Today, ByteDance announced,Officially open source Cloud Shuffle Service.
Cloud Shuffle Service (hereinafter referred to as CSS) is a general-purpose Remote Shuffle Service framework developed by Bytes. It supports computing engines such as Spark/FlinkBatch/MapReduce, and provides data shuffle with better stability, higher performance and more flexibility than native solutions. At the same time, it also provides a Remote Shuffle solution for scenarios such as separation of storage and computing/offline co-location.
At present, CSS has been open sourced on Github, and interested students are welcome to participate in the joint construction!
project address:https://github.com/bytedance/CloudShuffleService
In big data computing engines, Pull-Based Sort Shuffle is a common shuffle scheme. For example, Spark/MapReduce/FlinkBatch (version 1.15 or higher) all use Sort Shuffle as the default engine scheme, but the implementation mechanism of Sort Shuffle has certain Defect, in the large-scale production environment, the stability of the job is often affected by the Shuffle problem.
Take Spark’s Sort Shuffle as an example:
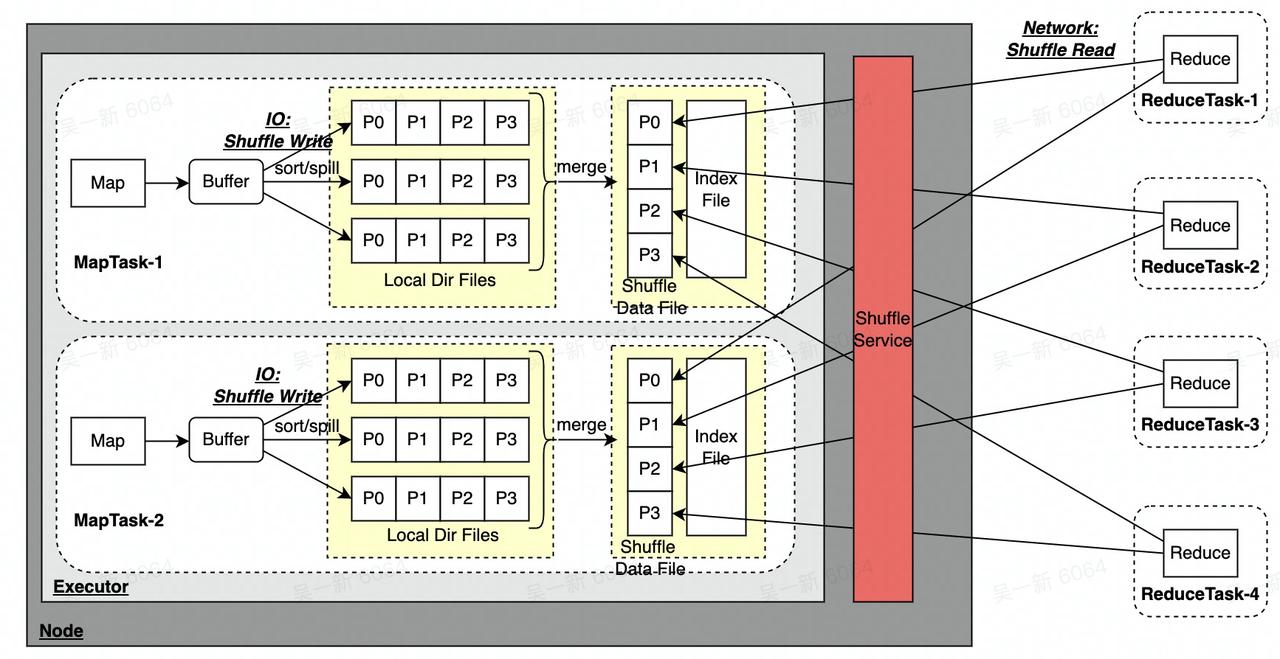
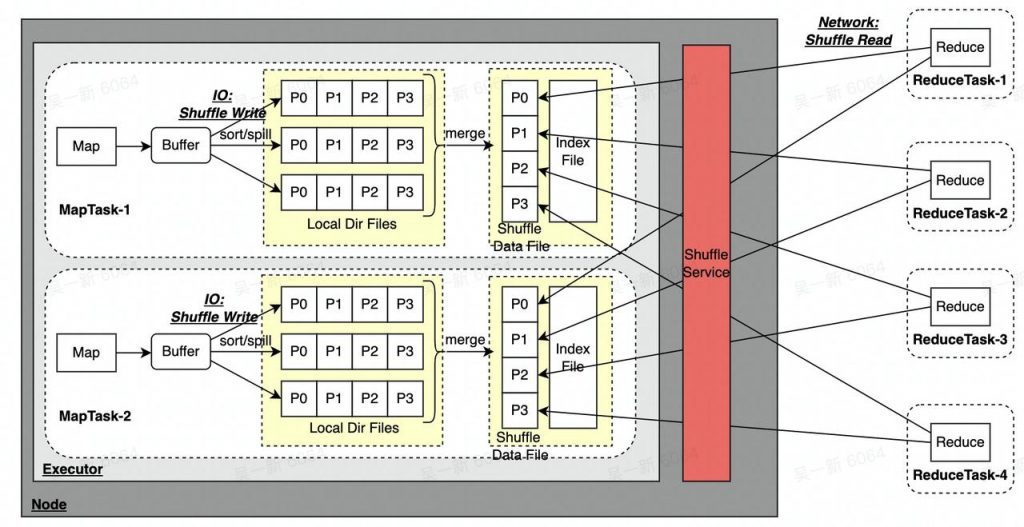
As shown in the link above, Sort Shuffle will have the following problems:
Combining multiple Spill files into one file will consume additional read and write IO;
Assuming that there are m MapTask & n ReduceTask, m*n network links will be generated, when the number is particularly large:
Shuffle Service cannot isolate Application resources. When there is an abnormal job, it may affect all other jobs on the same Shuffle Service node, and the problem is easy to magnify;
Only one copy of the Shuffle Data File generated by MapTask is stored locally. When the disk is damaged, data will be lost, which will also cause the FetchFailed problem;
The way Shuffle Data File is written to the local disk depends on the disk on the computing node and cannot separate storage and computing
These can easily lead to slow ShuffleRead or timeout, cause FetchFailed related errors, and seriously affect the stability of online jobs. Slow ShuffleRead will also greatly reduce resource utilization (CPU & Memory), and FetchFailed will also lead to Recalculation of related tasks in Stage, which is wasteful A large number of resources slow down the operation of the entire cluster; the architecture that cannot separate storage and computing is difficult to meet the requirements in scenarios such as offline co-location (insufficient online resources and disks)/Serverless cloud native.
ByteDance uses Spark as the main offline big data processing engine. There are millions of jobs running online every day, and the average daily shuffle volume is 300+PB. In scenarios such as HDFS co-location & offline co-location, the stability of Spark jobs is often not guaranteed, which affects business SLA:
Restricted HDD disk IO capability/disk failure, etc., lead to a large number of problems such as slow job/failure/Stage recalculation caused by Shuffle FetchFailed, affecting stability and resource utilization
External Shuffle Service (hereinafter referred to as ESS) cannot be separated from storage and calculation. When encountering machines with low disk capacity, the disk is often full, which affects the operation of jobs.
In this context, ByteDance developed CSS to solve the pain points of Spark’s native ESS solution. Since CSS was launched internally for one and a half years, the current number of online nodes is 1500+, and the average daily shuffle volume is 20+PB, which greatly improves the shuffle stability of Spark jobs and guarantees business SLA.
CSS is a Push-Based Shuffle Service developed by Bytes itself. All MapTasks send the Shuffle data of the same Partition to the same CSS Worker node for storage through Push, and the ReduceTask directly reads the Partition’s data from the node through CSS Worker in sequence. Compared with the random read of ESS, the IO efficiency of sequential read is greatly improved.
CSS Architecture
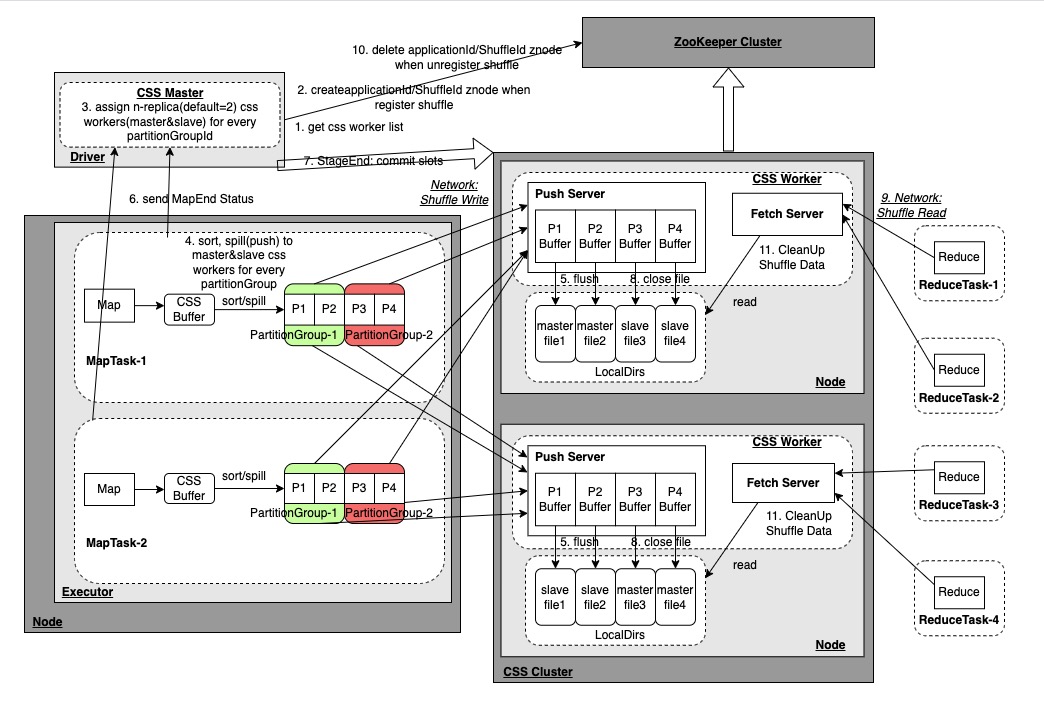
Cloud Shuffle Service (CSS) Architecture Diagram
CSS Cluster is an independently deployed Shuffle Service service. The main components involved are:
After the CSS Worker starts, it will register the node information with the ZooKeeper node. It provides Push/Fetch service requests. The Push service accepts the Push data request from MapTask and writes the data of the same Partition to the same file; the Fetch service accepts requests from ReduceTask Fetch data request, read the corresponding Partition data file and return it; CSS Worker is also responsible for Shuffle data cleaning. When the Driver performs the UnregisterShuffle request to delete the Znode corresponding to the ShuffleId in ZooKeeper, or when the Application ends to delete the Znode of the ApplicationId in ZooKeeper, CSS Workers will Watch related events clean up Shuffle data.
After the job is started, the CSS Master will be started in the Spark Driver. The CSS Master will obtain the CSS Worker node list from ZooKeeper, and then allocate n copies (2 by default) of CSS Worker nodes to each Partition generated by the subsequent MapTask, and then These Meta information are managed for the ReduceTask to obtain the CSS Worker node where the PartitionId is located for pulling. At the same time, during the RegisterShuffle/UnregisterShuffle process, the corresponding ApplicationId/ShuffleId Znode will be created in ZooKeeper, and the CSS Worker will watch the Delete event to clean up the Shuffle data. .
As described above, it is used to store CSS Worker node information and ShuffleId and other information.
CSS features
In addition to supporting Spark (2.x&3.x), CSS can also be connected to other engines. Currently, within ByteDance, CSS is also connected to the MapReduce/FlinkBatch engine.
In order to solve the problem that a single Partition is too small and the Push efficiency is relatively low, multiple consecutive Partitions are actually combined into a larger PartitionGroup for Push.
- Efficient and unified memory management
Similar to ESS, CSS Buffer in MapTask stores all Partition data together, sorts the data according to PartitionId before Spill, and then pushes data according to PartitionGroup dimension; meanwhile, CSS Buffer is fully integrated into Spark’s UnifiedMemoryManager memory management system. Memory-related parameters are managed by Spark uniformly.
Push failed: When triggering Spill to push PartitionGroup data, the data size of each Push is 4MB (one Batch). When a certain Push batch fails, it does not affect the data that has been successfully Pushed before, and only needs to reassign the node (Reallocate) to continue. Push the current failed data and the subsequent data that has not been Pushed, the subsequent ReduceTask will read the complete Partition data from the old and new nodes;
Multiple copy storage:ReduceTask reads a Partition data from CSS Worker according to the batch granularity. When the CSS Worker is abnormal (such as network problem/disk failure, etc.), the batch data cannot be obtained, and you can continue to select another replica node to continue reading The data of this batch and subsequent batches;
data deduplication: When the job opens Speculative speculative execution, there will be multiple AttempTask running concurrently, which needs to be deduplicated when reading. When Push Batch, Header information will be added to the Batch data. The Header information includes MapId + AttempId + BatchId and other information. When the ReduceTask reads, it can be deduplicated according to these ID information.
- Adaptive Query Execution(AQE) adaptation
CSS fully supports AQE-related functions, including dynamically adjusting the number of Reduces/SkewJoin optimization/Join strategy optimization. For SkewJoin, CSS has done more adaptation and optimization work to solve the problem that Skew Partition data is repeatedly read by multiple ReduceTasks, which greatly improves performance.
CSS performance test
We compared CSS and open-source ESS using exclusive Label computing resources for 1TB TPC-DS Benchmark test, and the overall end-to-end performance improved by **15%Left and right, some Query haveMore than 30%** performance improvement.
At the same time, we also use the online co-location resource queue (ESS stability is poor) to conduct the 1TB TPC-DS Benchmark test comparison, and the overall end-to-end performance is improved.4 timesabout.
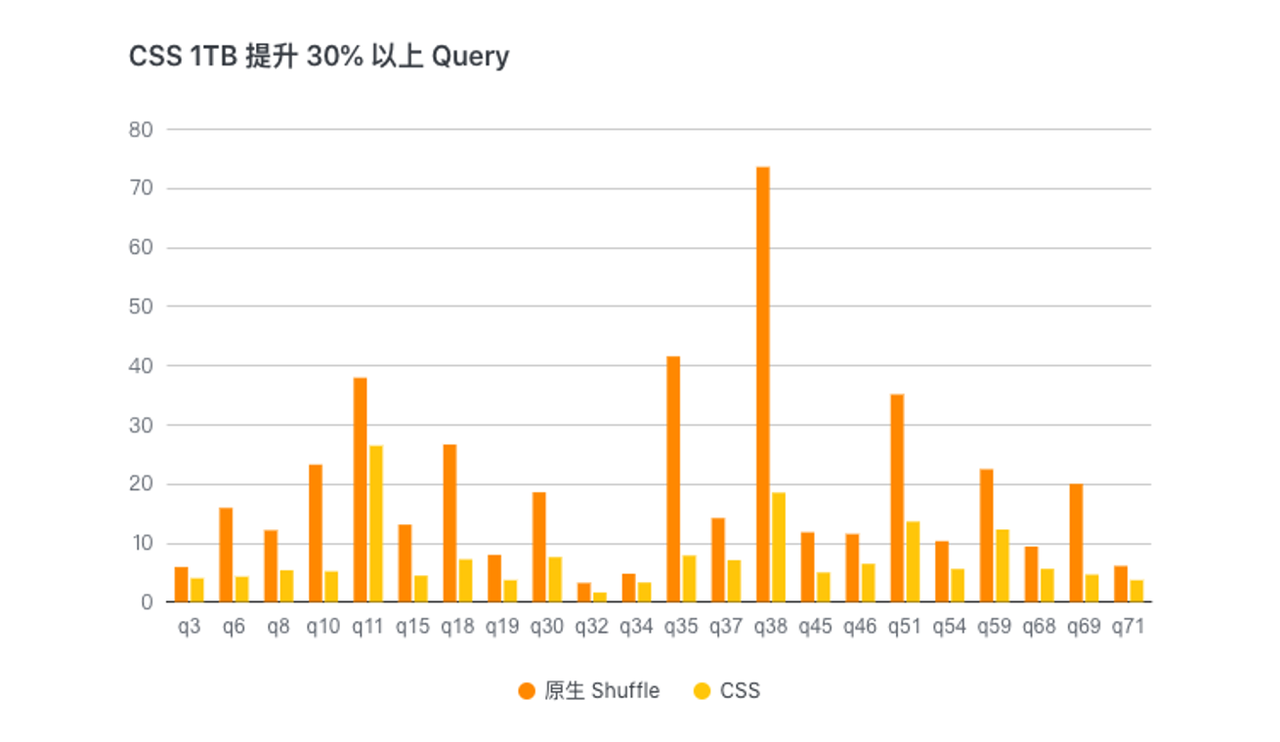
CSS 1TB test improves Query by more than 30%
CSS currently open-sources some features, and some features & optimizations will be opened one after another:
Support MapReduce/FlinkBatch engine;
The CSS cluster adds the ClusterManager service role to manage the status & load information of CSS Workers, and at the same time, the function of assigning CSS Workers to the current CSS Master is mentioned to ClusterManager;
CSS Worker allocation strategy based on dimensions such as heterogeneous machines (such as different disk capacities)/load.
#ByteDance #open #source #selfdeveloped #Shuffle #framework #Cloud #Shuffle #Service #News Fast Delivery
ByteDance open source self-developed Shuffle framework – Cloud Shuffle Service – News Fast Delivery