Recently, ChatGPT was born and achieved great success, making obscure abbreviations such as RLHF, SFT, IFT, CoT, etc. begin to appear in the discussion of the general public. What do these obscure acronyms actually mean? Why are they so important? We survey all relevant important papers to classify these works, summarize the work to date, and look forward to the follow-up work.
Let’s first look at the panorama of language model-based conversational agents. ChatGPT is not the first. In fact, many organizations released their own language model dialog agents (dialog agents) before OpenAI, including Meta’s BlenderBot, Google’s LaMDA, DeepMind’s Sparrow, and Anthropic’s Assistant (Anthropic’s Claude is partly based on Assistant continue to develop).
Some of these teams have also announced their plans to build open source chatbots and publicly shared their roadmaps (such as the LAION team’s Open Assistant), and others are sure to have something similar, but have yet to announce it.
The table below compares these AI chatbots based on details of whether they are publicly accessible, training data, model architecture, and evaluation direction. ChatGPT has no record of this information, so we instead used details from InstructGPT, an instruction-fine-tuned model from OpenAI that is believed to be the basis for ChatGPT.
| LaMDA | BlenderBot 3 | Sparrow | ChatGPT / InstructGPT | Assistant | |
|---|---|---|---|---|---|
| organize | Meta | DeepMind | OpenAI | Anthropic | |
| Is it publicly accessible | no | can | no | limited | no |
| size | 137B | 175B | 70B | 175B | 52B |
| pre-training base model | unknown | OPT | Chinchilla | GPT-3.5 | unknown |
| Pre-training corpus size (number of words) | 2.81T | 180B | 1.4T | unknown | 400B |
| Whether the model can access the network | ✔ | ✔ | ✔ | ✖️ | ✖️ |
| supervised fine-tuning | ✔ | ✔ | ✔ | ✔ | ✔ |
| Fine-tuning data size | Quality: 6.4K Security: 8K Authenticity: 4K IR: 49K | 20 NLP datasets ranging in size from 18K to 1.2M | unknown | 12.7K (this is InstructGPT, ChatGPT may be more) | 150K+ LM generated data |
| wxya | ✖️ | ✖️ | ✔ | ✔ | ✔ |
| artificial safety rules | ✔ | ✖️ | ✔ | ✖️ | ✔ |
| evaluation standard | 1. Quality (Plausibility, Specificity, Interest) 2. Safety (Prejudice) 3. Authenticity | 1. Quality (engagement, knowledge utilization) 2. Safety (toxicity, bias) | 1. Straightening (helpful, harmless, correct) 2. Evidence (from the Internet) 3. Whether it violates the rules 4. Prejudice and stereotypes 5. Integrity | 1. Straightening (helpful, harmless, truthful) 2. Prejudice | 1. Straightening (helpful, harmless, honest) 2. Prejudice |
| Crowdsourcing platform for data annotation | US supplier | Amazon MTurk | unknown | Upwork and Scale AI | Surge AI, Amazon MTurk, and Upwork |
We observe that despite many differences in training data, models, and fine-tuning, there are some commonalities. A common goal of all chatbots mentioned above is “instruction following”, that is, following instructions specified by the user. For example, ask ChatGPT to write a poem about fine-tuning.

From predicting text to following instructions
Often, the language modeling goals of the underlying model are not sufficient for the model to learn to follow the user’s instructions in a useful way. Model creators use the “Instruction Fine-Tuning (IFT)” method to achieve this goal. In addition to using classic NLP tasks such as sentiment analysis, text classification, summarization, etc. to fine-tune the model, the method is also very diverse. Demonstrate various written instructions and their output to the basic model, so as to realize the fine-tuning of the basic model. These command demonstrations consist of three main parts – command, input and output. Input is optional, and some tasks only require instructions, such as the example above using ChatGPT for open text generation. When an input is present, the input and output form an “instance”. A given directive can have multiple input and output instances. The following example (taken from Wang et al., ’22):

The training data for IFT is usually a collection of human-written instructions and instances generated with a language model bootstrap. When bootstrapping, the LM is first fed with some samples using the few-shot technique to hint it (as shown in the figure above), and then the LM is asked to generate new instructions, inputs, and outputs. Each round selects some of the human-written samples and some of the model-generated samples for the model. The contributions of humans and models to creating the dataset form a spectrum, see the figure below:
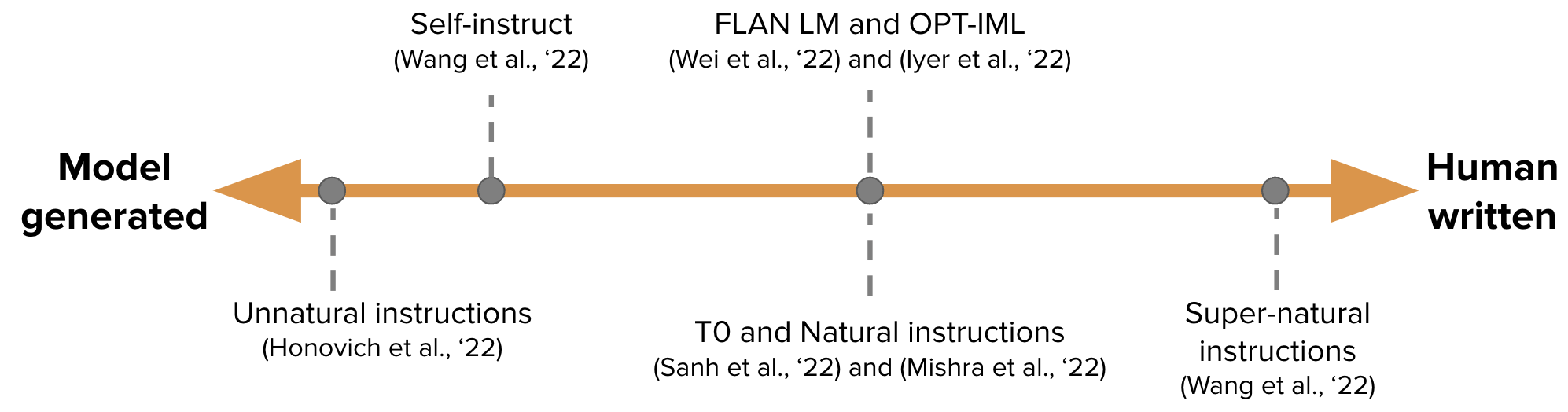
At one end of the spectrum are purely model-generated IFT datasets such as Unnatural Instructions (Honovich et al., ’22); at the other end are instructions crafted through extensive community effort such as Super-natural instructions (Wang et al., ’22). Work in between uses a small set of high-quality seed datasets, followed by bootstrapping to generate a final dataset, such as Self-Instruct (Wang et al., ’22). Another approach to curate datasets for IFT is to convert existing high-quality crowdsourced NLP datasets for various tasks (including prompts) into instructions using a unified schema or different templates. This line of work includes T0 (Sanh et al., ’22), the Natural instructions dataset (Mishra et al., ’22), FLAN LM (Wei et al., ’22) and OPT-IML (Iyer et al., ’22).
follow instructions safely
However, instruction-tuned LMs do not always generate helpful and safe response. Examples of this behavior include evasion by always giving unhelpful responses, such as “Sorry, I don’t understand.” or generating unsafe responses to user input on sensitive topics.To mitigate this behavior, model developers use Supervised Fine-tuning (SFT), to fine-tune underlying language models on high-quality human-annotated data to improve usefulness and harmlessness. For example, see the table below (taken from Appendix F of the Sparrow paper).
SFT and IFT are very closely linked. Instruction fine-tuning can be seen as a subset of supervised fine-tuning. In the recent literature, the SFT stage is often used to improve the security of the response, rather than following the IFT to improve the specificity of the command response. In the future, this classification and division should mature day by day to form a clearer usage scenario and methodology.

Google’s LaMDA is also fine-tuned on dialog datasets with secure annotations according to a set of rules (Appendix A of the paper). These rules are usually pre-defined and developed by the model creators and cover a wide range of topics including harm, discrimination, misinformation.
Fine-tuning the model
Meanwhile, OpenAI’s InstructGPT, DeepMind’s Sparrow, and Anthropic’s Constitutional AI use Human Feedback Reinforcement Learning (Reinforcement Learning From Human Feedback, RLHF) to fine-tune the model using labeled data based on human preferences. In RLHF, the model’s responses are ranked and annotated based on human feedback (eg, selecting text profiles based on human preferences). These labeled responses are then used to train a preference model, which is used to return a scalar reward to the RL optimizer. Finally, a dialogue agent is trained via reinforcement learning to mimic the preference model. For more details, please refer to our previous article on RLHF: The “hero” behind ChatGPT – RLHF technical details.
Chain-of-thought (CoT) Prompts (Wei et al., ’22) are a special case of instruction demonstrations that generate outputs by eliciting step-by-step reasoning by a dialog agent. Models fine-tuned using CoT use human-annotated instruction datasets with step-by-step inference.this is Let’s think step by step The origin of this famous tip. The example below is taken from Chung et al., ’22, instructions are highlighted in orange, inputs and outputs in pink, and CoT inferences in blue.

As described in Chung et al., ’22, models fine-tuned using CoT perform better on tasks involving common sense, arithmetic, and symbolic reasoning.
As shown in the work of Bai et al., ’22, CoT fine-tuning has also been shown to be very effective for innocuousness (sometimes better than RLHF), and for sensitive cues, the model does not avoid and generate “Sorry, I can’t answer this question” answer. See Appendix D of his paper for more examples.

main point
- Compared with the pre-training data, you only need a very small part of the data for instruction fine-tuning (hundreds of orders of magnitude);
- Supervised fine-tuning using human annotations to make model outputs safer and more useful;
- CoT fine-tuning improves the performance of models on tasks that require incremental thinking and makes them less avoidant on sensitive topics.
Further Work on Dialogue Agents
This blog summarizes a lot of existing work on making dialog agents useful. But there are still many open questions to be explored. We list some of them here.
- How important is RL in learning from human feedback? Can we gain RLHF performance by training with higher quality data in IFT or SFT?
- How does SFT+RLHF in Sparrow compare to using only SFT in LaMDA from a safety point of view?
- Given that we have IFT, SFT, CoT and RLHF, how much is pre-training necessary? How to compromise? What is the best base model (public and non-public) that one should use?
- Many of the models referenced in this article have been carefully designed through red-teaming, where engineers specifically search for failure modes and improve subsequent training (hints and methods) based on the problems that have been revealed. How do we systematically document the effects of these methods and reproduce them?
Ps If you find any information missing or incorrect in this blog, please let us know.
quote
Rajani et al.,"What Makes a Dialog Agent Useful?", Hugging Face Blog, 2023.
BibTeX citations:
@article {rajani2023ift,
author = {Rajani, Nazneen and Lambert, Nathan and Sanh, Victor and Wolf, Thomas},
title = {What Makes a Dialog Agent Useful?},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/dialog-agents},
}
Original English: https://huggingface.co/blog/dialog-agents
Translator: Matrix Yao (Yao Weifeng), an Intel deep learning engineer, works on the application of transformer-family models on various modal data and the training and reasoning of large-scale models.
#Interpretation #technical #points #ChatGPT #RLHF #IFT #CoT #red #blue #confrontation #Hugging #Face #News Fast Delivery