Author: Presence, Cen Ming, Xiong Xi
A guide
As BERT, Megatron, GPT-3 and other pre-training models have achieved remarkable results in the field of NLP, more and more teams are devoted to ultra-large-scale training, which makes the scale of training models develop from 100 million to 100 billion or even trillions scale. However, there are still some challenges in applying such very large-scale models to real-world scenarios. First, the large number of model parameters makes the training and inference speed too slow and the deployment cost is extremely high; secondly, the problem of insufficient data volume in many practical scenarios still restricts the application of large models in small sample scenarios. The generalization of sample scenarios remains a challenge. In order to deal with the above problems, the PAI team launched the EasyNLP Chinese NLP algorithm framework to help large models land quickly and efficiently.
How is the technical framework behind EasyNLP designed? What are the plans for the future? Let’s learn more about it today.
2 Introduction to EasyNLP
EasyNLP is an easy-to-use and rich Chinese NLP algorithm framework developed by the PAI algorithm team based on PyTorch. It supports commonly used Chinese pre-training models and large model landing technologies, and provides a one-stop NLP development experience from training to deployment. EasyNLP provides a concise interface for users to develop NLP models, including NLP applications AppZoo and pre-trained ModelZoo, and provides technology to help users efficiently implement large pre-trained models into business. In addition, the EasyNLP framework can provide users with large-scale and robust training capabilities with the help of the PAI team’s deep accumulation in communication optimization and resource scheduling, and can seamlessly connect to PAI series products, such as PAI-DLC, PAI-DSW , PAI-Designer and PAI-EAS, bringing users an efficient and complete experience from training to landing.
EasyNLP has already supported more than 10 BU businesses in Alibaba. At the same time, it provides NLP solutions and ModelHub models on Alibaba Cloud to help users solve business problems, and also provides user-defined model services to facilitate users to create self-developed models. After internal business polishing, we will promote EasyNLP to the open source community, hoping to serve more NLP algorithm developers and researchers, and also hope to work with the community to promote the rapid development and business implementation of NLP technology, especially Chinese NLP.
Open source project address: https://github.com/alibaba/EasyNLP
EasyNLP is a Comprehensive and Easy-to-use NLP Toolkit
The main features of EasyNLP are as follows:
- Easy to use and compatible with open source: EasyNLP supports commonly used Chinese NLP data and models, which is convenient for users to evaluate Chinese NLP technology. In addition to providing an easy-to-use and concise PAI command form to call cutting-edge NLP algorithms, EasyNLP also abstracts certain custom modules such as AppZoo and ModelZoo to lower the threshold for NLP applications. Models, including knowledge pre-training models, etc. EasyNLP can seamlessly access huggingface/transformer models, is also compatible with EasyTransfer models, and can improve training efficiency with the help of the distributed training framework (based on Torch-Accelerator) that comes with the framework.
- Large model and small sample landing technology: The EasyNLP framework integrates a variety of classic small-sample learning algorithms, such as PET, P-Tuning, etc., to achieve small-sample data tuning based on large models, so as to solve the problem that the large model does not match the small training set. In addition, the PAI team combined the classical small-sample learning algorithm and the idea of comparative learning, and proposed a scheme called Contrastive Prompt Tuning, which does not add any new parameters or manually set templates and label words, which won the first place in the FewCLUE small-sample learning list. Name, compared to Finetune has more than 10% improvement.
- Large Model Knowledge Distillation Technology: In view of the problem that large model parameters are difficult to implement, EasyNLP provides a knowledge distillation function to help distill large models to obtain efficient small models to meet the needs of online deployment services. At the same time, EasyNLP provides the MetaKD algorithm, which supports meta-knowledge distillation and improves the effect of the student model. In many fields, it can even match the effect of the teacher model. At the same time, EasyNLP supports data enhancement, which can effectively improve the effect of knowledge distillation by enhancing the data in the target field through pre-training models.
Three EasyNLP Framework Features
Overall structure
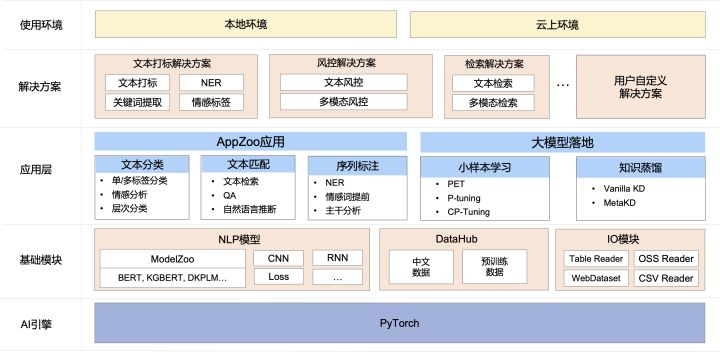
As shown in the figure, the EasyNLP architecture mainly has the following core modules:
- Basic module: Provides a pre-training model library ModelZoo, which supports commonly used Chinese pre-training models, including BERT, MacBERT, WOBERT, etc.; also provides commonly used NN modules to facilitate user-defined models;
- Application layer: AppZoo supports common NLP applications such as text classification, text matching, etc.; EasyNLP supports pre-training model landing tools, including small sample learning and knowledge distillation, to help large models quickly land, and multiple PAI teams are also integrated here. algorithm;
- NLP applications and solutions: Provides multiple NLP solutions and ModelHub models to help users solve business problems;
- Tool layer: It can support local pull-up services, and can also be deployed and invoked on Alibaba Cloud products, such as PAI-DLC, PAI-DSW, PAI-Designer and PAI-EAS, bringing users an efficient process from training to landing. Complete experience.
Large Model Knowledge Distillation Technology
With pre-trained language models such as BERT achieving SOTA effects on various tasks, large-scale pre-training models have become an important part of the NLP learning pipeline, but such models have too many parameters and slow training and inference speeds , which seriously affects online scenarios that require high QPS, and the deployment cost is very high. The EasyNLP framework integrates classic data augmentation and knowledge distillation algorithms, so that the trained small model can approximate the effect of the large model in the corresponding task behavior.
Since most of the existing knowledge distillation work focuses on the distillation of the same domain model, the improvement of the effect of the cross-domain model on the target distillation task is ignored. The PAI team further proposed the meta-knowledge distillation algorithm MetaKD (Meta Knowledge Distillation), which learns the transferable knowledge across domains, and additionally distills the transferable knowledge in the distillation stage. The MetaKD algorithm significantly improves the effect of the learned student model in the corresponding field, approaching the effect of the teacher model. The core framework of this algorithm is shown below:
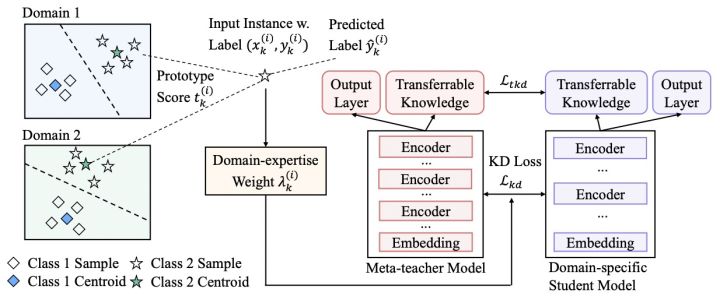
Among them, the MetaKD algorithm includes two stages. The first stage is the meta-teacher learning stage. The algorithm learns the meta-teacher model collaboratively from the training data in multiple fields. Samples with cross-domain typicality have more weight in the learning stage. The second stage is the meta-distillation stage, which selectively distills the meta-teacher model to domain-specific learning tasks. Since the meta-teacher model may not be able to achieve accurate prediction effects in all fields, we additionally introduce a domain-expertise weight, so that the meta-teacher model only transfers the knowledge with the highest confidence to the student model. Avoid overfitting of the student model to the meta-teacher model.
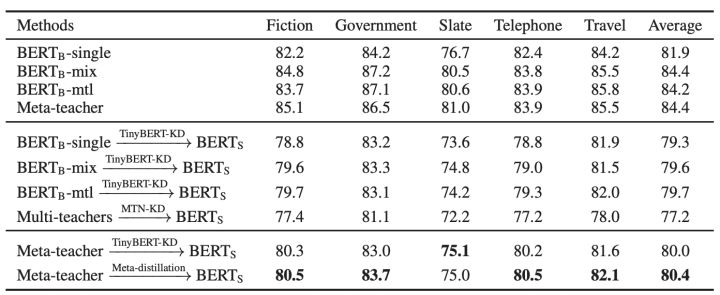
The figure below shows the cross-task distillation effect of the MetaKD algorithm on MNLI’s 5 domain datasets. It can be seen from the results that compared with the original BERT model, the parameters of the BERT-Small model distilled by MetaKD are reduced by 87% on the premise that the model accuracy value is only reduced by 1.5% on average, which greatly reduces the pressure of deployment.
At present, the MetaKD algorithm has also been integrated into the EasyNLP framework and is open source.
For the practice of knowledge distillation, see: https://github.com/alibaba/EasyNLP
Large model small sample learning technology
The expansion of the scale of pre-trained language models has made this type of model more effective in related tasks such as natural language understanding. However, the parameter space of these models is relatively large. If these models are directly fine-tuned on downstream tasks, in order to achieve better model generalization, more training data is required. In actual business scenarios, especially in vertical fields and specific industries, the problem of insufficient training samples is widespread, which greatly affects the accuracy of these models in downstream tasks. In order to solve this problem, the EasyNLP framework integrates a variety of classic small-sample learning algorithms, such as PET, P-Tuning, etc., to achieve small-sample data tuning based on pre-trained language models, so as to solve the problem of large models and small training sets. matching problem.
In addition, the PAI team combined the classical small-sample learning algorithm and the idea of comparative learning, and proposed a scheme Contrastive Prompt Tuning (CP-Tuning) that does not add any new parameters or manually set templates and label words. The core framework of this algorithm is shown below:
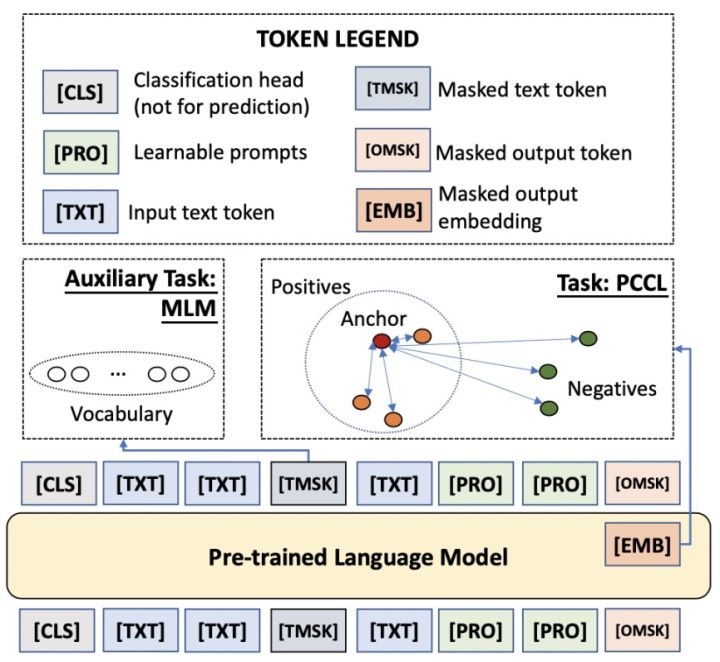
As shown in the figure above, the CP-Tuning algorithm abandons the classic algorithm with “”[MASK]”Character corresponds to the prediction output of the pre-training model MLM Head as the classification basis, but refers to the idea of contrastive learning. After passing the sentence through the pre-training model, it is marked with “[MASK]” character is used as features after the continuous representation of the pre-trained model. In the training phase of the small sample task, the training goal is to minimize the intra-group distance of the features of the same sample and maximize the inter-group distance of the non-homogeneous samples. In the above figure,[OMSK]which is what we use to classify the “[MASK]” character, its optimized features are represented as[EMB]. Therefore, the CP-Tuning algorithm does not need to define the label words for classification.On the input side, in addition to the input text and[OMSK]we also added the template character[PRO].Different from the classical algorithm, since CP-Tuning does not need to learn the correspondence between templates and label words, we directly[PRO]Initialized to a task-agnostic template, such as “it is”. During model training,[PRO]The representation of can be automatically updated during backpropagation.In addition, CP-Tuning also introduces the Mask of the input text, which is expressed as[TMSK], which is used to optimize auxiliary MLM tasks at the same time and improve the generalization of the model in small-sample learning scenarios. The loss function of the CP-Tuning algorithm consists of two parts:
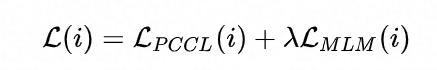
As shown above, the two parts are Pair-wise Cost-sensitive Contrastive Loss (PCCL) and auxiliary MLM loss. We perform validation on multiple GLUE few-shot datasets, where the training set is limited to only 16 annotated samples per class. It can be seen from the following results that the accuracy of CP-Tuning surpasses the classical few-shot learning algorithm and is more than 10% more accurate than the standard Fine-tuning algorithm.
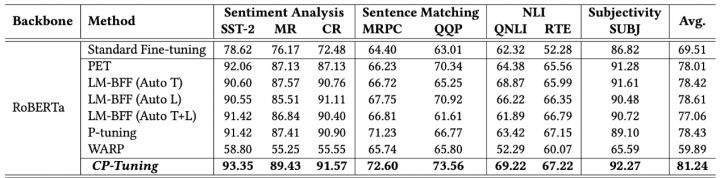
At present, in addition to our self-developed CP-Tuning algorithm, the EasyNLP framework integrates a variety of classic small-sample learning algorithms such as PET, P-tuning, etc.
See the practice of small sample learning: https://github.com/alibaba/EasyNLP/tree/master/examples/fewshot_learning
Large model landing practice
Below we give an example of landing a large pretrained model (hfl/macbert-large-zh) on a small sample scene and distilling it to a small model with only 1/100th of the parameters. As shown in the figure below, the original Accuracy of a large model (300 million parameters) in a small-sample scenario is 83.8%, which can be increased by 7% to 90.6% through small-sample learning. At the same time, if you run this scene with a small model (3 million parameters), the effect is only 54.4%, which can increase the effect to 71% (about 17% increase), and the inference time is 10 times higher than that of the large model. The model parameters are only 1/100 of the original.
| Model | parameter quantity | Dev Set Indicator (Accuracy) | Batch Inference time | |
| Standard Finetune | hfl/macbert-large-en | 325 Million | 0.8375 | 0.54s |
| Standard Finetune | alibaba-pai/pai-bert-tiny-en | 3 Million | 0.54375 | 0.06s |
| Knowledge Distillation Finetune | alibaba-pai/pai-bert-tiny-en | 3 Million | 0.7125 | 0.06s |
| Small sample Finetune | hfl/macbert-large-en | 325 Million | 0.90625 | 0.53s |
See the code for details: https://github.com/alibaba/EasyNLP/tree/master/examples/landing_large_ptms
Applications
EasyNLP supports more than 20 businesses in 10 BUs within the Alibaba Group. At the same time, it has passed PAI products such as PAI-DLC, PAI-DSW, PAI Designer and PAI-EAS, bringing group users an efficient and complete experience from training to landing. At the same time, it also supports the needs of customers on the cloud to customize models and solve business problems. For public cloud users, for entry-level users, the PAI-Designer component can complete NLP model training through simple parameter adjustment. For advanced developers, you can use AppZoo to train NLP models, or use the preset pre-training model ModelZoo for finetune. Senior developers, provide rich API interfaces, support users to use the framework for customized algorithm development, you can use our own Trainer to improve training efficiency, or you can customize a new Trainer.
Here are a few typical cases:
- The PAI team andDharma Academy NLP TeamCooperate to build a large pre-training model (tens of billions of parameters), and launch the self-developed small sample learning algorithm CP-Tuning and model sparse algorithm CAP. Among them, this self-developed CP-Tuning algorithm is integrated with the AliceMind platform to realize small-sample learning of super-large pre-training models. In small-sample scenarios, the accuracy is improved by more than 10% compared to the standard Fine-tune;
- The PAI team and DAMO Academy jointly won the championship on the FewCLUE small sample learning list, and even the accuracy of a small sample learning task surpassed that of humans. At the same time, a BU in Alibaba used the business data in the ToB customer service scenario to learn a small sample learning algorithm under the EasyNLP framework. Compared with the Baseline in terms of business data, the accuracy of entity recognition was improved by more than 2%, and the accuracy of attribute recognition was improved. 5% or more;
- Aiming at the small model and high QPS requirements of public cloud customers for the text classification function, based on the knowledge distillation function of the EasyNLP framework, a pre-training model is used as the teacher model (300 million parameters), and the PAI-BERT Chinese small pre-training model is used as the student model. (The parameter amount is 4 million), and this small model is obtained by distillation. The parameter amount is about 1% of the original model, and the accuracy loss is within 10%. Based on this, we integrate the knowledge distillation function to help the large model in Actual business scenarios are implemented;
- In the risk control scenario, we collected about 100 million Chinese pre-training data, and pre-trained a PAI-BERT Chinese model based on EasyNLP, which achieved very good results in the risk control data, increasing the accuracy and Recall rate; based on this, we also launched on the public cloudText Risk Control Solutionlanded in multiple customer scenarios and achieved good results;
- With the continuous emergence of user-generated content such as UGC, the demand for extracting tags from text for fine-grained analysis continues to emerge; using the EasyNLP-based pre-trained Chinese model, the accuracy rate of text tag prediction in more than 300 categories of news data exceeds 80% ; Based on this, we integrated the functions of text label prediction, keyword extraction, and entity word extraction, and launched it on the public cloud.Universal text marking solutionand successfully landed in many typical customer scenarios, serving application scenarios such as intelligent recommendation.
RoadMap
- Benchmark of Chinese CLUE/FewCLUE etc. based on EasyNLP
- Knowledge pre-training technology: Release a series of knowledge pre-training models, dedicated to improving the commonsense and knowledge of pre-training models
- Chinese pre-training model: Release the Chinese-specific SOTA pre-training model to lower the threshold of Chinese pre-training technology
- Multi-modal pre-training: release a multi-modal pre-training model for Chinese
- Chinese data collection and API interface: collect commonly used Chinese data, provide preprocessing and training interfaces
- SOTA Chinese model integration for vertical scenarios: For vertical business scenarios, integrate the best Chinese model
- Publish solutions and PAI components
references
[1] https://github.com/alibaba/EasyNLPNLP
[2] https://github.com/alibaba/EasyNLP/tree/master/examples/knowledge_distillationLP/tree/master/examples/kn
[3] https://github.com/alibaba/EasyNLP/tree/master/examples/fewshot_learning
[4] https://github.com/alibaba/EasyNLP/tree/master/examples/landing_large_ptms
[5]Dharma Academy NLP team: https://github.com/alibaba/AliceMind
[6]Text risk control solution: https://help.aliyun.com/document_detail/311210.html
[7]General text marking solution: https://help.aliyun.com/document_detail/403700.html
Open source project address: https://github.com/alibaba/EasyNLP
To learn more about AI open source projects, please click:https://www.aliyun.com/activity/bigdata/opensource_bigdata__ai
#Alibaba #Cloud #Machine #Learning #PAI #Open #Source #Chinese #NLP #Algorithm #Framework #EasyNLP #Helping #NLP #Large #Model #Landing