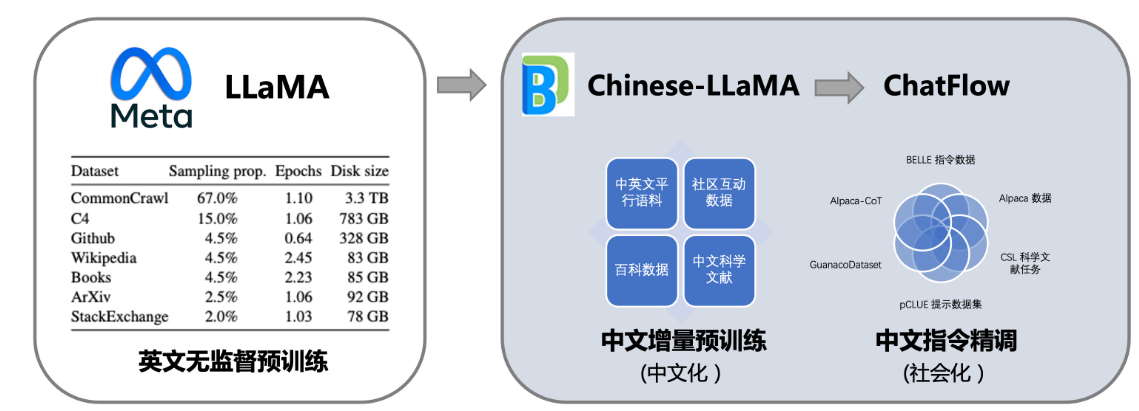
This project provides the community withChinese dialogue model Linly-ChatFlow, Chinese basic model Linly-Chinese-LLaMA and their training data.model based on Tencent Pretrain The pre-training framework is realized, and the full-tuning on 32 * A100 GPU will gradually open up the Chinese model weights of 7B, 13B, 33B, and 65B scales. The Chinese basic model is based on LLaMA, and uses Chinese and Chinese-English parallel incremental pre-training to transfer its strong language ability in English to Chinese. Further, the project summarized the currently public multilingual instruction data, conducted large-scale instruction following training on the Chinese model, and realized the Linly-ChatFlow dialogue model.
In addition, this project will make public the training from scratch Linly-Chinese-OpenLLaMA The model is pre-trained on 1TB Chinese and English corpus, and is optimized for Chinese using words and tokenizers. The model will be released under the Apache 2.0 protocol.
Project Features
- Obtain the Chinese LLaMA model through Full-tuning (full parameter training), providing TencentPretrain and HuggingFace versions
- Summarize Chinese open source community instruction data and provide the largest Chinese LLaMA model
- Model details are open and reproducible, providing complete process codes for data preparation, model training and model evaluation
- Multiple quantization schemes to support CUDA and edge device deployment inference
- Train Chinese-OpenLLaMA from scratch based on public data, and optimize words and tokenizers for Chinese (in progress)
Chinese pre-training corpus | Chinese instruction fine-tuning dataset | Model quantitative deployment | Domain fine-tuning example
Model download
Terms and Conditions
Model weights are based on GNU General Public License v3.0 Agreement, for research use only, not for commercial purposes.Please confirm that you haveget permissionUse the models in this repository under the premise of .
7B:Base model Linly-Chinese-LLaMA-7B| Dialogue model Linly-ChatFlow-7B| int4 quantized version Linly-ChatFlow
13B:Base model Linly-Chinese-LLaMA-13B| Dialogue model Linly-ChatFlow-13B
33B:33B base model
65B: in training
HuggingFace model
7B base model | 13B base model | 33B base model
7B Dialogue Model | 13B Dialogue Model
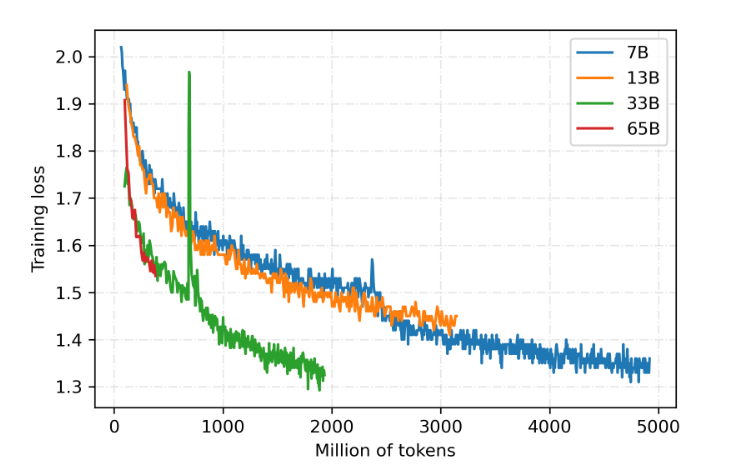
training situation
The model is still being iterated, and the project regularly updates the model weights.
limitation
Linly-ChatFlow is completely trained based on community open corpus, and the content has not been manually corrected. Limited by the size of the model and training data, Linly-ChatFlow’s current language ability is weak and is still improving. The development team stated that it has observed that Linly-ChatFlow has obvious flaws in scenarios such as multiple rounds of dialogue, logical reasoning, and knowledge questions, and may also produce biased or harmful content.
In addition, since the same pre-training target (causal LM) is used in the incremental training and instruction fine-tuning stages, it is found that in some cases the model will continue to write instructions (for example, semantic understanding-Q4-13B), which is planned to be resolved in the next version this problem.
#Linly #Homepage #Documentation #Downloads #Large #Scale #Chinese #Language #Model #News Fast Delivery