Author: JD Health Meng Fei
1. The significance of database performance optimization
In the early stage of business development, the amount of database is generally not high, and some performance problems are not easy to occur or the problems are not large. However, when the magnitude of the database reaches a certain scale, if there is no effective early warning, monitoring, processing and other means It will affect the user’s experience, and in serious cases, it will directly lead to direct damage to the order and amount. Therefore, it is necessary to pay attention to the performance of the database at all times.
2. Several common measures for performance optimization
There are many common methods for database performance optimization, such as adding indexes, sub-database sub-tables, optimizing connection pools, etc., as follows:
| serial number | Types of | measure | illustrate | | 1 | Physical level| Improve hardware performance| Installing the database on a server with a higher configuration will have an immediate effect, such as increasing the CPU configuration, increasing memory capacity, and using solid-state drives. You can try it within the scope of funds. | | 2 | Application Level | Connection Pool Parameter Optimization | Most of our applications use connection pools to manage database connections, but most of them are default configurations, so configuring parameters such as timeout duration and connection pool capacity is very important. Particularly important. 1. If the link is occupied for a long time, new requests cannot obtain new connections, which will affect the business. 2. If the number of connections is set too small, even if the hardware resources are fine, it will not be able to play its role. The company has done some pressure tests before, but the life and death are not up to standard, and finally found that the number of connections is too small. | | 3 | Single table level | Reasonable use of indexes | If the amount of data is large, but there is no suitable index, it will drag down the entire performance, but the index is a double-edged sword, not to say that the more indexes the better, but It is necessary to add and use appropriately according to the needs of the business. Missing indexes, duplicate indexes, redundant indexes, and out-of-control indexes are actually very harmful to the system. | | 4 | Database table level | Sub-database and sub-table | When the amount of data is large, it is not meaningful to only use the index. Dimensions such as ID, order ID, and date are partitioned to reduce the scanning range. | | 5 | Monitoring level| Strengthening operation and maintenance| For some online systems, further monitoring is required, such as subscribing to some slow SQL logs, finding some bad SQL, or using some common tools in the business, such as druid components etc. |
3. MySQL underlying architecture
First of all, understand the underlying structure of the data, which will also help us to do better optimization.
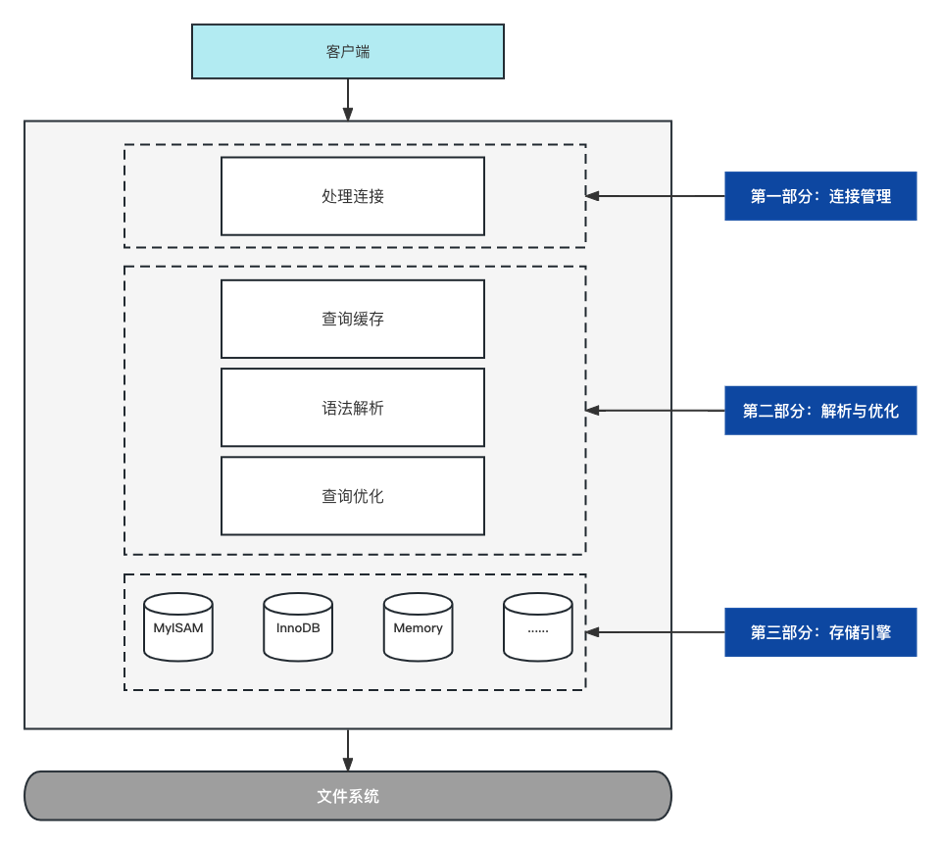
The execution process of a query request
We focus on the second and third parts. The second part is actually the Server layer. This layer is mainly responsible for query optimization, formulating some execution plans, and then calling the various underlying basic APIs provided by the storage engine, and finally storing the data. returned to the client.
4. MySQL index construction process
At present, the InnoDB storage engine is more commonly used, and the discussion in this article is also based on the InnoDB engine. We have been talking about indexing, so what is an index, how is an index formed, and how is an index applied? This topic is actually very big and small. I say it is big because the bottom layer is really complicated, and I say it is small because programmers only need to add indexes in most scenarios. It is not necessary to understand the underlying principles, but if the understanding is not thorough It will cause online problems, so this article balances everyone’s understanding cost and knowledge depth, and introduces certain underlying principles, but it will not be too in-depth to make it difficult to understand.
Let’s do an experiment first:
Create a table that currently has only one primary key index
CREATE TABLE `t1`(
a int NOT NULL,
b int DEFAULT NULL,
c int DEFAULT NULL,
d int DEFAULT NULL,
e varchar(20) DEFAULT NULL,
PRIMARYKEY(a)
)ENGINE=InnoDB
Insert some data:
insert into test.t1 values(4,3,1,1,’d’);
insert into test.t1 values(1,1,1,1,’a’);
insert into test.t1 values(8,8,8,8,’h’);
insert into test.t1 values(2,2,2,2,’b’);
insert into test.t1 values(5,2,3,5,’e’);
insert into test.t1 values(3,3,2,2,’c’);
insert into test.t1 values(7,4,5,5,’g’);
insert into test.t1 values(6,6,4,4,’f’);
MYSQL reads data from disk to memory according to one page, and the default value of one page is 16K, and the format of one page is roughly as follows.
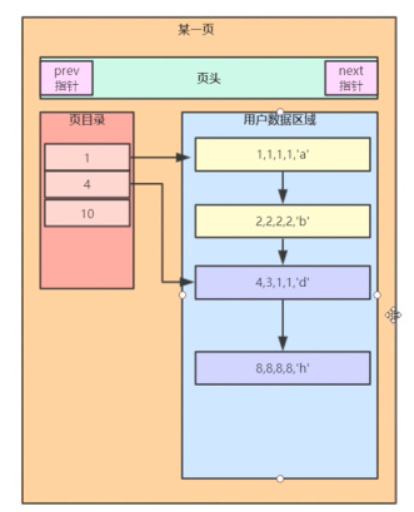
Each page includes several contents, the first is the page header, the second is the page directory, and the user data area.
1) The several pieces of data inserted just now are placed in this user data area, which is a one-way linked list that increases sequentially according to the primary key.
2) The page directory is used to point to the specific user data area, because when the data in the user data area increases, groups will be formed, and the page directory will point to different groups, and binary search can be used to quickly locate data .
When the amount of data increases, this page cannot hold so much data, and the page must be split, and each page will be bidirectionally linked, eventually forming a doubly linked list.
The one-way linked list in the page is for quick search, and the two-way linked list between pages is for improving efficiency when doing range queries. reality.

And if the data continues to accumulate, these few pages alone are not enough, then a tree is gradually formed, that is to say, the index B-Tree is gradually built with the accumulation of data.
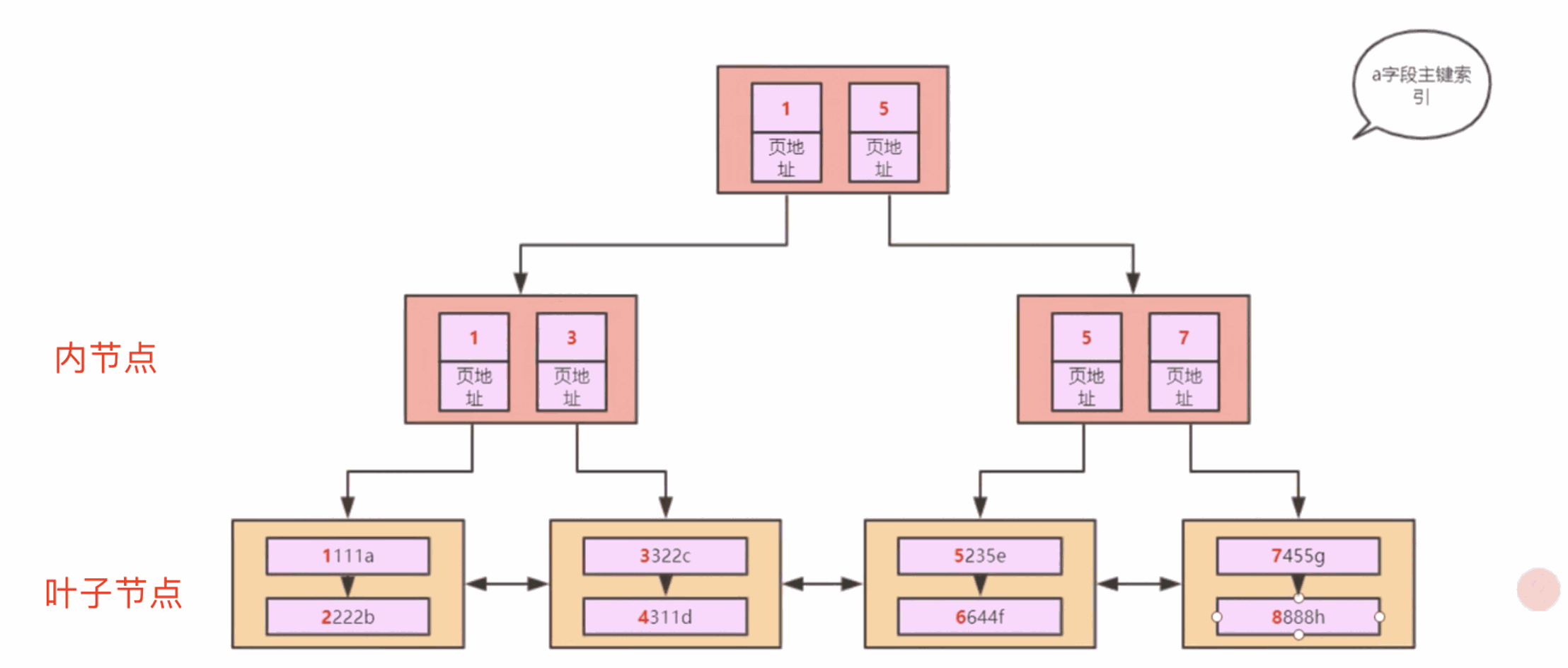
The bottom layer is called a leaf node, and the top layer is called an internal node, and the leaf nodes store the full amount of data. Such a tree isclustered index.Some students have always understood that the index is a separate copy and the data is a copy. In fact, there is a principle in MySQL thatData as Index, Index as Datathe real data itself is stored in the clustered index, the so-calledThe return table is the clustered index of the return.
But we don’t necessarily execute SQL statements according to the primary key every time. In most cases, we execute SQL statements according to some business fields, which will form other index trees. For example, if the indexes created according to b, c, and d are It will grow like this.

Recommend a website, you can visually view some algorithm prototypes:
Table of contents:
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
B+ tree
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
The leaf node of the index introduced on the MySQL official website is a doubly linked list.

Summary about index structure:
For B-Tree, the leaf nodes are not linked, and the B+Tree index is a one-way linked list, but MySQL improves on the basis of B+Tree to form a doubly linked list. The benefit of bidirectional is in processing> < , between and etc. 'range query' syntax can be handy.
5. Some usage specifications of MySQL index
1. Only create indexes for columns used for searching, sorting or grouping.
Focus on the situation behind the where statement
2. When the number of unique values in the column accounts for a large proportion of the total number of records, the column is indexed.
For example, mobile phone number, user ID, class, etc., but for example, in a student table of the whole school, each record is a student, and the where statement is to query all the students of “a certain school”, then the performance will not be improved.
3. The type of index column should be as small as possible.
Whether it is the primary key or the index column, try to choose a small one. If it is large, it will occupy a large index space.
4. You can create an index only for the prefix of the index column to reduce the storage space occupied by the index.
alter table single_table add index idx_key1(key1(10))
5. Try to use the covering index for query to avoid the performance loss caused by the back-to-table operation.
select key1 from single_table order by key1
6. In order to minimize page splits in the clustered index, it is recommended to auto-increment the primary key.
7. Locate and delete redundant and duplicate indexes in the table.
Redundant index:
Single column index: (field 1)
Joint index: (field 1 field 2)
Duplicate index:
Multiple indexes such as common index, unique index, and primary key are added to a field
6. Implementation plan

The commonly used ones are:
possible_keys: possible indexes
key: the index actually used
rows: the estimated number of records that need to be read
7. Online case
Case 1:
In the construction of the Internet hospital system, the scale of the consultation form was about 230,000 at that time, and there was a business_id string field, which was used to record the ID of the external order, and an index was added to this field, but ‘according to the The SQL statement of ID query details’ is always up and down, and the performance is unstable. The fast is 10ms, and the slow is about 2 seconds. The SQL is roughly as follows:
select field 1, field 2, field 3 from nethp_diag where business_Id = ?
Because business_id is the order ID that records the third-party system, in order to be compatible with different third-party systems, it is designed asstring typebut if a numeric type is passed in, the index cannot be used, because MySQL can onlyString to number, but not number to stringbecause some of the external IDs are numbers and some are strings, the index can be reached for a while, but not for a while, which eventually leads to unstable performance.
Case 2:
On the day of a certain big promotion, I suddenly received an alarm from the DBA operation and maintenance, saying that the database traffic suddenly surged, and the CPU hit 100%, which affected some online functions and experiences. Most people encountered this situation at the time. It was quite tense. The following figure shows the database traffic situation at that time:

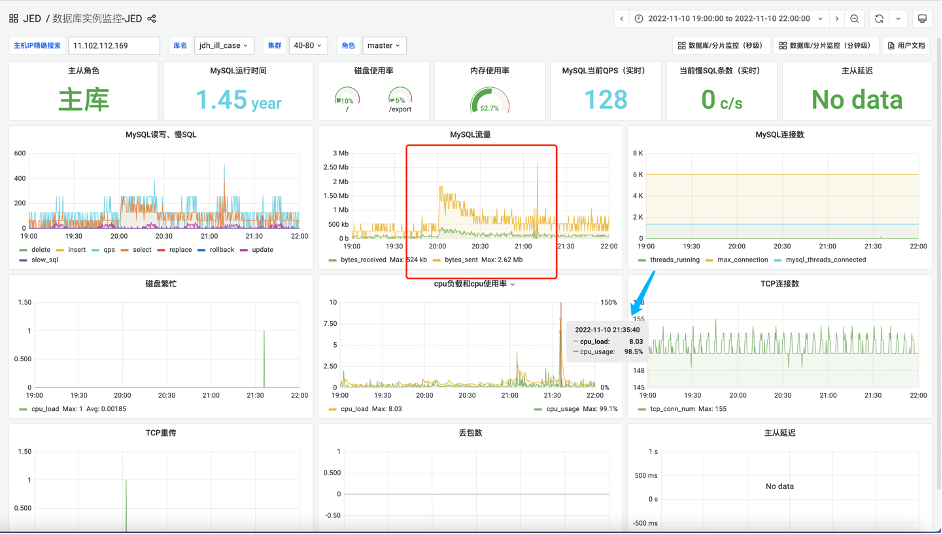
Relevant SQL statements:
select count(1)
from jdhe_medical_record
where status = 1 and is_test = #{isTest,jdbcType=INTEGER} and electric_medical_record_status in (2,3)
and patient_id = #{patientId,jdbcType=BIGINT}
and doctor_pin = #{doctorPin,jdbcType=VARCHAR}
and created >#{dateStart,jdbcType=TIMESTAMP};
The index situation at that time

Execution plan at that time

In fact, there are indexes on the two fields of patientId and doctor_pin, but due to changes in the online situation, the test judgment did not enter. Such a general query caused these two fields to not be set, which led to a surge in the amount of database scanning. puts a lot of pressure on the database.
Case 3:
On a certain morning in 2020, I received an abnormal alarm from the database CPU, which had a certain impact on the line. The follow-up inspection of the database CPU situation was as follows. Starting from 7:51, the CPU went from 8% to 99.92% in an instant, leaving nothing to the programmer. feelings.

The SQL statement at that time:
select rx_id, rx_create_time from nethp_rx_info where rx_status = 5 and status = 1 and rx_product_type = 0 and (parent_rx_id = 0 or parent_rx_id is null) and business_type != 7 and vendor_id = 8888 order by rx_create_time1; asc limit
The index situation at that time:
PRIMARY KEY (`id`), UNIQUE KEY `uniq_rx_id` (`rx_id`), KEY `idx_diag_id` (`diag_id`), KEY `idx_doctor_pin` (`doctor_pin`) USING BTREE, KEY `idx_rx_storeId` (`store_id`) , KEY `idx_parent_rx_id` (`parent_rx_id`) USING BTREE, KEY `idx_rx_status` (`rx_status`) USING BTREE, KEY `idx_doctor_status_type` (`doctor_pin`, `rx_status`, `rx_type`), KEY `idx_business_store` (` `, `store_id`), KEY `idx_doctor_pin_patientid` (`patient_id`, `doctor_pin`) USING BTREE, KEY `idx_rx_create_time` (`rx_create_time`)
At that time, the scale of this table was more than 20 million, and when the execution of this slow SQL was less, the CPU of the database also dropped, and it recovered to 49.91%, and the online business can basically be restored, so the appearance is intermittent online It can be prescribed for a while and not for a while. This SQL was executed 230 times in total at that time. SQL. When the online business logic is complicated, it is difficult for you to know which SQL is the cause at the first time. This requires you to be very familiar with the business and SQL, otherwise a lot of troubleshooting time will be wasted.
The final investigation results:
the night beforeAdded an index rx_create_timenothing happened at the time, but there was an accident the next day.
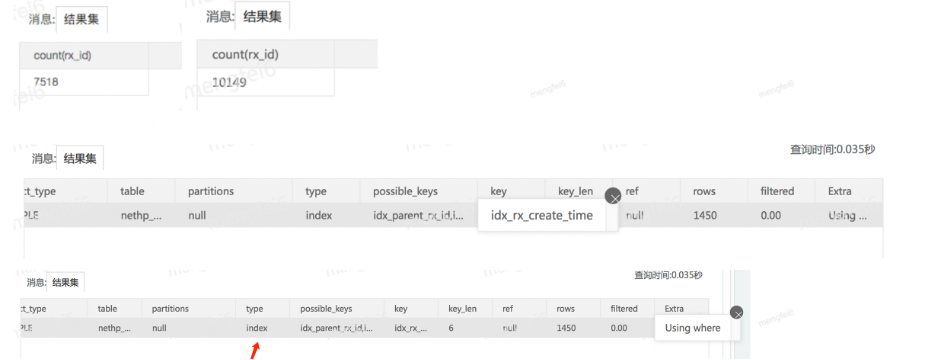
The indexes before and after adding the index are different. One is the rx_status (prescription review status) single-column index, and the other is the rx_create_time (prescription submission event) single-column index. This will return to the business, because the prescription status is an enumeration, and the enumeration The range is less than 10, that is to say, the online data volume of 29,000,000 is divided into less than 10 parts, and the value of rx_status=5 is one of them, so many rows can be hit through this index, which is a business rule , and then apply the characteristics of MySQL, mainly the following:
1. When no new index rx_create_time is addedsince there is no index behind the order by, it depends on whether there is a suitable index in the where condition. The query selector selects the single-column index rx_status, and the data rows restricted under the condition rx_status=5 are continuous in the index, even if the required rx_id It is not in the index, and there is still time to return to the primary key cluster index. Since there is no index behind the order by, the disk-level sorting filesort is used. When the peak backlog is 10,000 to 20,000, it runs to 100ms. During the daytime, hundreds of Just 20ms.
2. After the new index is added, there are two situations:
2.1. The index is added at night, and the number of currently hit rows is relatively small. Since there are indeed very few prescriptions to be reviewed that night, that is, there are indeed very few prescriptions with rx_status=5. The query optimizer feels that there are not many rows anyway, and the sorting is not good. Important, so choose the rx_status index.
2.2. During the next day, there are a lot of prescriptions to be reviewed (the amount of data in rx_status=5 is too much), and tens of thousands of data can be hit at that time. If the number of hit rows is relatively large, the query optimizer will start to calculate the cost. The cost of sorting will be higher, so the priority is to keep the sorting, so I choose the field rx_create_time, but there is no information about other index fields on this index tree, there is no way, almost every piece of data has to be returned to the table, which leads to disaster .
8. Recommended books
This book writes some operating mechanisms of MySQL in a witty and humorous style, which is very suitable for reading and the cost of understanding is greatly reduced.
https://item.jd.com/13009316.html

https://item.jd.com/10066181997303.html

9. Some insights
The performance optimization of the database is actually a very complicated topic, and it is difficult to talk about it comprehensively and profoundly through a post, which is why my title is “Analysis”. The growth of programmers must pay a price and Cost, because only when you really experience the tension and pressure at the time on the front line, can you be impressed by one thing, but on the contrary, you can’t emphasize the cost too much. If you can share with others, you can avoid some of your own business problems and problems. The price of being wrong is also good.
#Analysis #MySQL #Performance #Optimization #Online #Cases #Cloud #Developers #Personal #Space #News Fast Delivery