VLE (Vision-Llanguage E.ncoder) is an image-text multimodal understanding model based on pre-trained text and image encoders, which can be applied to multimodal discriminative tasks such as visual question answering and image-text retrieval. In particular, VLE achieves the best performance among public models in the Visual Commonsense Reasoning (VCR) task, which has stronger requirements on language understanding and reasoning ability.
Online demo address:https://huggingface.co/spaces/hfl/VQA_VLE_LLM
The VLE model adopts a dual-stream structure, similar to the structure of the METER model, consisting of two single-modal encoders (image encoder and text encoder) and a cross-modal fusion module. The structural differences between VLE and METER are:
- VLE uses DeBERTa-v3 as a text encoder, which outperforms RoBERTa-base used in METER.
- In VLE-large, the hidden dimension of the cross-modal fusion module is increased to 1024 to increase the capacity of the model.
- In the fine-tuning stage, VLE introduces an additional token type vector representation.
pre-training
VLE uses graphs and texts to pre-train data. In the pre-training phase, VLE uses four pre-training tasks:
- MLM (Masked Language Modeling): Mask prediction task. Given a picture-text pair, some words in the text are randomly masked, and the training model restores the masked text.
- ITM (Image-Text Matching): Image-text matching prediction task. Given an image-text pair, train the model to determine whether the image and text match.
- MPC (Masked Patch-box Classification): Masking the patch classification task, given the image-text pair, and masking out the patch containing the specific object in the picture, and training the model to predict the masked object type.
- PBC (Patch-box classification): Patch classification task. Given a picture-text pair, predict which patches in the picture are related to the text description.
VLE performed 25,000 steps of pre-training on 14M English text-to-text data, and the batch size was 2048. The figure below shows the model structure of VLE and some pre-training tasks (MLM, ITM and MPC).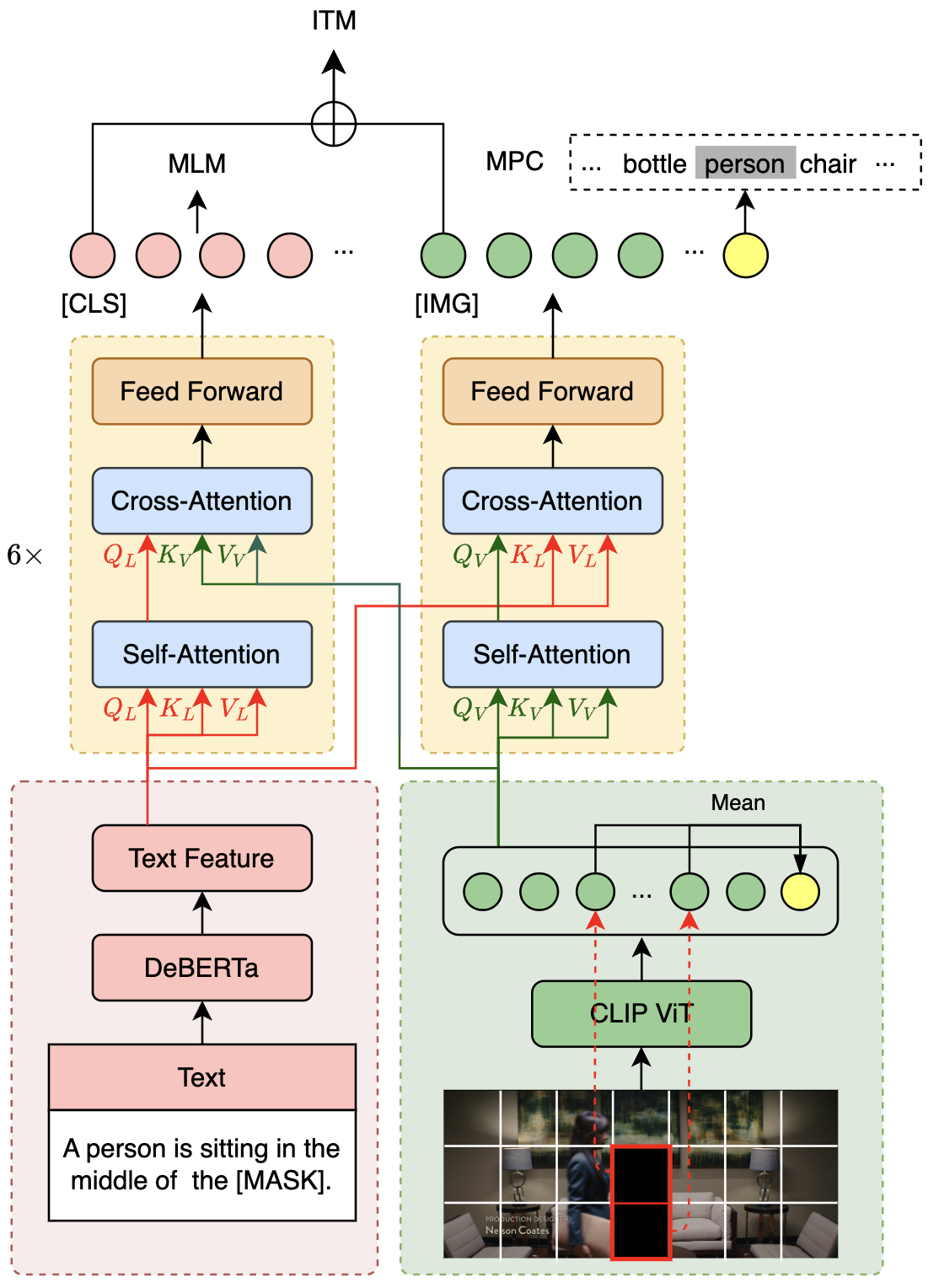
Downstream Task Adaptation
Visual Question Answering (VQA)
- Following standard practice, the model is trained using the VQA training set and validation set, and validated on the test-dev set. The output of the pooler of the fusion layer of the model is used to train the classification task.
Visual Commonsense Reasoning (VCR)
- VCR is formatted as a RACE-like multiple-choice task, and for each object in an image, the average pooled value of the representations of the patches covering that object is added to the sequence of image features prior to the fusion module. Additional token_type_ids are also added for objects in images and text to inject alignment information between different modalities and improve the alignment performance of the model.
Model download
Two versions of the pre-training model, VLE-base and VLE-large, are released this time. The model weights are in PyTorch format. You can choose to manually download the weights and configuration files from the ???? transformers model library, or use them in the code from_pretrained(model_name) to load the model automatically.Detailed method to participatemodel use.
pretrained weights
| Model | text encoder | image encoder | parameter amount* | MODEL_NAME | Link |
|---|---|---|---|---|---|
| VLE-base | DeBERTa-v3-base | CLIP-ViT-base-patch16 | 378M | hfl/vle-base | link |
| VLE-large | DeBERTa-v3-large | CLIP-ViT-large-patch14 | 930M | hfl/vle-large | link |
* : Only parameters for encoder and emebddings are calculated. The amount of parameters of the task-specific prediction layer is not accounted for.
fine tune weights
| Model | text encoder | image encoder | MODEL_NAME | Link |
|---|---|---|---|---|
| VLE-base-for-VQA | DeBERTa-v3-base | CLIP-ViT-base-patch16 | hfl/vle-base-for-vqa | link |
| VLE-large-for-VQA | DeBERTa-v3-large | CLIP-ViT-large-patch14 | hfl/vle-large-for-vqa | link |
| VLE-base-for-VCR-q2a | DeBERTa-v3-base | CLIP-ViT-base-patch16 | hfl/vle-base-for-vcr-q2a | link |
| VLE-large-for-VCR-q2a | DeBERTa-v3-large | CLIP-ViT-large-patch14 | hfl/vle-large-for-vcr-q2a | link |
| VLE-base-for-VCR-qa2r | DeBERTa-v3-base | CLIP-ViT-base-patch16 | hfl/vle-base-for-vcr-qa2r | link |
| VLE-large-for-VCR-qa2r | DeBERTa-v3-large | CLIP-ViT-large-patch14 | hfl/vle-large-for-vcr-qa2r | link |
Model comparison
The parameters, pre-training data, and downstream task effects of VLE, METER, and other multimodal models are compared in the table below. Among them, VQA shows the effect on the test-dev set; VCR shows the effect on the dev set.
| Model | VQA | VCR (QA2R) | VCR (Q2A) | Parameter amount | Pre-training data volume* |
|---|---|---|---|---|---|
| CoCa | 82.3 | – | – | 2.1B | unknown |
| BeiT-3 | 84.2 | – | – | 1.9 B | 21M(IT) + 14M(I) + 160G(T) |
| OFA | 82.0 | – | – | 930M | 20M(IT) + 39M(I) + 140G(T) |
| BLIP | 78.3 | – | – | 385M | ~130M(IT) |
| METER-base | 77.7 (76.8†‡) | 79.8§ | 77.6§ | 345M | 9M(IT) |
| METER-Huge | 80.3 | – | – | 878M | 20M(IT) |
| VLE-base | 77.6‡ | 83.7§ | 79.9§ | 378M | 15M(IT) |
| VLE-large | 79.3‡ | 87.5§ | 84.3§ | 930M | 15M(IT) |
† : Reproduce effect
‡ : Fine-tuning parameters: lr=7e-6, batch_size={256, 512}, num_epochs=10
§ : Fine tuning parameters: lr=1e-5, batch_size=128, num_epochs=5
* : IT: Text. I: Image. T: Text.
Observing the above table, we can find that:
- VLE pre-training is more efficient: Compared with similarly sized models, VLE uses less pre-trained data and achieves comparable or even better results on visual question answering.
- VLE has stronger reasoning capabilities: In particular, VLE significantly outperforms METER with a similar structure on the Visual Commonsense Reasoning (VCR) task, which requires higher reasoning ability.
#VLE #Homepage #Documentation #Downloads #VisionLanguage #Multimodal #PreTraining #Model #News Fast Delivery