
Client AI is an end-to-end intelligence team under the ByteDance industry research architecture. It is responsible for the construction of end-end intelligence AI frameworks and platforms, as well as the research and development of models and algorithms, to develop new scenarios for end-to-end intelligence for ByteDance. Pitaya introduced in this article is a set of end-to-end intelligent engineering links jointly built by ByteDance’s Client AI team and MLX team.
Author|Qin Liang
Over the years, with the development of algorithm design and device computing power, the end-to-end application of AI has gradually shifted from sporadic exploration to large-scale application. In the industry, FAANG and BAT have many landing scenarios, or create a new interactive experience, or improve the efficiency of business intelligence.
Client AI is an end-to-end intelligence team under the ByteDance industry and research architecture. It is responsible for the construction of end-end intelligence AI frameworks and platforms, as well as the research and development of models and algorithms, to open up new business intelligence scenarios for ByteDance.
Pitaya is a set of terminal intelligent engineering links jointly built by ByteDance’s Client AI team and MLX team, providing full link support from development to deployment for terminal intelligent applications.
Pitaya’s vision is to create an industry-leading end-to-end intelligence technology to facilitate the commercial application of byte intelligence. We provide full-link support for end-end intelligent services through AI engineering links; through AI technical solutions, we help businesses improve indicators, reduce costs, and improve user experience.
So far, Pitaya terminal intelligence has provided terminal intelligent support for 30+ scenarios of Douyin, Toutiao, Xigua, novel and other applications, so that the terminal intelligent algorithm package can be valid for trillions of times per day on the mobile phone, while the error rate is controlled within less than 1 in 100,000.

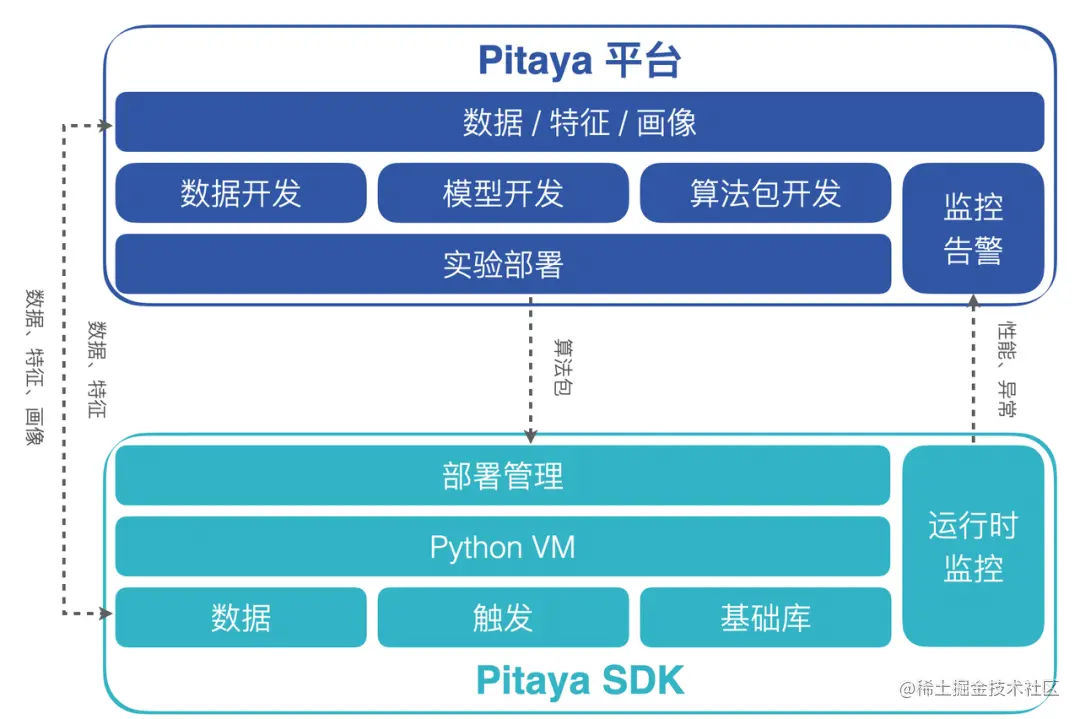
In this section, we will introduce the two core parts of the Pitaya architecture in detail: the Pitaya platform and the Pitaya SDK.
- The Pitaya platform provides a series of framework capabilities such as project management, data access, model development, algorithm development, and algorithm package deployment management for on-device AI. In the process of developing the algorithm strategy on the terminal, the Pitaya platform supports the experiment on the terminal intelligent algorithm strategy on the AB platform to verify the effect of the algorithm strategy. In addition, the Pitaya platform also supports real-time monitoring and alarm configuration of the AI effect on the end, and multi-dimensional analysis and display on the Kanban board.
- The Pitaya SDK provides a running environment on the terminal for the terminal intelligent algorithm package, and supports the high-efficiency operation of the terminal AI on different devices. Pitaya SDK also supports data processing and feature engineering on the terminal, providing the ability to provide version and task management for algorithm packages and AI models, and to monitor the stability and effect of AI running on the terminal in real time.
3.1 Pitaya Workbench
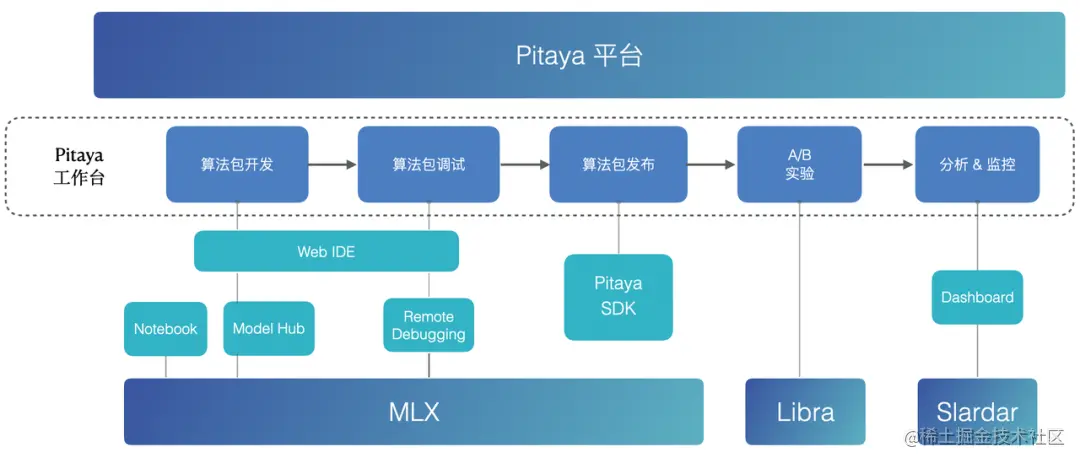
*MLX: Byte Universal Machine Learning Platform
*Libra: Byte large-scale online AB experimental evaluation platform
*Slardar: End-to-end monitoring APM platform with byte performance and experience assurance
The Pitaya platform provides a complete and easy-to-use Pitaya Workbench for algorithm package development, management, debugging, release, deployment, experimentation, and monitoring.
- In order to improve the efficiency of algorithm development, Pitaya Workbench provides algorithm engineers with a development environment that can easily configure data, models, and algorithms.
- In order to simplify debugging, Pitaya Workbench implements real-machine joint debugging on WebIDE, and supports breakpoints, SQL execution and other capabilities.
- In order to verify the effect of the AI strategy, the Pitaya platform has opened up Libra, the A/B experimental platform of Byte, to achieve a more flexible experimental environment setting.
- In order to ensure the effect and stability of on-device AI, the Pitaya platform provides monitoring and alarm capabilities to monitor the performance and success rate of algorithm packages and other operational indicators, as well as on-device model accuracy, AUC and other model effect indicators, and visualize them in Dashboard exhibit.
3.2 Machine Learning Platform
In order to meet the needs of big data processing and deep learning model training, the Pitaya platform is connected to the byte MLX platform to provide a self-developed cloud collaborative notebook solution for general machine learning scenarios.
MLX Notebook has built-in big data computing engines such as Spark 3.0 and Flink, and various resource queues such as local, yarn, K8S, etc., which can combine various data sources (HDFS / Hive / Kafka / MySQL) and various machine learning engines (TensorFlow, PyTorch) , XGBoost, LightGBM, SparkML, Scikit-Learn) are connected. At the same time, MLX Notebook also expands MLSQL operators on the basis of standard SQL, which can compile SQL queries into workflows that can be executed in a distributed manner at the bottom layer, and complete data extraction, processing, model training, evaluation, prediction, and model interpretation. Pipeline build.
4.1 On-device AI environment
4.1.1 On-board virtual machine
The core of Pitaya SDK is the self-developed on-device virtual machine – PitayaVM, which provides the necessary environment for algorithm packages and on-device models to run on mobile phones. In order to allow the virtual machine to run on the terminal and solve the problems of poor performance and large size of the virtual machine on the terminal, Pitaya has made many optimizations to the virtual machine while retaining most of the core functions:
- Lightweight: The package size affects the user update and upgrade rate. By trimming the functions of the kernel and standard library, optimizing the code implementation, and developing self-developed tools to analyze the package volume in detail, the package volume of PitayaVM has been reduced to less than 10% of the original while ensuring the core functions, which is controlled within Within 1MB.
- Efficiency: PitayaVM has been optimized in terms of performance while remaining lightweight. The performance of container operations and numerical statistics scene processing even exceeds the native performance on Android and iOS. At the same time, the virtual machine also supports parallel execution of algorithm codes, which greatly improves the execution efficiency. In addition, PitayaVM also supports optimizing the execution performance on Android through JIT, which can improve the performance by nearly 30% after enabling JIT.
- Security: PitayaVM uses self-developed bytecode and file formats to ensure the security of files and virtual machines.
For product lines that strictly require volume (such as ToB services), you can also use the MinVM solution of the Pitaya SDK. Through the self-developed lightweight interpreter, extreme lightweight optimization is performed on the basis of PitayaVM, and the package size is compressed to less than 100KB.
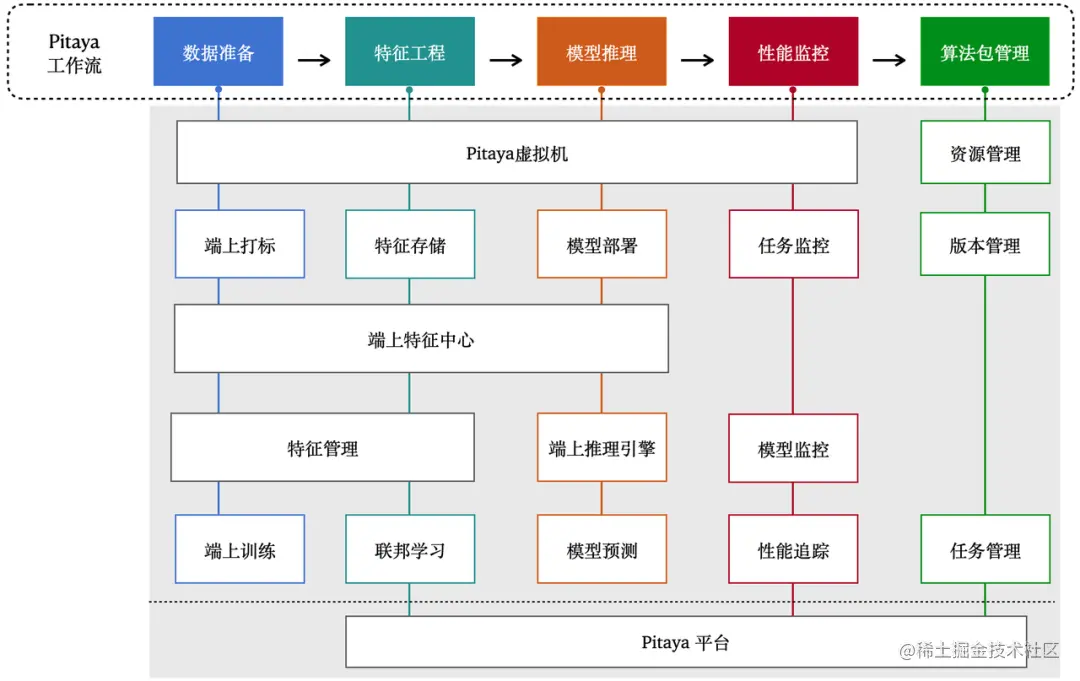
4.2 Core Process of Terminal Intelligence
4.2.1 Data Preparation
The Pitaya SDK provides a range of support for the data preparation process. Provides the ability to obtain feature data from devices, applications, services, on-device feature centers, cloud device portrait platforms, and search promotion modules. At the same time, the Pitaya SDK also supports dynamic labeling on the terminal to label data, improve the quality of training data, and then improve the effect of the model on the terminal.
4.2.2 Feature Engineering on the End
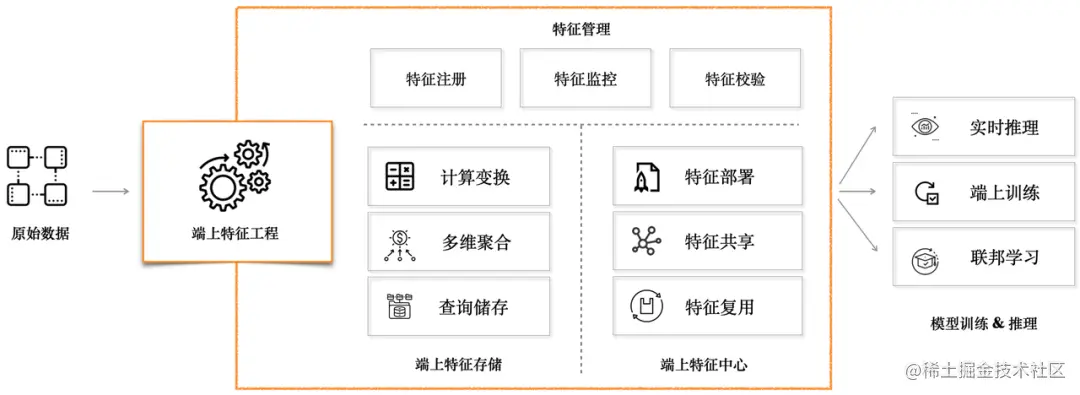
End feature engineering is divided into three main parts: “feature management”, “end feature storage”, “end feature center”.
Feature storage
Pitaya SDK provides feature storage in various ways such as KV and SQL lite, and implements data storage modules similar to Redis and Hive on the end. At the same time, the Pitaya SDK also provides basic libraries such as numpy, MobileCV, MLOps, etc. that are optimized for on-end tailoring, so as to be compatible with data in more formats and provide more complex on-end data processing capabilities.
Pitaya SDK provides high-efficiency, multi-dimensional, long-sequence features and private data permitted by compliance. In addition to supporting a considerable proportion of in-device decision-making, features and samples can be further processed to provide support for cloud model inference and training, and then Supports different on-device smart scenarios such as CV, NLP, and information flow.
end feature center
Pitaya SDK provides an on-device feature center module, which enables different on-device business scenarios to easily and efficiently consume, share, customize, and reuse their own features through multi-dimensional integration and management of rich and diverse feature data on the device. data. The on-device feature center can automatically integrate and produce feature data through time, application life cycle, and even custom sessions in the form of centralized deployment, and then provide it to different modules for use, significantly improving feature development efficiency. At the same time, since the production and consumption of data are both local, the entire process can achieve millisecond-level data timeliness.
Feature management
On-device data sources are abundant and feature production is flexible. Complex and high-level on-device features can be obtained after on-device feature engineering, and secondary feature crossover can be performed before providing them to business scenarios for consumption. In response to this feature of on-device features, Pitaya SDK maintains a set of feature management mechanisms on the device to ensure reliable, maintainable, and traceable upstream and downstream feature production. Also provides the following capabilities:
- On-device feature monitoring: The feature management module establishes a series of calibration and monitoring for on-device features, and monitors on-device feature missing, abnormal eigenvalues, and eigenvalue shifts in real time to ensure the normal production of on-device features.
- On-device feature map: In order to realize cross-team feature sharing and collaboration, the feature management module provides the capability of on-device feature map, so that different business teams can discover, retrieve, contribute and manage features on the device through the feature map. The on-device feature map provides a set of standard specifications for adding and using features, and can maximize the cost of understanding the meaning of features and improve the efficiency of feature construction and reuse by establishing feature groups and adding metadata information to features.
4.2.3 On-device model inference
The Pitaya SDK deeply optimizes the deployment and practical application of AI models on the terminal, and connects the high-performance heterogeneous reasoning engine framework developed by Byte, the machine learning decision tree reasoning engine ByteDT developed by the Client AI team, and the AML team. The Byte TVM engine enables AI models to be rapidly deployed and perform high-performance inference on the end. Currently, the on-device inference engine supported by the Pitaya SDK can cover most on-device AI scenarios and provide complete toolchain support, including:
- High compatibility: It supports converting models trained by mainstream business frameworks (Caffe, Pytorch (ONNX), TensorFlow (tflite), XGBoost, CatBoost, LightGBM, …) into supported model formats and compressing and quantizing them. It covers common OPs in multiple business fields such as CV, Audio, and NLP, and is compatible with all Android and iOS models on the terminal.
- Highly versatile: supports CPU/GPU/NPU/DSP/CUDA and other processors, and can perform optimal selection and scheduling in combination with processor hardware conditions and current system resource occupancy.
- High performance: Support multi-core parallel acceleration and low-bit computing (int8, int16, fp16), reduce power consumption and improve performance, and the overall performance continues to lead the industry.
4.3 Core supporting capabilities of terminal intelligence
4.3.1 Terminal Monitoring
The end monitoring module provides active monitoring of AI time consumption, success rate, market stability and model effect on the end.
During the running of the inference task, the client will automatically monitor the performance of the key links of the algorithm package operation and bury the points, and then report to different platforms for corresponding display of different types of burying points.
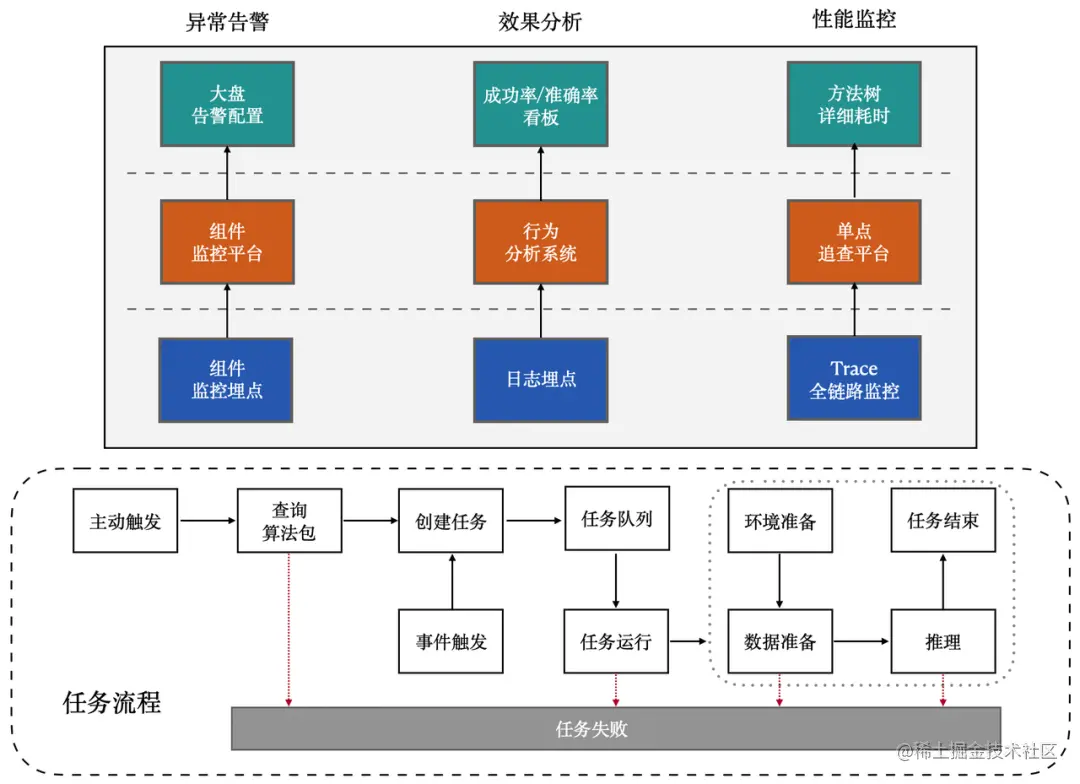
Corresponding to different platforms, terminal monitoring supports:
- On the component monitoring platform, the stability of the broader market is achieved through custom configuration, such as the running time of the overall algorithm package, the number of triggers per capita and other indicators to customize the alarm configuration and alarm frequency.
- On the behavior analysis system, the running results and behaviors of the embedded algorithm package are displayed, and information such as the success rate of the algorithm package operation and the accuracy of model inference are displayed through reports/kanbans.
- On the single-point tracing platform, for the problem that the reasoning takes too long, check the detailed time-consuming of the method tree.
4.3.2 Algorithm Package Management
Resource management Resource management has the ability to update, go offline, and version compatibility of algorithm packages, so that algorithm packages can be automatically and smoothly deployed on the terminal; at the same time, it also maintains a complete set of client-side AI running environment. After a long period of honing, we provide these features:
- Customized delivery: Supports different delivery methods such as on-demand delivery and manual delivery, taking into account availability and user experience.
- Flexible triggering: It supports multiple triggering methods for algorithm packages, and can execute AI models or strategies on the side at the desired time of the business through timing, events, and custom methods.
- Environment isolation: For different environment dependencies of different algorithm packages, as well as the compatibility between different versions of the same dependency, it provides an environment for module isolation; at the same time, it provides module caching and release capabilities, avoiding frequent module switching, and taking into account running speed and memory usage. .
task management
Since both data and models are computed and inferred on the end, there is no network dependency and no network latency. Therefore, the time-consuming of on-device AI is much lower than that of cloud-based AI, so that on-device AI can achieve higher frequency and faster response. Task management is specially designed to correspond to the characteristics of AI on the terminal, and supports a variety of capabilities:
- High concurrency: The task management mode supports multi-task concurrency and multi-thread scheduling to ensure an efficient running environment for AI tasks.
- Circuit breaker protection: In order to ensure the stability of the core business scenarios, the Task Management module supports circuit breaker protection. For algorithm packages that fail to run for N consecutive times or cause crashes for N consecutive times, we will fuse them to temporarily prevent them from running.
- Priority scheduling: When there are many business scenarios, high-frequency triggering of inference tasks may lead to task accumulation. In order to ensure the priority of high-quality tasks, we support scheduling tasks by priority; in addition, in scenarios with high real-time performance, we also support merging intermediate tasks in the pending state to ensure the real-time response of tasks.
- Anti-blocking: The algorithm code is highly dynamic and may introduce an infinite loop. If the inference task containing the infinite loop code is run on the terminal, resources will continue to be occupied. To this end, we have developed a stuck detection function. After detecting an infinite loop, it will exit the infinite loop at the interpreter level, clean up the environment and restore the interpreter to ensure normal task scheduling.
4.3.3 Federated Learning
To protect users’ data privacy, the Pitaya SDK provides the Pitaya federated learning module, which supports training AI models without uploading any private data. In this process, AI model training only relies on the update results of the end-to-end model processed by privacy protection and encryption technology. User-related data will not be transmitted to the cloud for storage, nor can the original data information be reversed, which realizes model training. Decoupling from cloud data storage. In addition, the Pitaya SDK also supports model training, deployment, and iteration directly on the terminal to achieve a user-customized model with thousands of models or thousands of models.
In order to ensure the user experience, Pitaya FL implements a set of automatic scheduling solutions on the terminal. Federated learning training will only be carried out when the device is idle, charged and connected to wifi at the same time. The whole process will not cause any impact on the device.
Pitaya Future Construction
Pitaya, the terminal intelligence architecture of the Byte Client AI team, has provided a complete and mature development platform for the terminal intelligence, and provides complete and easy-to-use functional modules for each link in the terminal intelligence development workflow, and provides in the SDK. Supports industry-leading on-end virtual machines, features, monitoring, and inference engines.
In the next few months, Byte Pitaya will be committed to further building an end-to-end AI engineering link, covering development, iteration, and monitoring processes, and improving the energy efficiency of business AI algorithm research and development. At the same time, we plan to accumulate more reusable AI application capabilities on the terminal intelligent architecture that is currently approaching maturity, realize the efficient migration of AI capabilities between applications and To B, and apply AI on the terminal to large-scale applications.
The Client AI team has been recruiting outstanding talents, including terminal intelligent algorithm engineer, terminal intelligent application engineer (iOS/Android), terminal intelligent data R&D engineer and other positions, so that we can create our own influence in this field. If you have enthusiasm, motivation, and experience for end-to-end intelligence, welcome to join our team and explore the possibility of end-to-end intelligence together~
Contact email: yuanwei.yw@bytedance.com
#Architecture #Design #ByteDance #Terminal #Intelligent #Engineering #Link #Pitaya #Personal #Space #ByteDance #Terminal #Technology #News Fast Delivery