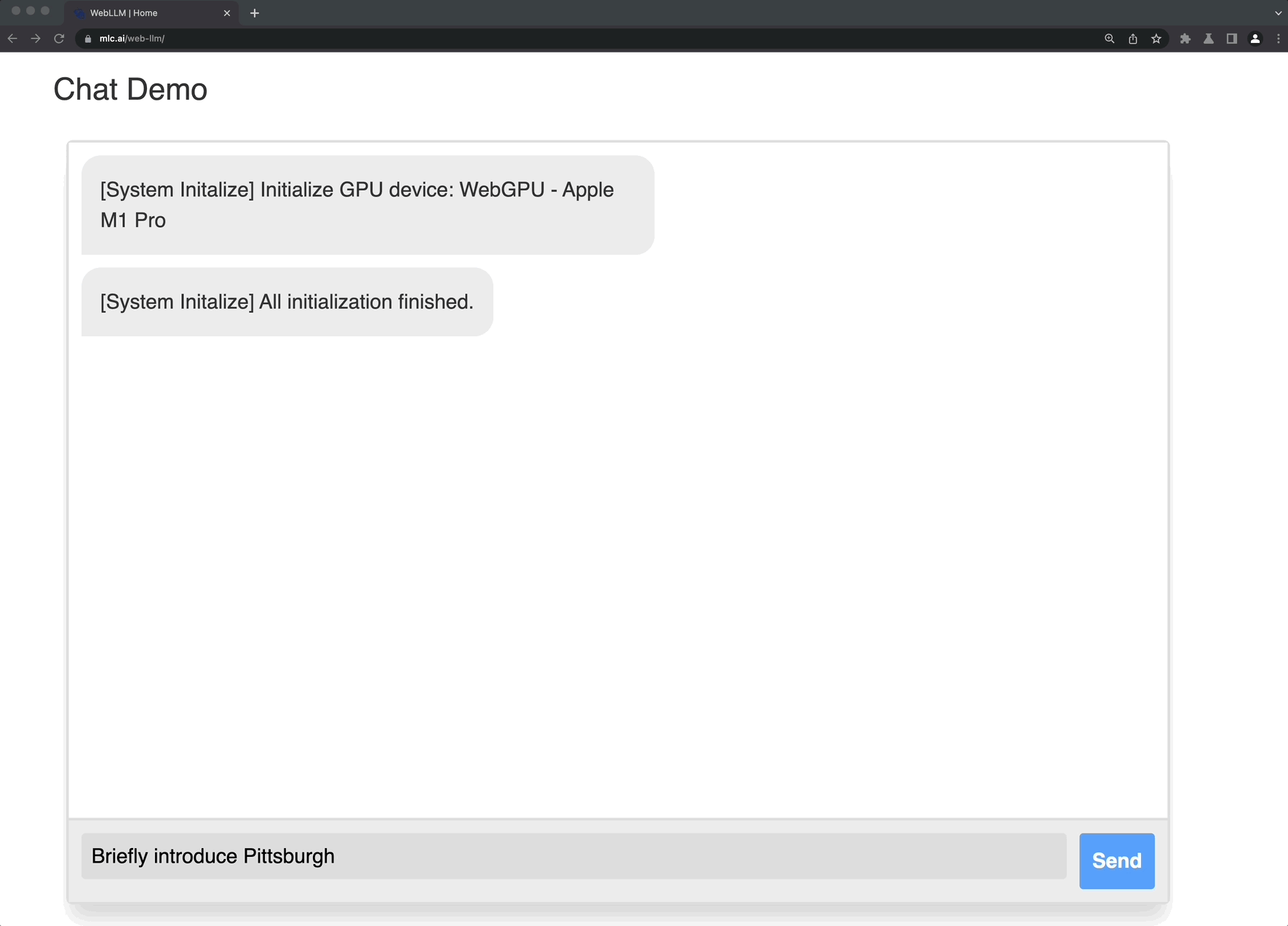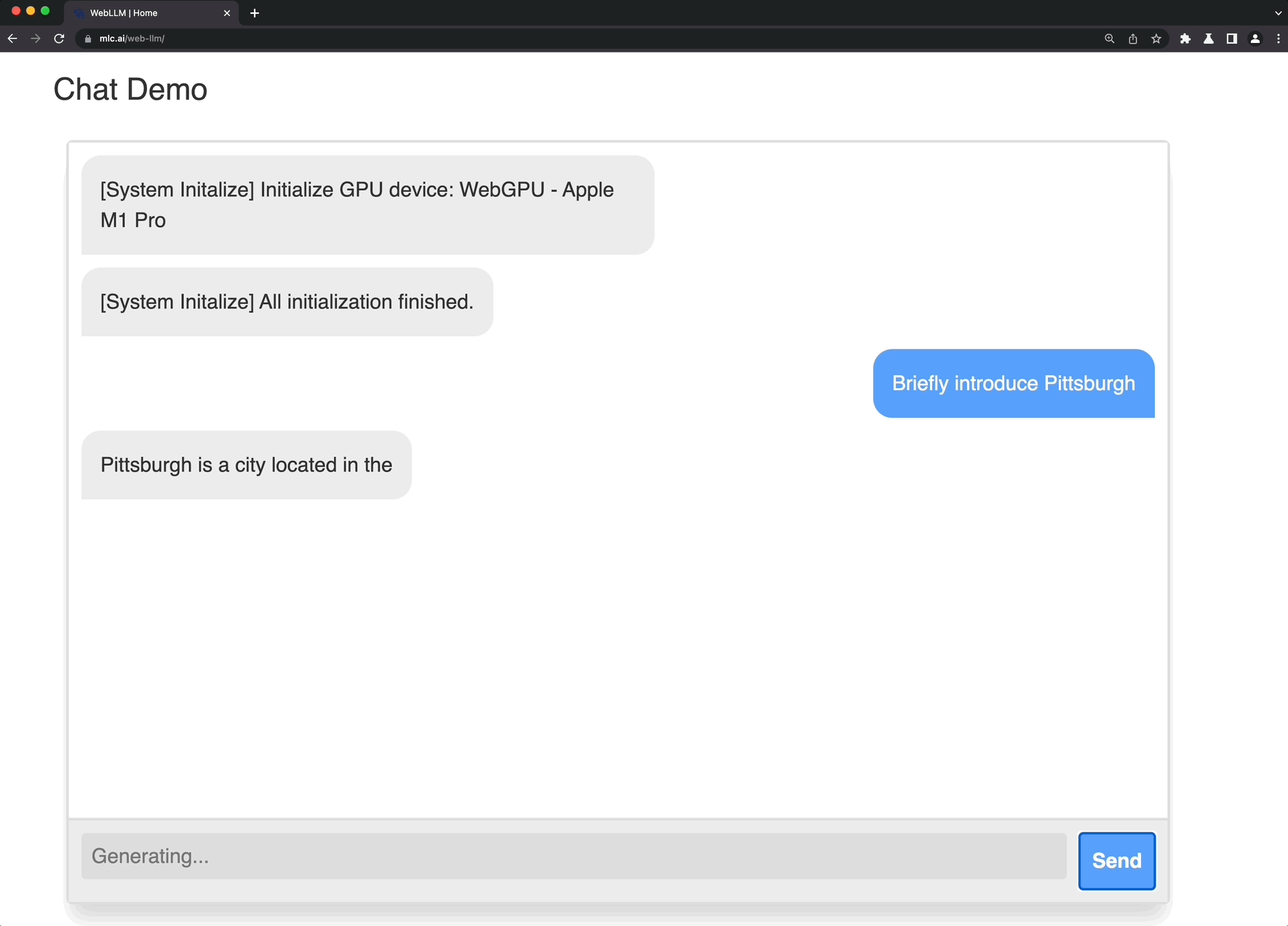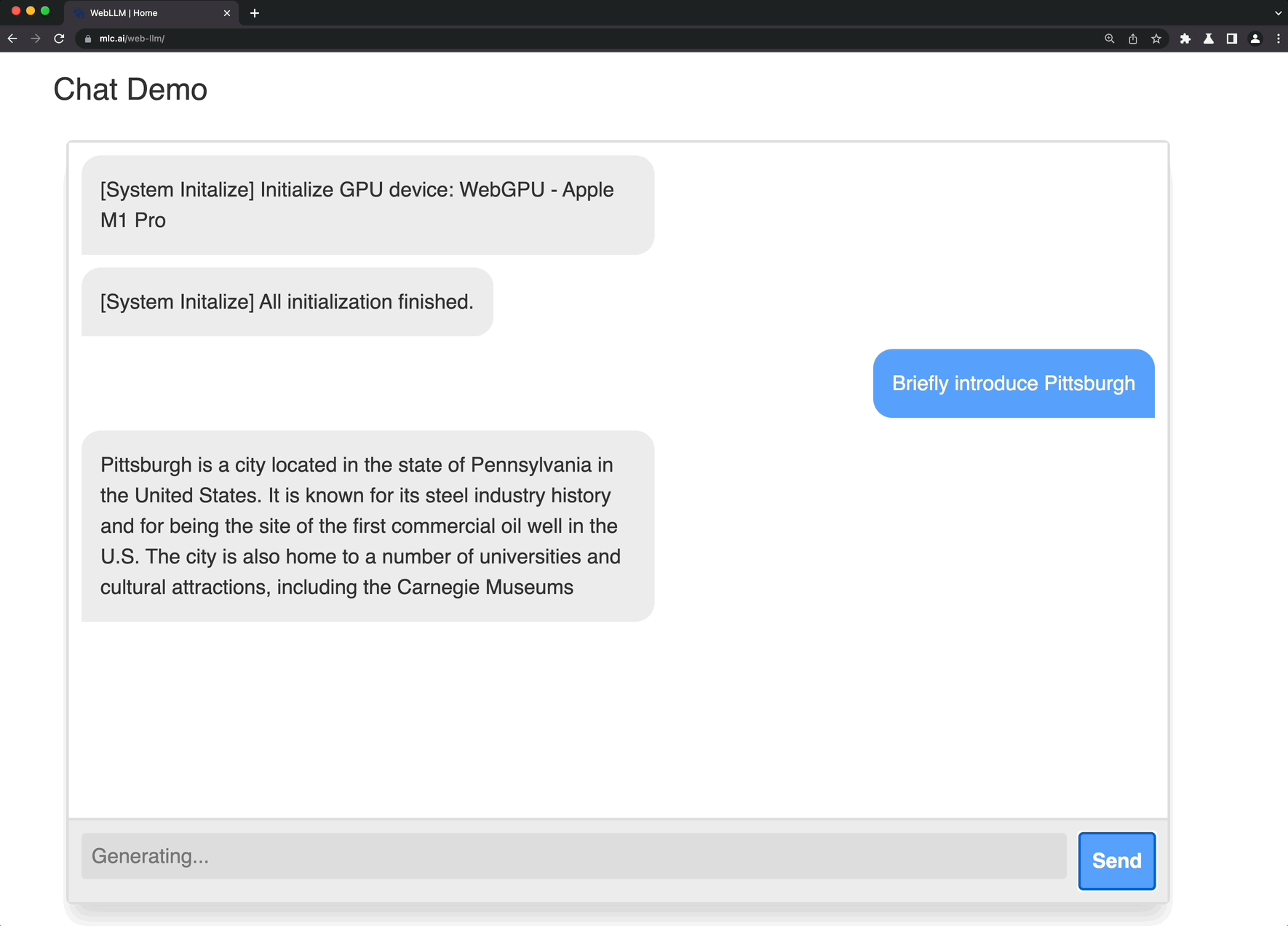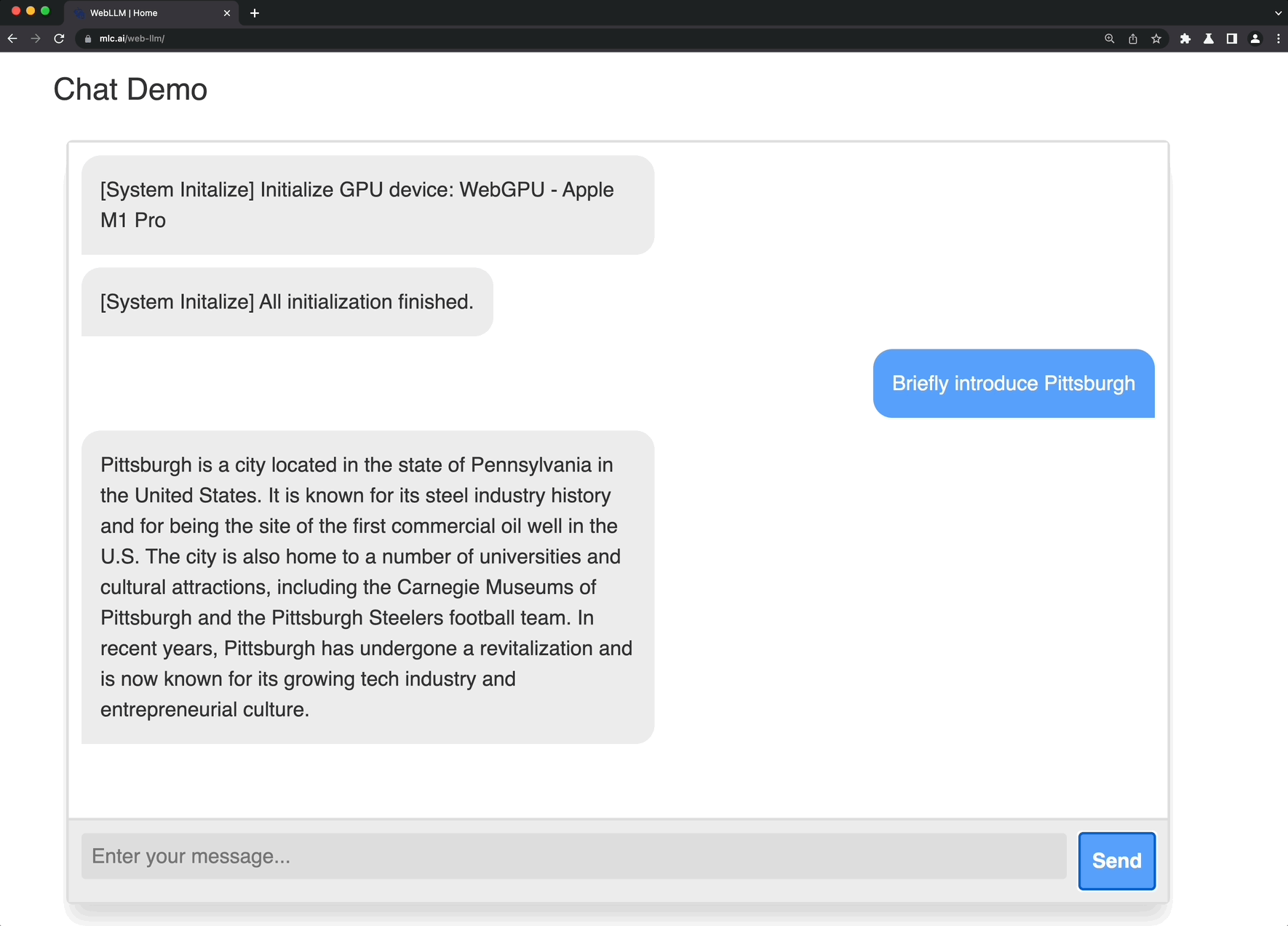
Web LLM is aA project to bring large-scale language models and LLM-based chatbots to web browsers.Everything runs in the browser, requires no server support, and is accelerated using WebGPU. This opens up many interesting opportunities to build AI assistants for everyone and achieve privacy while enjoying GPU acceleration.
Check out the demo page to try it out
Adopted in Web LLMThe key technology is Machine Learning Compilation (MLC). The solution is built on an open source ecosystem including Hugging Face, model variants from LLaMA and Vicuna, wasm and WebGPU; the main pipeline is built on top of Apache TVM Unity.
- Baking the language model’s IRModule in a TVM with native dynamic shape support avoids the need to pad to a maximum length and reduces computation and memory usage.
- Each function in TVM’s IRModule can be further transformed and produce runnable code that can be universally deployed in any environment supported by the minimal tvm runtime (JavaScript is one of them).
- TensorIRIt is a key technique for generating optimized programs. The development team provides an efficient solution by combining expert knowledge and an automatic scheduler to quickly convert TensorIR programs.
- Heuristics are used to optimize lightweight operators to reduce engineering stress.
- Utilizes int4 quantization technique to compress model weights so they can fit in memory.
- Build static memory planning optimizations to reuse memory across multiple tiers.
- useEmscriptenand TypeScript to build a TVM web runtime that can deploy the generated modules.
- Also leverages the wasm port of the SentencePiece tokenizer.
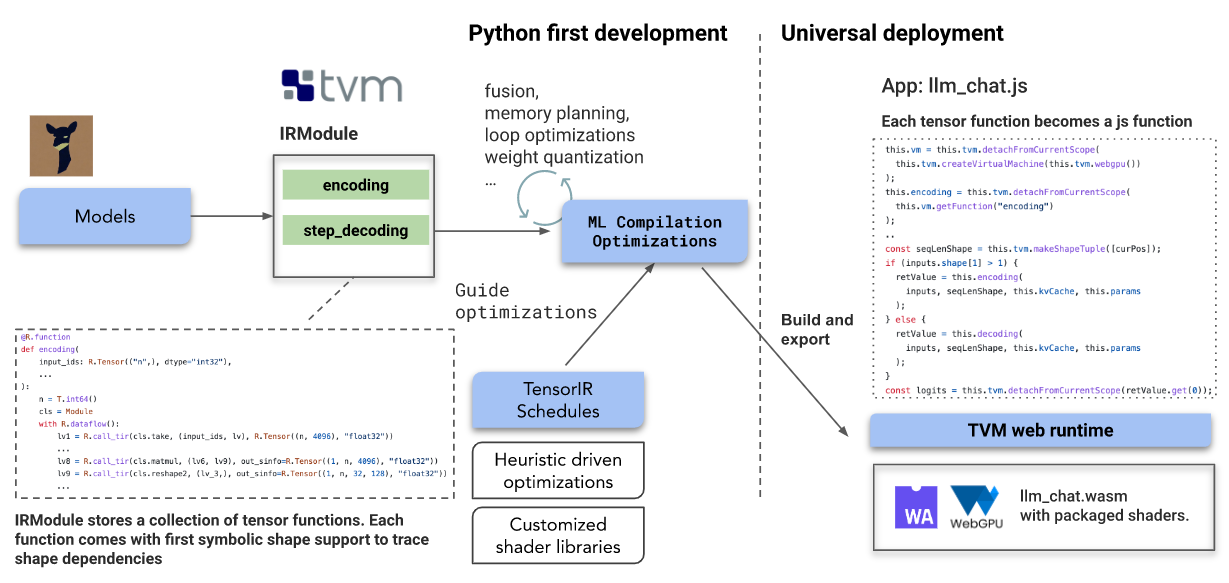
Specifically, the team made heavy use of TVM unitywhich implements this Python-first interactive MLC development experience, making it easy to write new optimizations.
TVM unity also provides an easy way to compose new solutions in the ecosystem.Web LLM The development team will continue to bring further optimizations, such as fusing quantization kernels, and bring them to more platforms.
A key feature of LLM models is the dynamic nature of the model. Since the decoding and encoding process relies on computations that grow with token size,Web LLM teamTake advantage of the first-class dynamic shape support in TVM unity, representing sequence dimensions via signed integers. Makes it possible to plan ahead and statically allocate all the memory needed for the sequence window of interest without filling.
Ensembles of tensor expressions are also exploited to quickly express partial tensor computations, such as direct rotation embeddings, without materializing them as full tensor-matrix computations.
In addition to the WebGPU runtime, Web LLM also provides the option to use a native GPU runtime for native deployment. So they can be used both as a tool to deploy on a native environment and as a reference point to compare the performance of native GPU drivers and WebGPU.
#Web #LLM #Homepage #Documentation #Downloads #Bringing #Language #Model #Chat #Web #Browser #News Fast Delivery