Macaw-LLM: Multimodal Language Modeling with Image, Video, Audio and Text Integration
Macaw-LLM is an exploratory attempt to pioneer multimodal language modeling by seamlessly combining image, video, audio, and text data, building on CLIP, Whisper, and LLaMA.
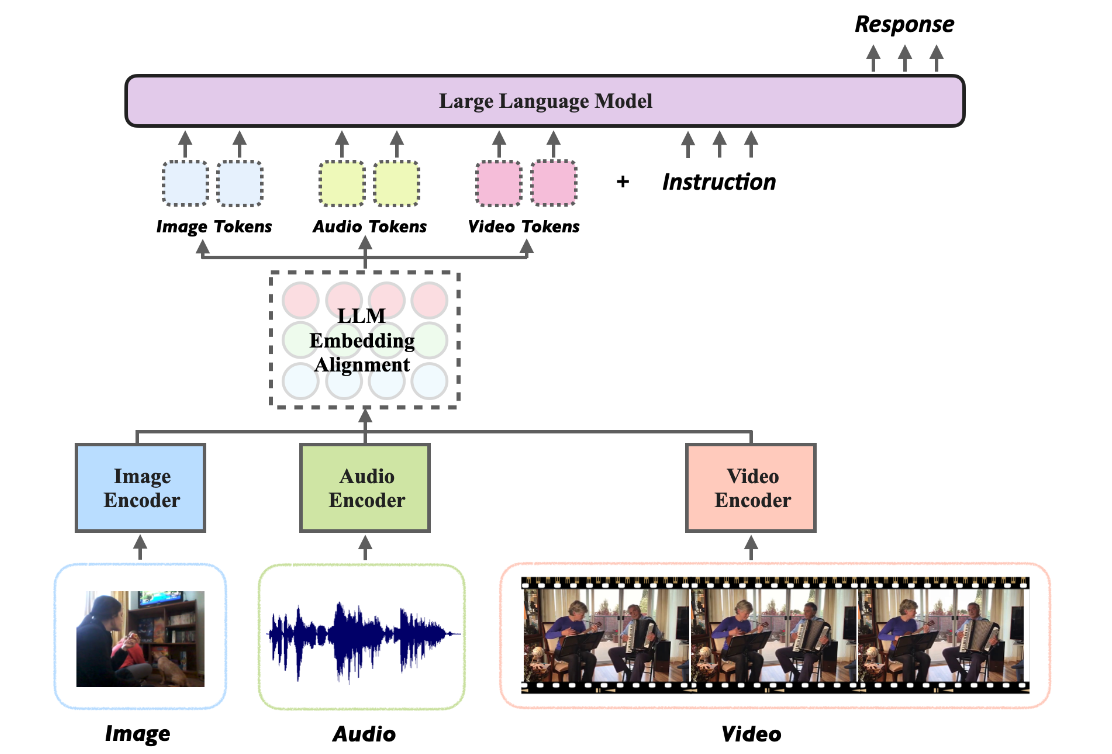
The field of language modeling has made remarkable progress in recent years. However, the integration of multiple modalities such as image, video, audio, and text is still a challenging task. Macaw-LLM is a one-of-a-kind model that brings together state-of-the-art models for processing visual, auditory and textual information, namely CLIP, Whisper and LLaMA.
Macaw-LLM has the following unique features:
- Easy and Quick Alignment: Macaw-LLM enables seamless integration of multimodal data through simple and fast alignment with LLM embeddings. This efficient process ensures fast adaptation to different data types.
- Single-stage instruction fine-tuning: Our model simplifies the adaptation process through single-stage instruction fine-tuning, facilitating a more efficient learning experience.
Macaw-LLM consists of three main parts:
- CLIP: Responsible for encoding images and video frames.
- Whisper: Responsible for encoding audio data.
- LLM (LLaMA/Vicuna/Bloom): A language model that encodes instructions and generates responses.
The integration of these models enables Macaw-LLM to efficiently process and analyze multimodal data.
#MacawLLM #Homepage #Documentation #Downloads #Multimodal #Language #Modeling #News Fast Delivery