- Time-Frequency Transformation
- spectrum rearrangement
- cepstral coefficient
- Deconvolution
- spectral features
- Music Information Retrieval
audioFlux is a library implemented in Python and C. It provides systematic, comprehensive, and multi-dimensional feature extraction and combination in the audio field. It combines various deep learning network models to conduct business research and development in the audio field. The following is from time-frequency transformation, spectrum rearrangement, Six aspects of cepstral coefficient, deconvolution, spectral features, and music information retrieval briefly explain their related functions.
In the field of time-frequency analysis, audioFlux includes the following general transformation (supporting all subsequent frequency scale types) algorithms:
BFT – Based on Fourier transform.
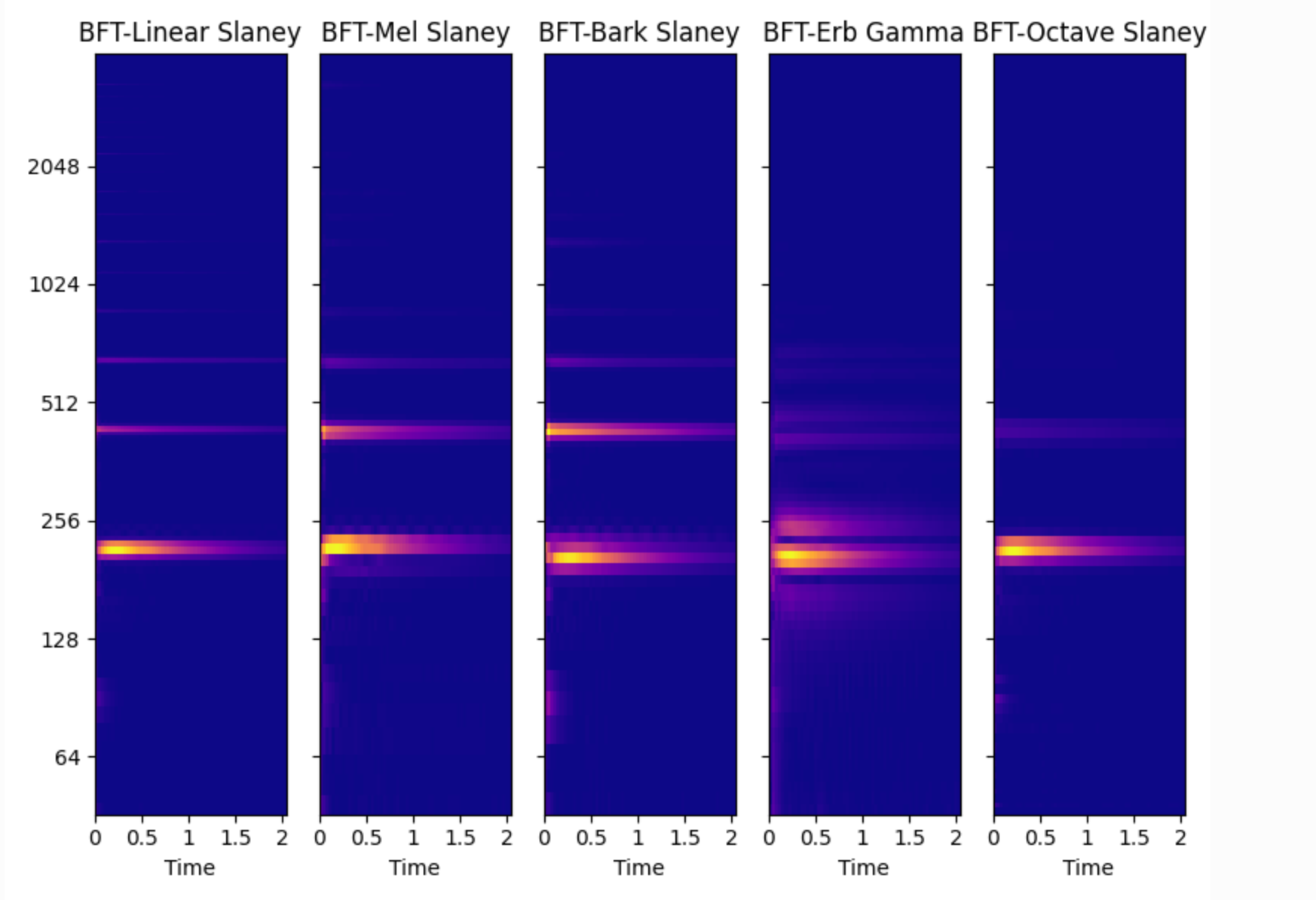
The equivalent short-time Fourier transform (STFT), generally based on this to realize the well-known mel spectrum, the Fourier transform of overlapping translation and windowing in the time domain, generally the overlapping transform length is 1/4, and the Gaussian window is also called Gabor Transformation, the length of the window function can be adjusted to conveniently simulate the characteristics of time-frequency analysis. In addition to providing standard mel/bark/erb spectrum, the BFT algorithm also supports complex spectrum of scale types such as mel, and supports the rearrangement of scale spectrum such as mel .
NSGT – Non-stationary Gabor transform.
Similar to the STFT (short-time Fourier transform) with a Gaussian window, the difference is that the length of the window function and t establish a non-stationary relationship. Compared with STFT, it can achieve a better analysis of the non-stationary state in the steady-state signal, and a better onset endpoint The detection effect is often based on this kind of spectrum calculation, and it can be used as an efficient way to realize CQT. The octave frequency scale type of NSGT transformation in this algorithm is the efficient realization of CQT.
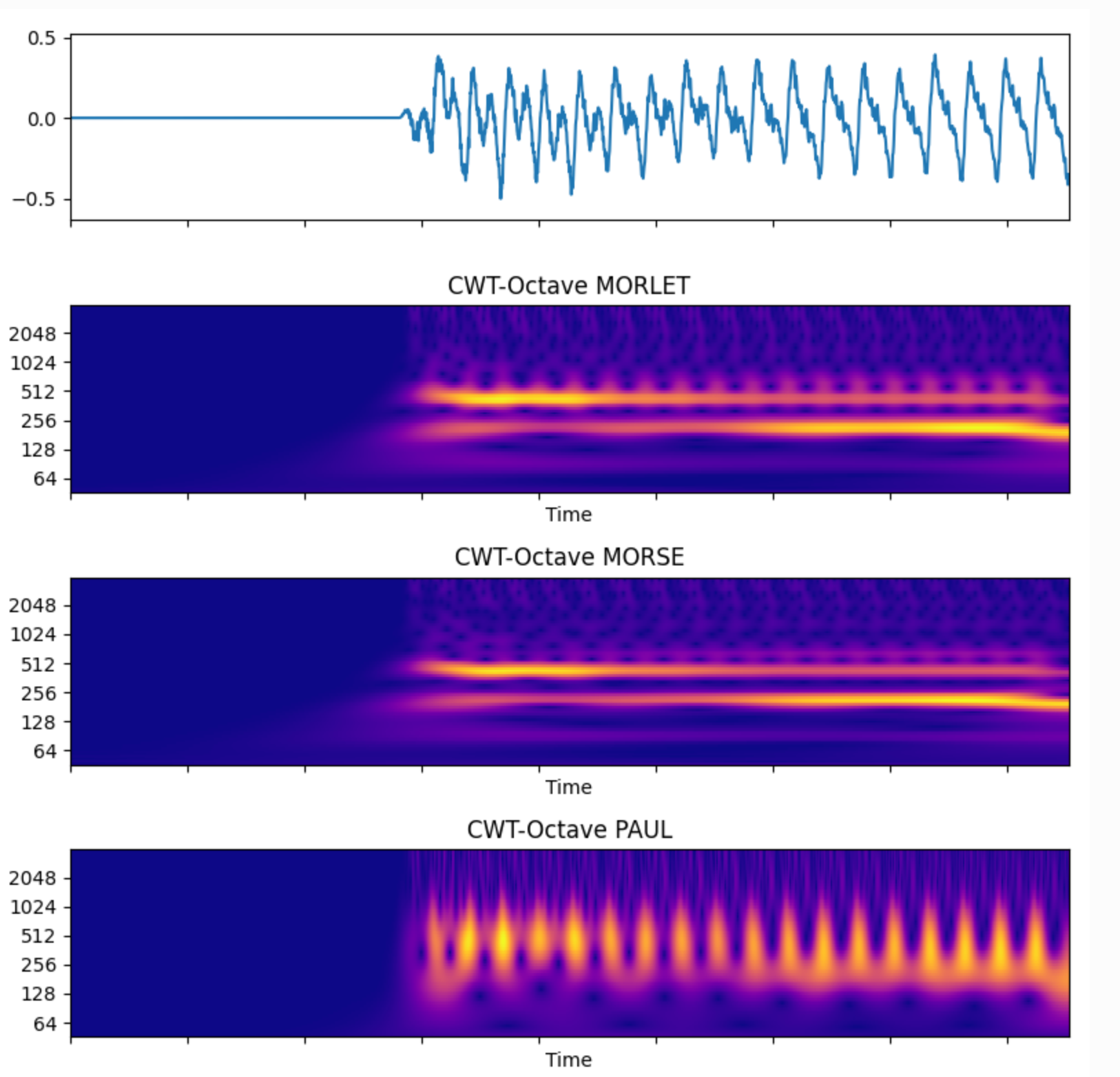
CWT – Continuous wavelet transform.
For multi-resolution time-frequency analysis, from a mathematical point of view, the basis of Fourier transform is an infinite sin/cos function, while the basis of wavelet transform is a finite and small wave function. The general representation of wave function is\(\psi_ {a,b}
PWT – Pseudo wavelet transform.
Based on the wavelet transform effect achieved by Fourier transform, the efficient algorithm of CWT calculates the filterBank and frequency domain data for the frequency domain wavelet function to do dot operation. If the wavelet function is regarded as a special window function, it can produce a CWT-like effect, that is Pseudo-wavelet transform, if the window function establishes adjustable frequency band parameters (not yet implemented in the library), it can be equivalent to wavelet transform.
The above transformation functions support all of the following frequency scale types:
- linear – Standard linear frequency band spectrogram, half of the short-time Fourier transform result is a linear scale spectrogram, and the scale is sampling rate/sampling sample, which is the minimum frequency domain resolution.
- linsapce – The spectrogram of the custom frequency band range, the frequency band can be larger than the linear frequency band, which is equivalent to downsampling in the time domain.
- mel – Mel-scale spectrogram, one of the most commonly used spectrogram types in audio, based on the low-frequency sensitivity and high-frequency insensitivity of the human ear, and a log-like compressed linear scale.
- bark – Barker scale spectrogram, which is more in line with human hearing than Mel scale.
- erb – The equivalent rectangular bandwidth spectrogram is more in line with human hearing than the Barker scale.
- octave – Octave scale spectrogram, spectrogram conforming to the logarithmic scale of musical notes.
- log – Spectrogram in logarithmic scale.
The following is a simple comparison chart of different frequency scales under BFT transformation.
Below is a simple comparison graph of different wave functions of CWT.
The following algorithms are available as independent transforms (multiple frequency scale types are not supported):
- CQT -Constant Q transformation, a transformation in which the frequency band ratio is constant, this transformation is commonly used in music, and the chroma feature is often calculated based on this for analyzing harmony.
- VQT – Variable Q transform.
- ST – S transform/Stockwell transform, similar to wavelet transform, is an extreme special case of wavelet transform, which can be used to detect and analyze some extreme mutation signals such as earthquakes, tsunamis, etc. Compared with NSGT, it also adds a Gaussian window, but establishes f Scaling relationship with t.
- FST – Fast S-transform, a discrete base-2 implementation of the S-transform.
- DWT – Discrete wavelet transform, relative to CWT, frequency-based 2 transform.
- WPT – Wavelet packet transform, also known as wavelet packet decomposition, can decompose the signal in detail and approximate. It is a way of signal separation and synthesis, and can be used for noise reduction, modal structure analysis and other services.
- SWT – Steady-state wavelet transform, similar to wavelet packet transform, the decomposed signal has the same length as the original signal.
The following is a simple comparison chart of different scales under CQT and NSGT transformation.
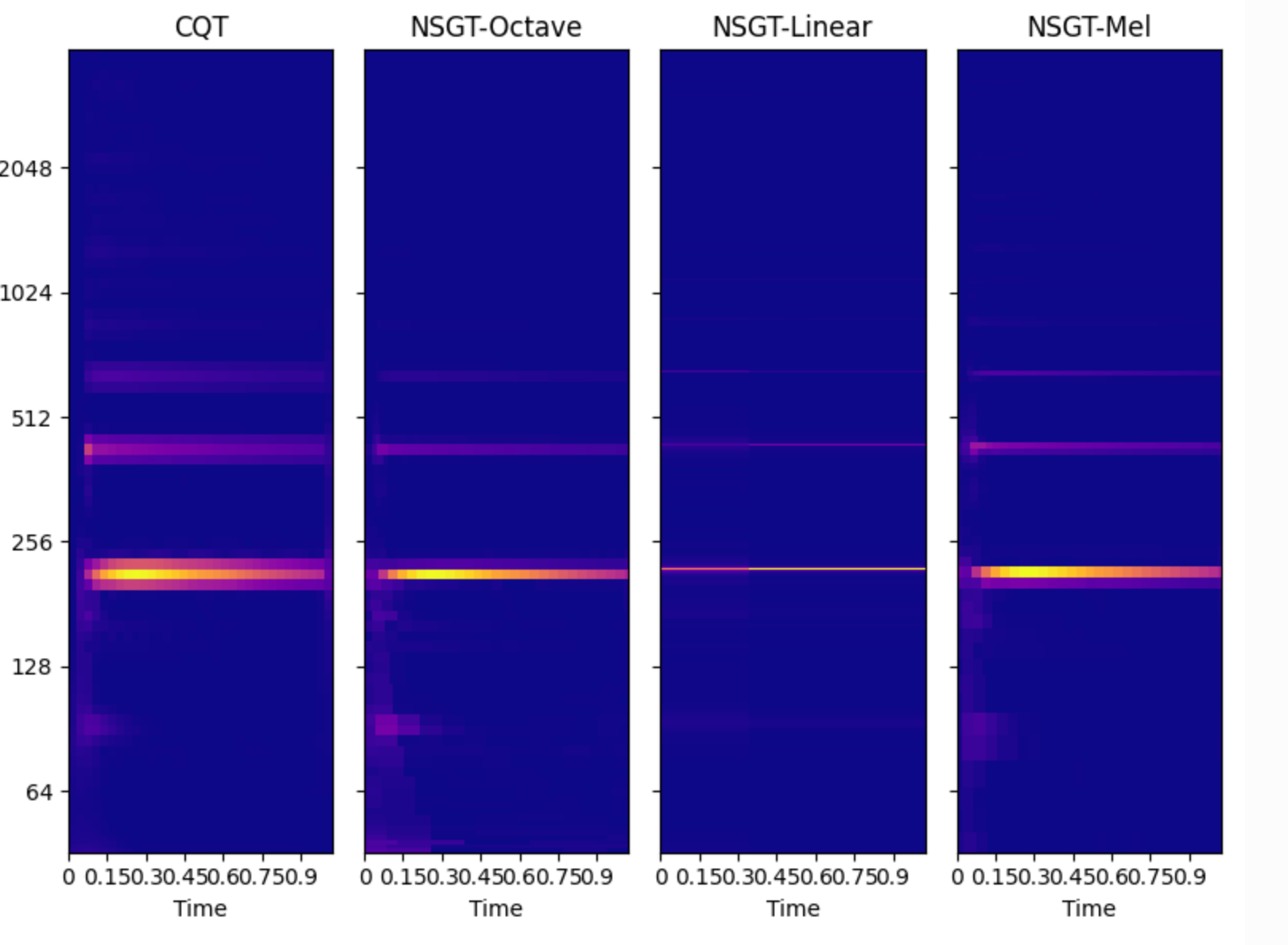
Obviously, NSGT-Octave is clearer and more focused than CQT.
Chroma is a more advanced feature based on spectrum, which belongs to the category of musical tone scale system. The scale for non-music tone is worse than that of musical tone. Currently, the spectrum type of chroma feature is supported:
- CQT
- BFT-linear
- BFT-octave
Below is a simple comparison chart of Chroma.
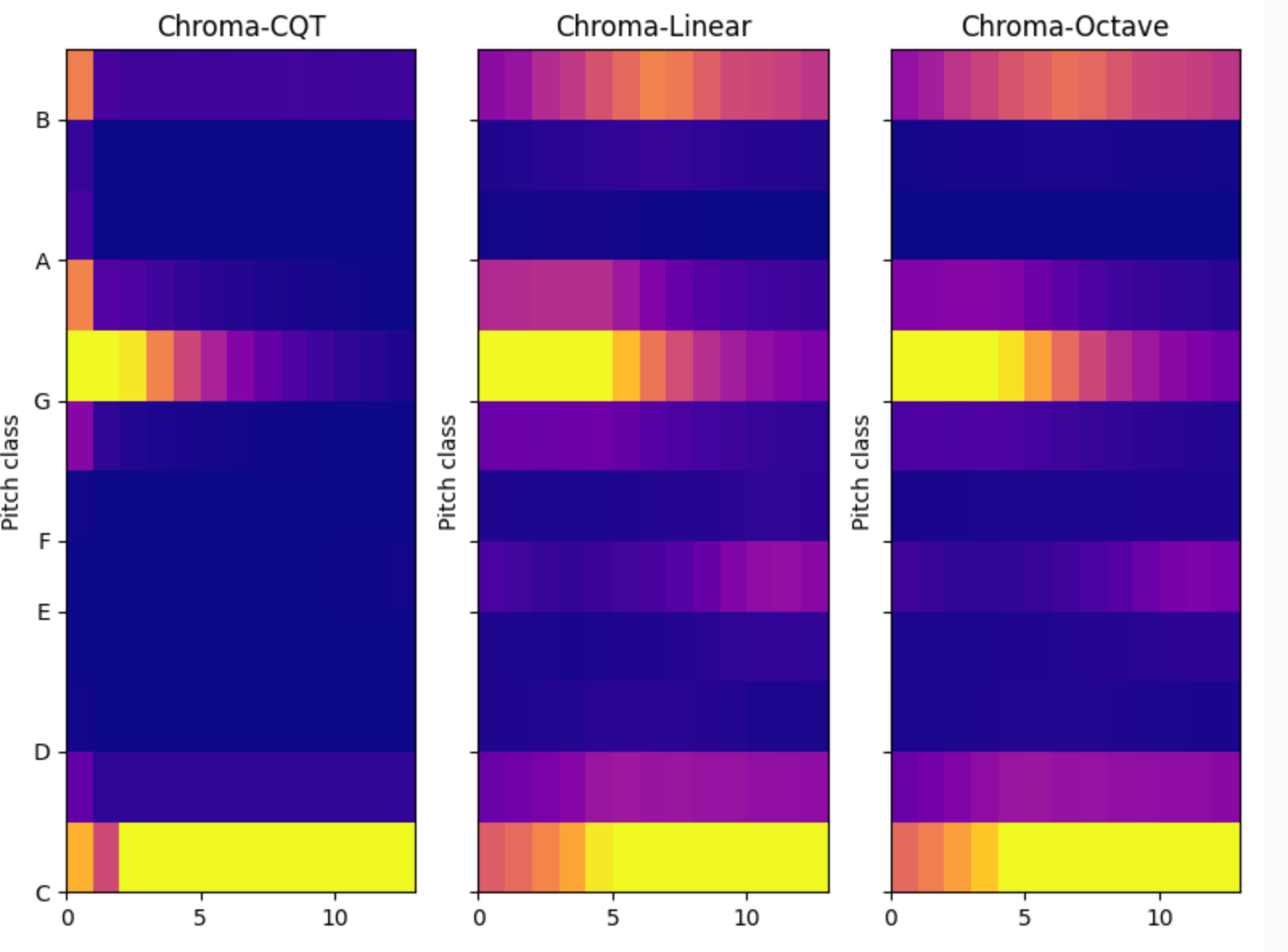
Obviously, CQT-Chroma outperforms chroma under other spectrum types.
Note:
- The spectrum of different frequency scales has its own application value. For some business situations, these spectrum diagrams of different scales can be combined into a large feature set to participate in network training.
- The spectrogram is called the amplitude spectrum, power spectrum, logarithmic spectrum/dB spectrum according to the non-linear operations such as abs, square, and log, and the logarithmic spectrum is generally used in deep learning.
The synchronous compression or reallocation method is a technique for sharpening, high-definition spectrograms, which can improve the clarity and precision of the spectrum. audioFlux includes the following algorithms:
- reassign – For STFT transformation rearrangement, spectrum data such as mel/bark/erb based on BFT can also be rearranged.
- synq – CWT spectrum data rearrangement.
- wsst – CWT transform rearrangement.
The following is a spectrogram and the corresponding rearranged rendering.
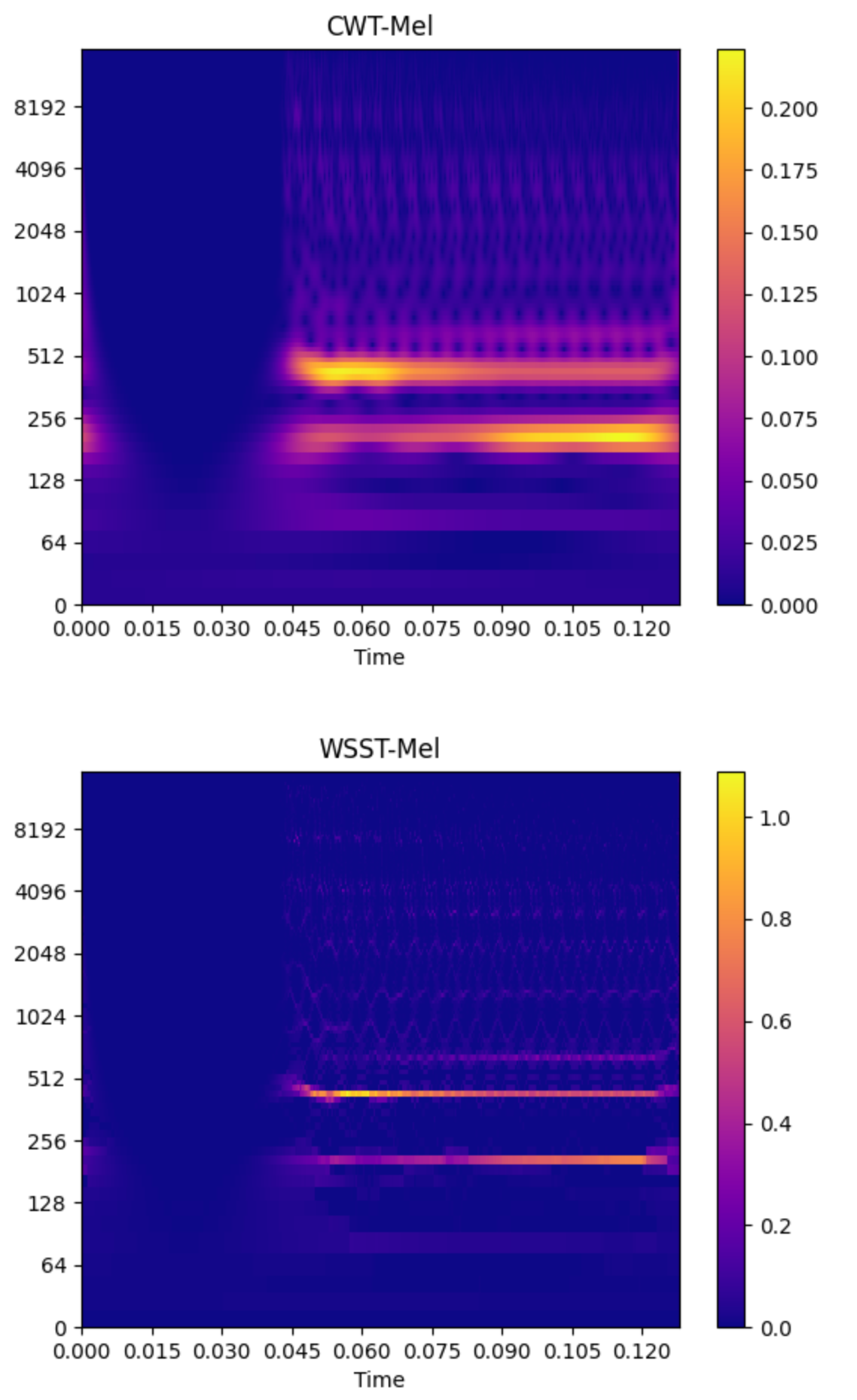
Obviously, the effect after rearrangement is better than the effect before rearrangement.
Some people may ask, since the rearrangement effect is so good, can it be rearranged multiple times based on the last result? How does this work? The audioFlux rearrangement-related algorithm provides multiple rearrangement mechanisms. For specific effects, please refer to the document for a trial comparison.
Similar to the mfcc (Mel frequency cepstrum coefficient) for the mel spectrum, this feature belongs to pitch removal in terms of business, and is a feature that reflects the physical structure of pronunciation. It is typically used for speech recognition related services and can be used for different musical instruments. The structure is fine business model training.
In the entire audioFlux project spectrum system, except for mfcc and the corresponding delta/deltaDelta, all types of spectral cepstral coefficients are supported, namely xxcc:
- lfcc
- gtcc
- bfcc
- cqcc
- …
The cepstral coefficients of different spectrums represent the de-pitch correlation of different spectrum types, and each has its own application value. For example, gtcc has a paper reflecting that the phoneme effect in speech recognition business is better than mfcc. cqcc is aimed at the classification of musical instruments and Some structural refinement services are far better than mfcc and so on.
Below is a comparison of different spectral cepstral coefficients for guitar tone audio.
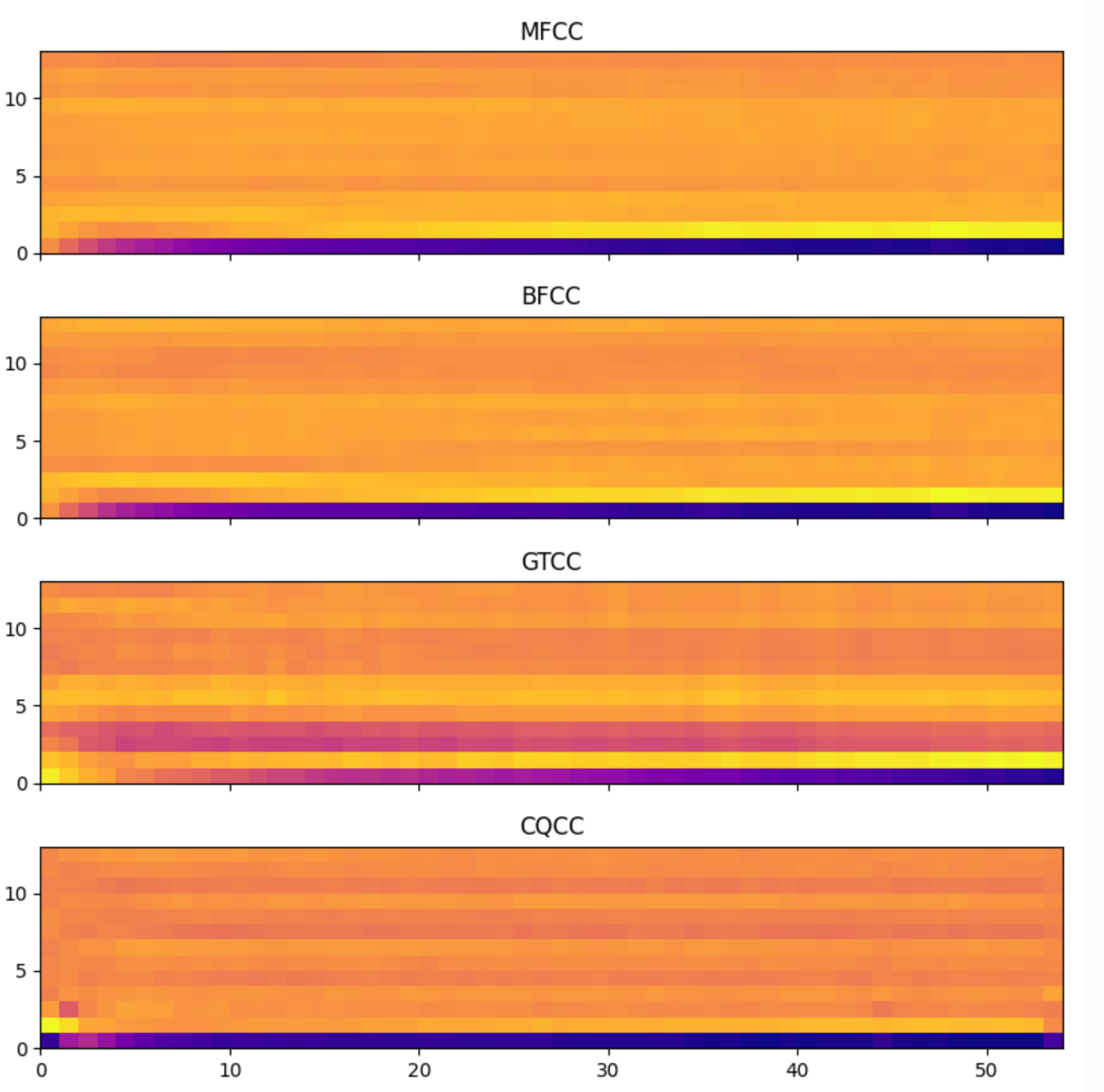
Obviously, cqcc performs the best in the stage of guitar tone vibration, and gtcc is better in the subsequent stable stage.
In mathematics, deconvolution is the inverse operation of convolution, which can be used as an algorithm for signal decomposition. For spectrum, the decomposed two data can be expressed as formant (formant) spectrogram and pitch spectrogram. Compared with mfcc, formant is a more general feature of the physical structure of pronunciation.
In audioFlux, the deconvolution operation of all types of spectrum is supported, and its value is that for pitch-related services, the model inference can be more accurate after removing formant interference; for services with structure-related features, pitch can be removed to avoid The training of the model is disturbed by it.
Below is a deconvolution rendering of the mel spectrogram for guitar 880hz audio.
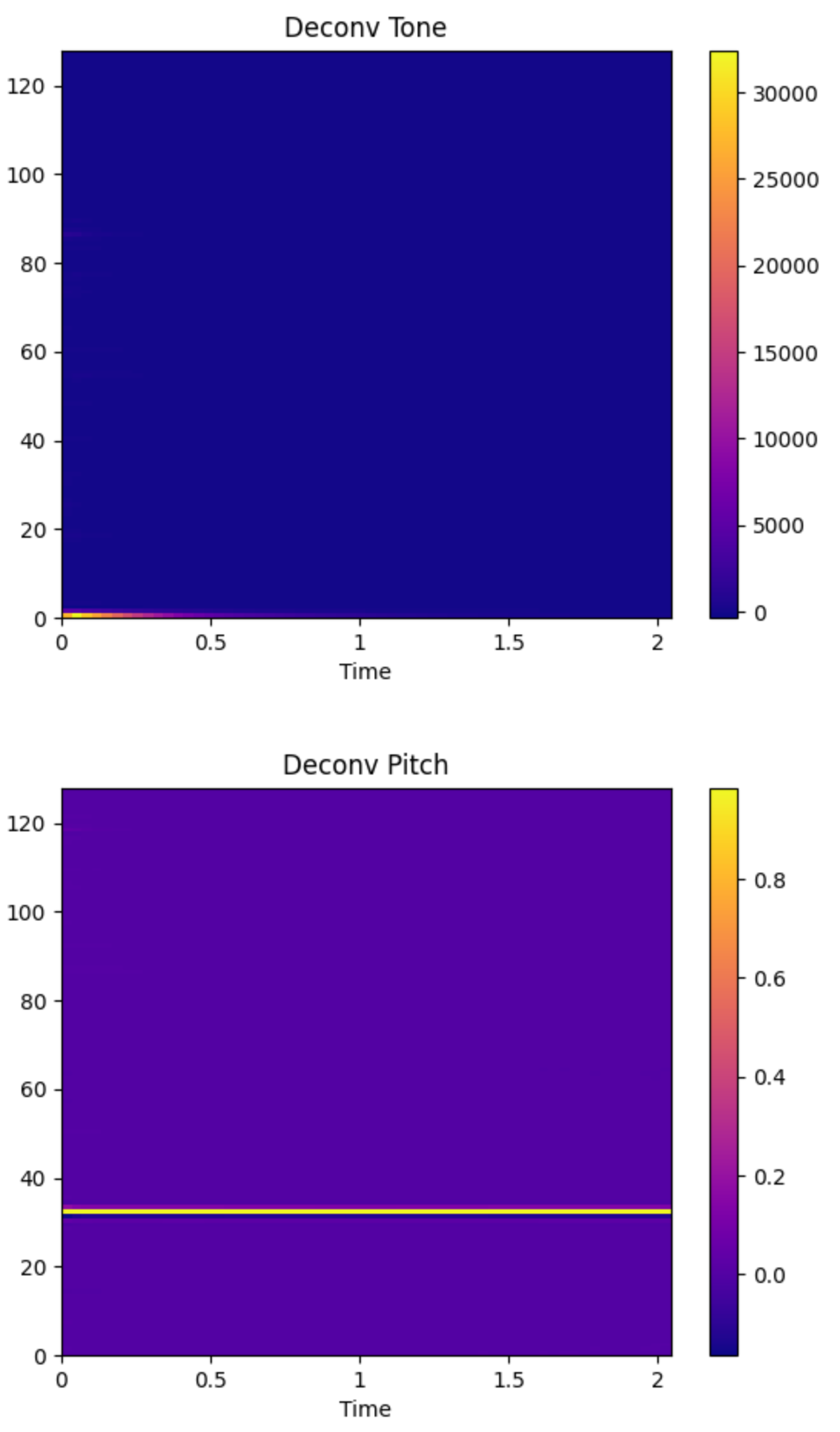
You can see the effect of a clear separation between the formant part (timbre) and the pitch part of the guitar.
In audioFlux, dozens of spectral-related features are included, including timbre-based features, statistical-based features, spectral flux-based features, singular value-based features, and so on.
like:
- flatness
- skewness
- crest
- slop
- roll off
- …
- Centroid
- spread
- kurtosis
- …
- flux
- hfc
- mkl
- …
- …
Wait for a small part. For all the spectral features provided by audioFlux, please refer to the official documentation for more specific function descriptions, examples, formulas, etc.
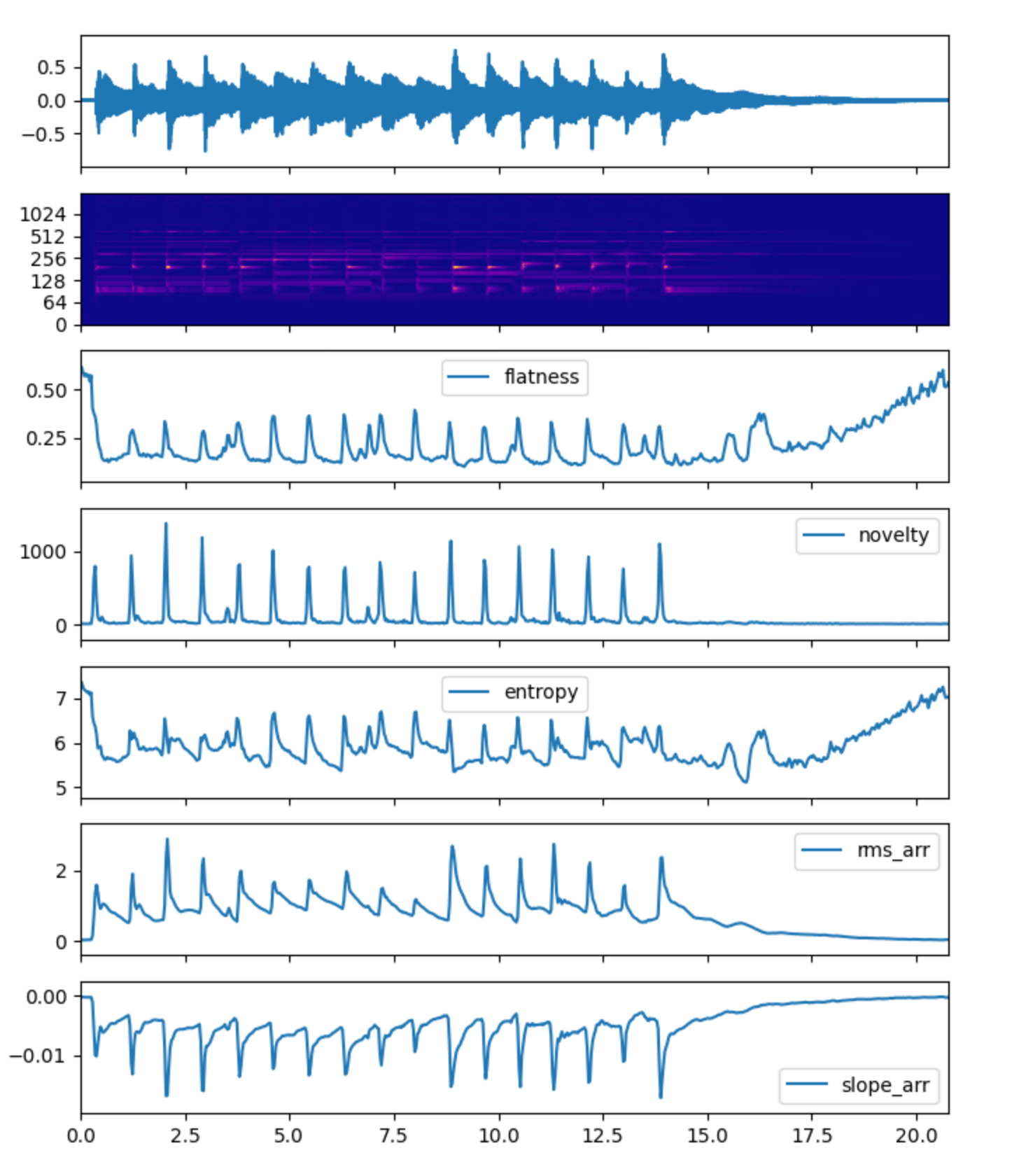
Below are some spectral feature comparison charts.
audioFlux provides pitch estimation, onset detection, hpss (harmonic percussion separation) and other related business algorithms in mir-related fields.
Pitch estimation includes related algorithms based on YIN, STFT, etc. The following is a detection effect diagram for a vocal practice pitch.
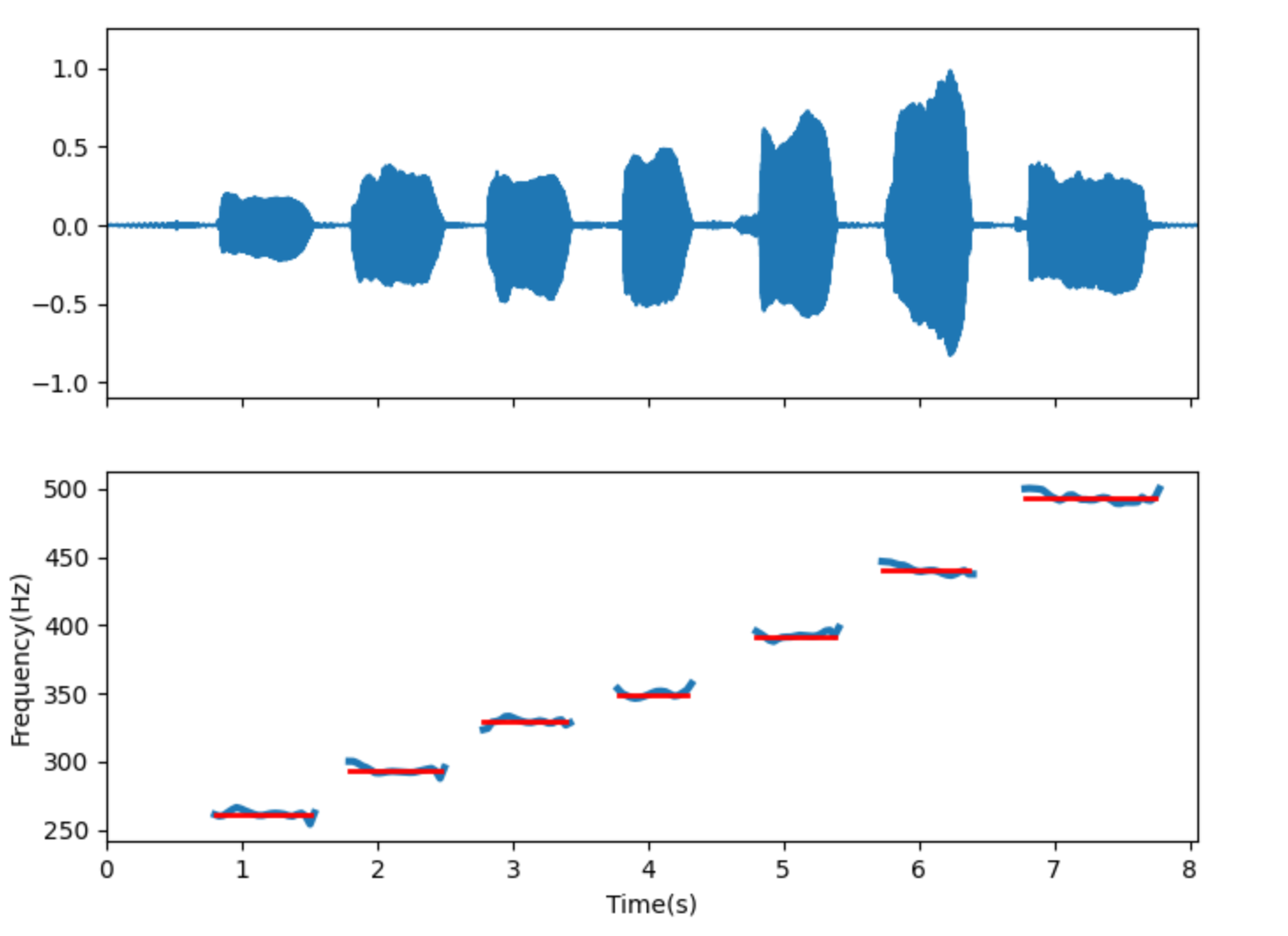
Red is the actual reference pitch, and blue is the estimated pitch.
Onset detection includes related algorithms based on Spectrum flux, novelty, etc. The following is an endpoint detection rendering of a guitar strumming accompaniment.
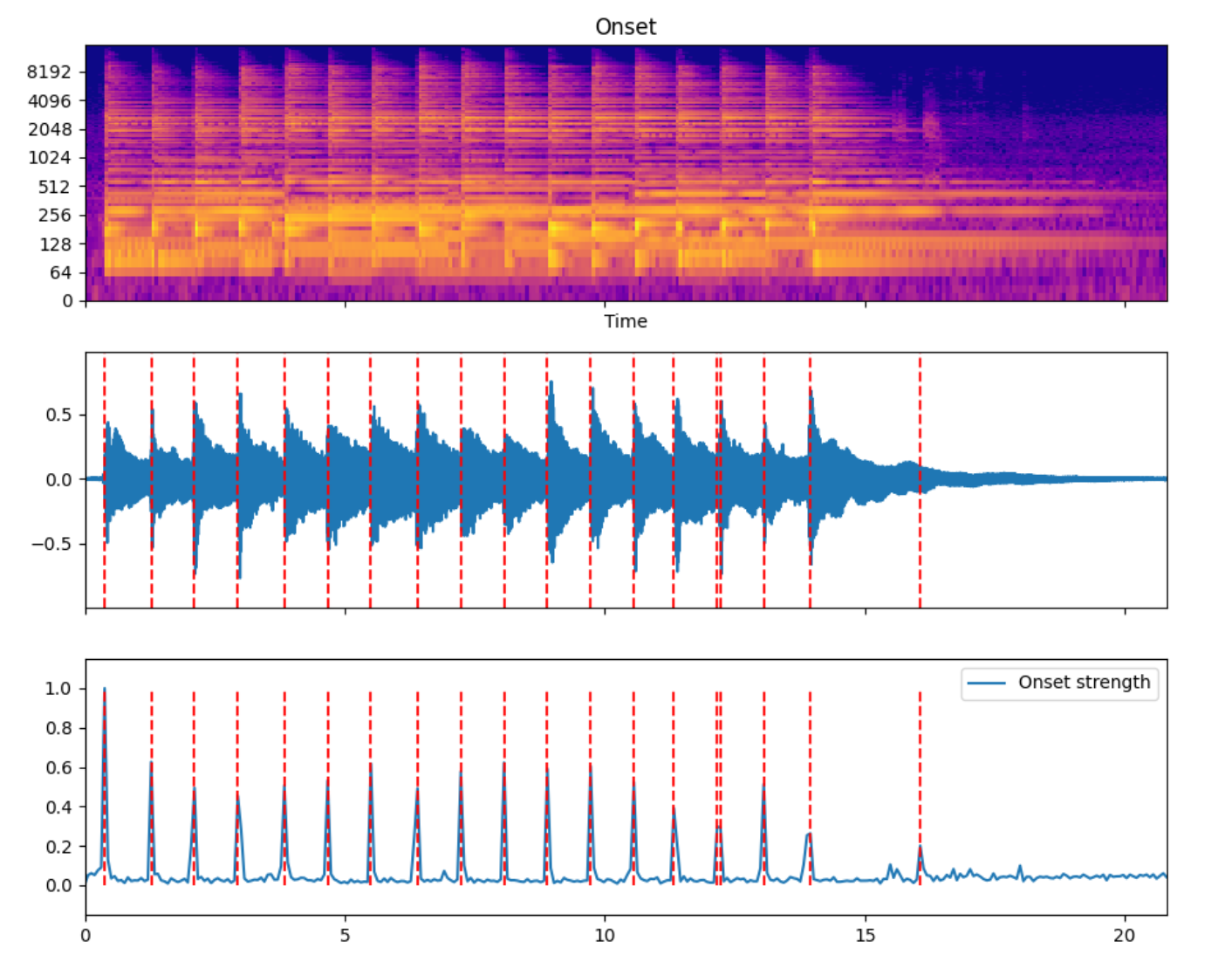
The red dotted line in the middle time domain image is superimposed by the endpoint detection position.
hpss includes median filtering, non-negative matrix factorization (NMF) and other algorithms. The following is a separation effect including guitar playing and metronome audio. The upper part is the time domain effect, and the lower part corresponds to the frequency domain effect.
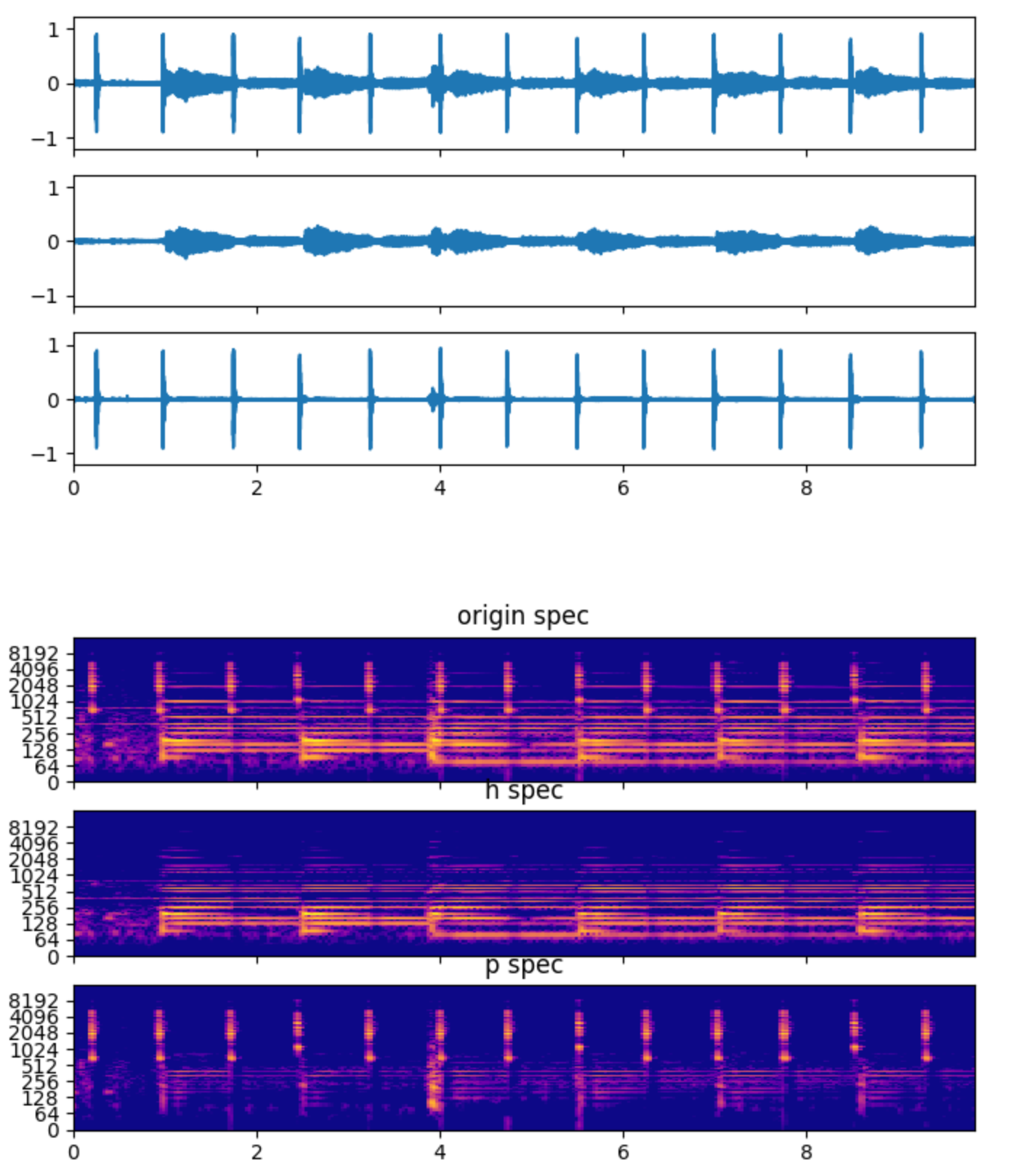
#Deep #learning #tool #audioFluxa #systematic #audio #feature #extraction #library #labRosas #personal #space #News Fast Delivery