TPU-MLIR is an open source project of TPU compiler focusing on AI chips. It provides a complete tool chain that can convert pre-trained deep learning models under different frameworks into binary files bmodel that can run on TPU. This enables more efficient reasoning.
MLIR (Multi-Level Intermediate Representation) is a new method for building reusable and extensible compilation infrastructure. Developed by Chris Lattner, the original author of LLVM, while working at Google, MLIR aims to make a general, reusable compilation A compiler framework that solves software fragmentation, improves compilation for heterogeneous hardware, and significantly reduces the cost of building domain-specific compilers.
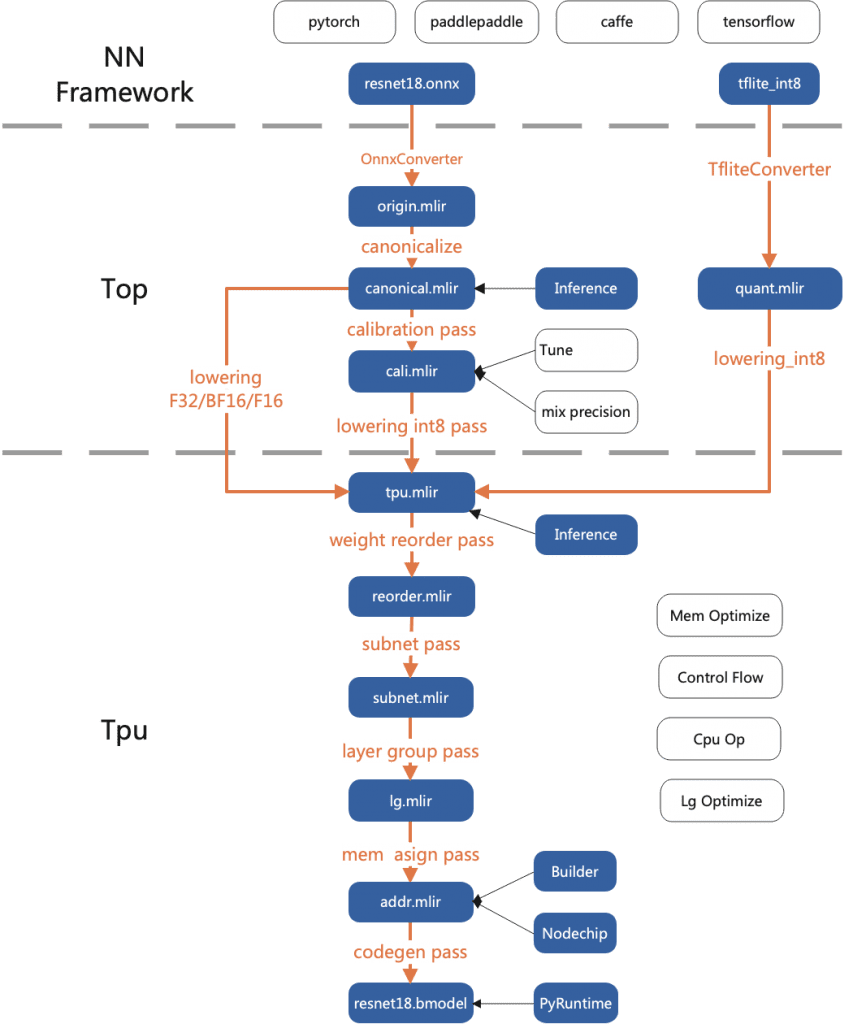
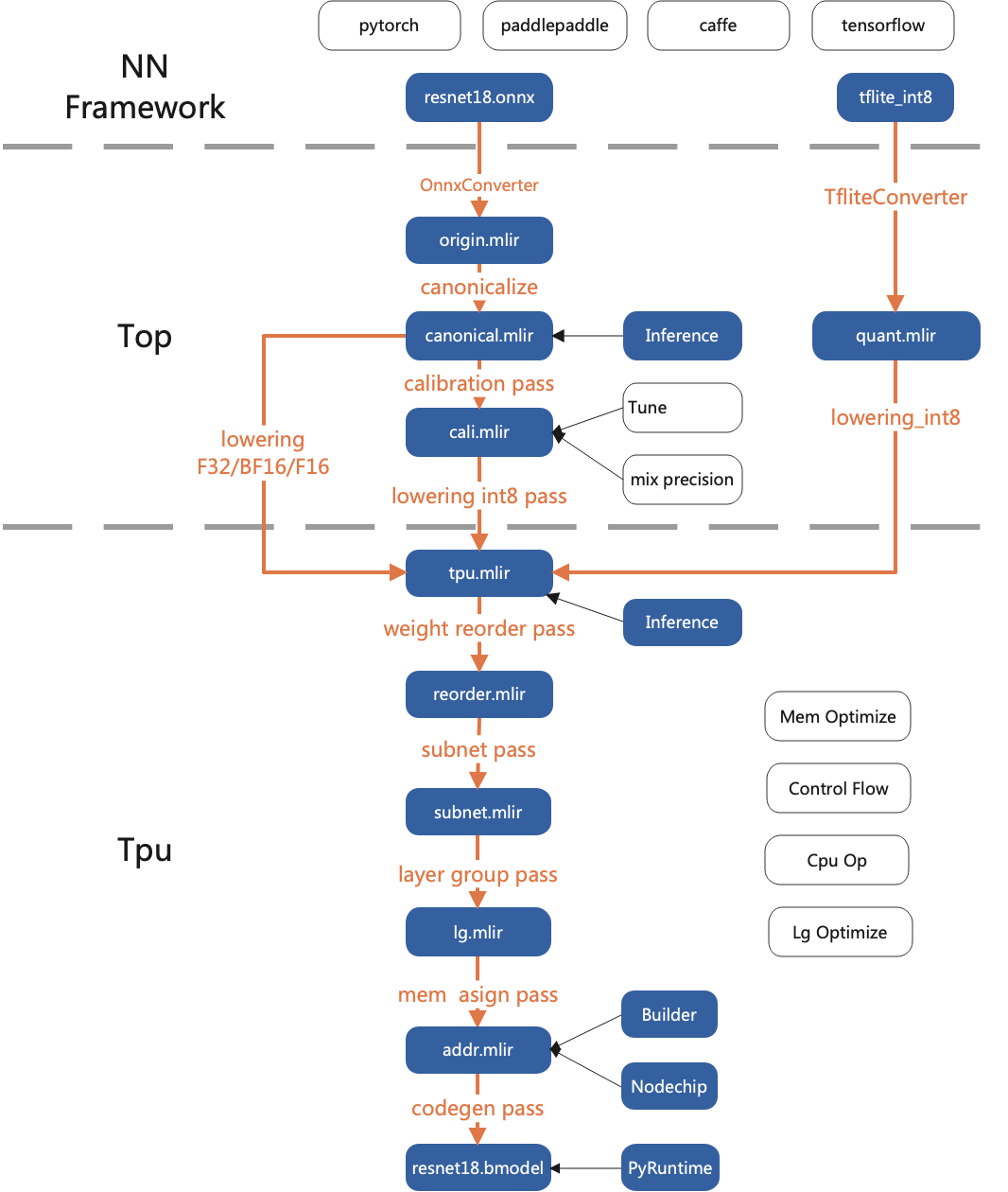
Overall structure
characteristic
Compared with other compilation tools, TPU-MLIR has the following advantages:
- Simple: By reading the development manual and the samples included in the project, users can understand the model conversion process and principles, and get started quickly. Moreover, TPU-MLIR is designed based on the current mainstream compiler tool library MLIR, and users can also learn the application of MLIR through it.
- convenient: This project has provided a complete set of tool chain, users can quickly complete the model conversion work directly through the existing interface, without adapting to different networks.
- Universal: Currently TPU-MLIR already supports TFLite and onnx formats, and the models in these two formats can be directly converted into bmodel available for TPU. What if it wasn’t these two formats? In fact, onnx provides a set of conversion tools that can convert models written by mainstream deep learning frameworks on the market to onnx format, and then continue to convert to bmodel.
- Precision and efficiency coexist: Accuracy may sometimes be lost in the process of model conversion. TPU-MLIR supports INT8 symmetric and asymmetric quantization. While greatly improving performance, it combines the calibration and Tune technologies of the original developer to ensure the high accuracy of the model. Not only that, a large number of graph optimization and operator segmentation optimization techniques are also used in TPU-MLIR to ensure the efficient operation of the model.
#TPUMLIR #Homepage #Documentation #Downloads #TPU #Compiler #News Fast Delivery
TPU-MLIR Homepage, Documentation and Downloads – TPU Compiler – News Fast Delivery