Primus is a general-purpose distributed training scheduling framework for machine learning applications, which manages the training life cycle and data distribution of machine learning frameworks (such as Tensorflow, Pytorch), and helps the training framework to obtain better distributed capabilities.
Function
-
Multiple training framework support: Tensorflow, PyTorch, Monolith, etc.;
-
Multi-scheduler support: YARN, Kubernetes, etc.;
-
Multi-role support: such as PS-Chief-CPU, Worker-GPU, Worker-Evaluator, etc., and supports special scheduling strategies such as affinity and anti-affinity among multiple roles;
-
Multi-orchestration strategy: supports simultaneous startup, one-by-one startup, role-based sequential startup, etc. (for example, start PS first, then start Worker);
-
Fault-tolerant processing: Worker failure automatically pulls up a new Worker, PS failure overall failure;
-
Dynamic scheduling: for example, it supports dynamic expansion and reduction of the number of workers;
-
Multi-data source data type support: HDFS, Kafka, etc.;
-
Data load balancing and state preservation: Supports dynamic distribution of tasks according to Worker load, such as supporting recycling and redistribution of Tasks when Worker fails;
-
Multi-threaded high-speed data reading: Support multi-threaded reading of HDFS and Kafka and then output to the trainer, improving the throughput of a single trainer.
architecture
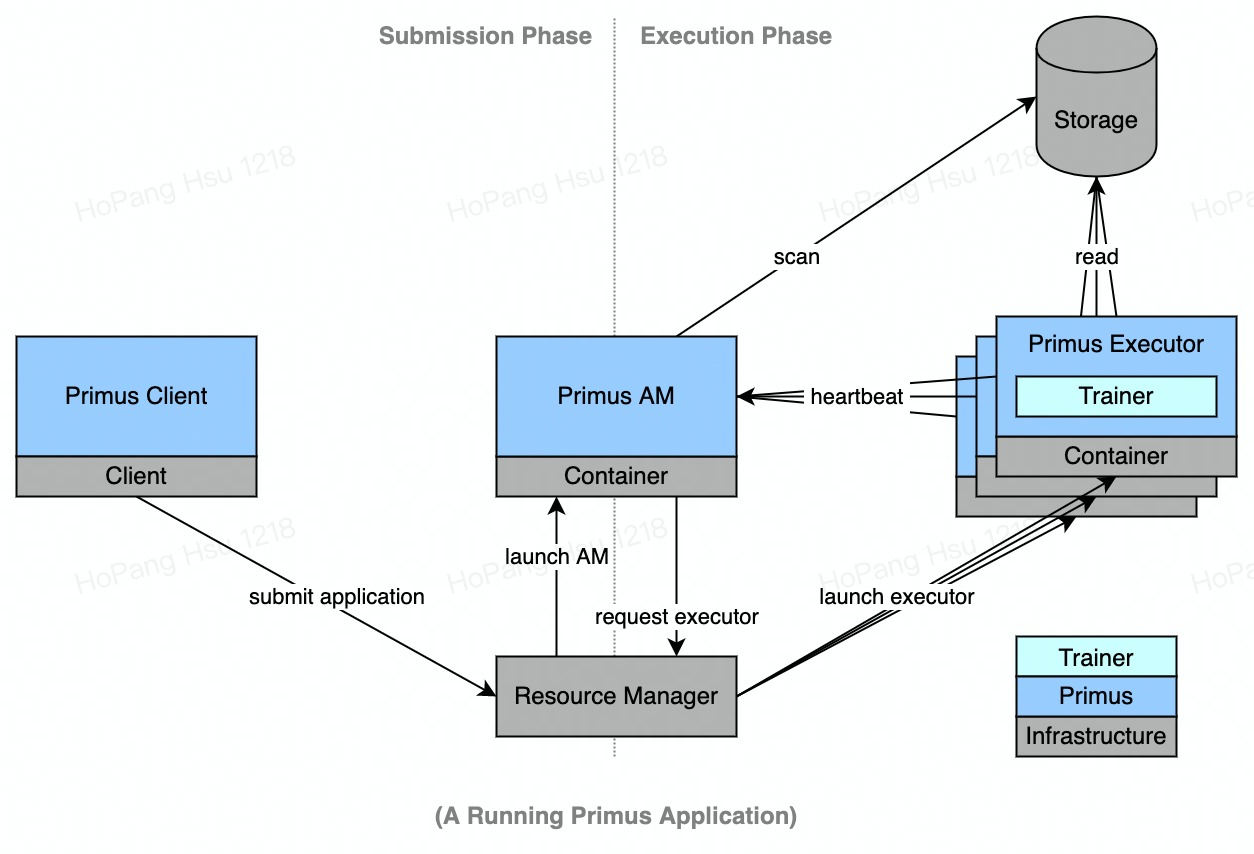
#Primus #Homepage #Documentation #Downloads #Distributed #Training #Scheduling #Framework #News Fast Delivery