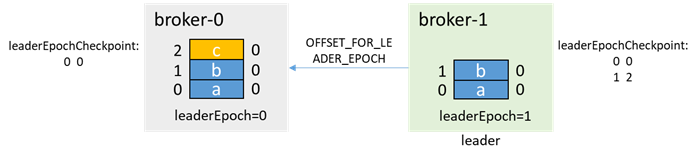
Then broker-0 starts, which is a follower at this time, and obtains the endOffset of leaderEpoch=0 from broker-1 through OFFSET_FOR_LEADER_EPOCH
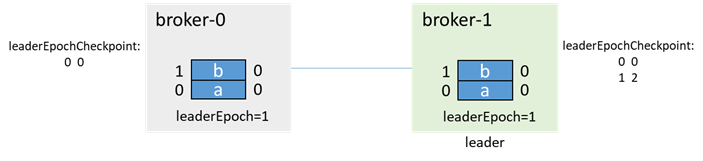
broker-0 truncates according to the leader epoch endOffset:
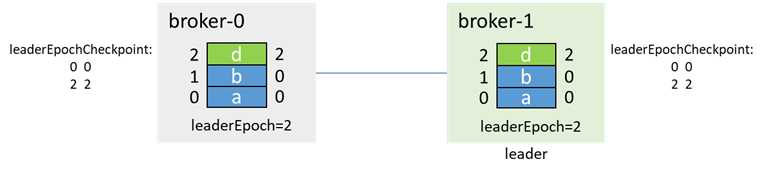
Then the normal production messages and replicas are synchronized:
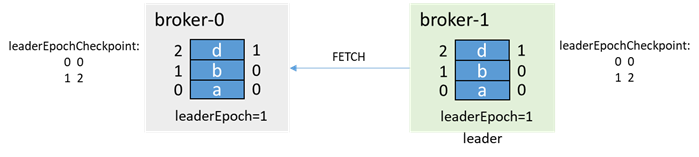
In this process, if acks=-1, when the message c is produced, the production failure is returned to the client, and the message is not lost; if acks=0 or 1, the message c is lost
5.2 Data loss caused by unclean.leader.election.enable=true
Still this example, broker-0 is the leader, broker-1 is the follower, and each has two messages a and b. At this time, broker-1 is down, isr=[0]
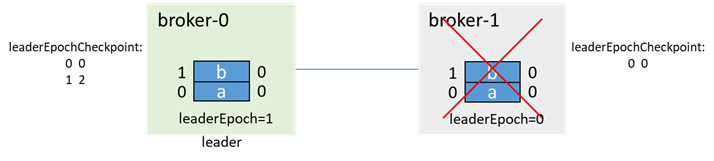
During the failure of broker-1, the message c is produced, because broker-1 is no longer in the isr, so even if acks=-1, it can be produced successfully
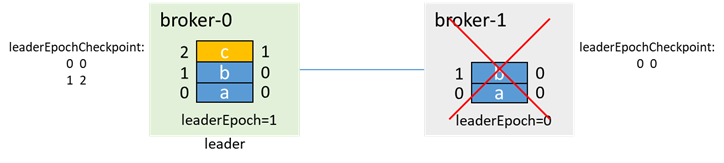
Then broker-0 also goes down, leader=-1, isr=[0]
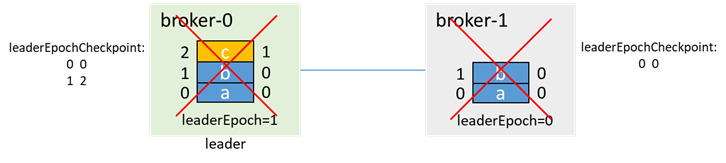
At this time, broker-1 is pulled up first. If unclean.leader.election.enable=true, then even if broker-1 is not in the isr, because broker-1 is the only living node, broker-1 will be elected as leader and update leaderEpoch is 2
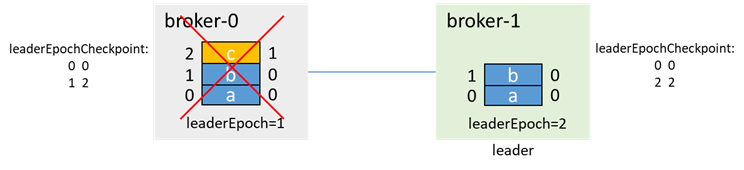
At this time, when broker-0 is pulled up again, it will first pass OFFSET_FOR_LEADER_EPOCH to obtain epoch information from broker-1 and truncate the data.
Re-synchronize production messages and replicas
message c is lost
Click Follow to learn about HUAWEI CLOUD’s new technologies for the first time~
#Analysis #Kafka #Network #Interruption #Network #Partition #Scenarios