Summary:RocketMQ’s excellent performance cannot be avoided without its excellent storage model.
This article is shared from Huawei Cloud Community “Finally Figured Out the Storage Model of RocketMQ”, author: Brother Yong java actual combat sharing.
RocketMQ’s excellent performance cannot be avoided without its excellent storage model.
1 Overall overview
First review the RocketMQ architecture.
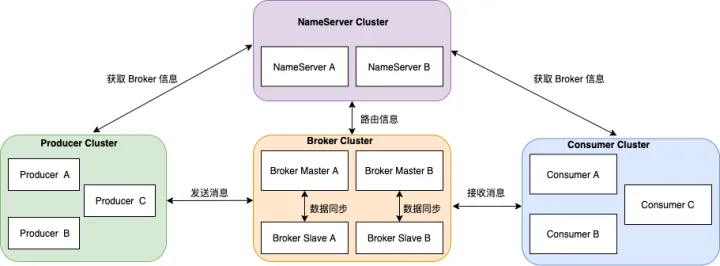
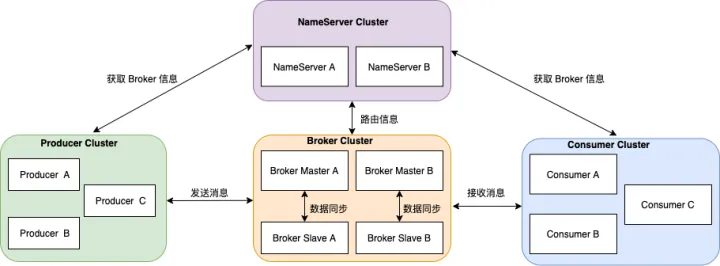
There are four roles in the overall architecture:
- Producer: The role of message publishing. Producer selects the corresponding Broker cluster queue for message delivery through the MQ load balancing module. The delivery process supports fast failure and low latency.
- Consumer: The role of message consumption, which supports two modes of push and pull to consume messages.
- NameServer: The name service is a very simple topic routing registry, its role is similar to the zookeeper in Dubbo, and it supports the dynamic registration and discovery of Broker.
- BrokerServer: Broker is mainly responsible for the storage, delivery and query of messages and the guarantee of high availability of services.
The focus of this article is to analyze the message storage model of BrokerServer. We first enter the file storage directory of the broker.

The message store is very closely related to the following three files:
1. Data file commitlog
The main body of the message and the storage body of the metadata;
2. Consume file consumequeue
The message consumption queue is mainly introduced to improve the performance of message consumption;
3. Index file index
The index file provides a way to query messages by key or time interval.
RocketMQ adopts a hybrid storage structure. All queues under a single Broker instance share a data file (commitlog) for storage.
The producer sends a message to the Broker side, and then the Broker side uses a synchronous or asynchronous method to flush and persist the message and save it to the commitlog file. As long as the message is flushed and persisted to the disk file commitlog, the message sent by the producer will not be lost.
The background service thread on the Broker side will continuously distribute requests and build consumequeue (consumption file) and indexFile (index file) asynchronously.
2 data files
The message data of RocketMQ will be written into the data file, which we call commitlog.
All messages will be written to the data file sequentially, and when the file is full, it will be written to the next file.

As shown in the figure above, the default size of a single file is 1G, the length of the file name is 20 digits, the left is filled with zeros, and the rest is the starting offset. For example, 00000000000000000000 represents the first file, the starting offset is 0, and the file size is 1 G = 1073741824.
When the first file is full, the second file is 00000000001073741824, the starting offset is 1073741824, and so on.
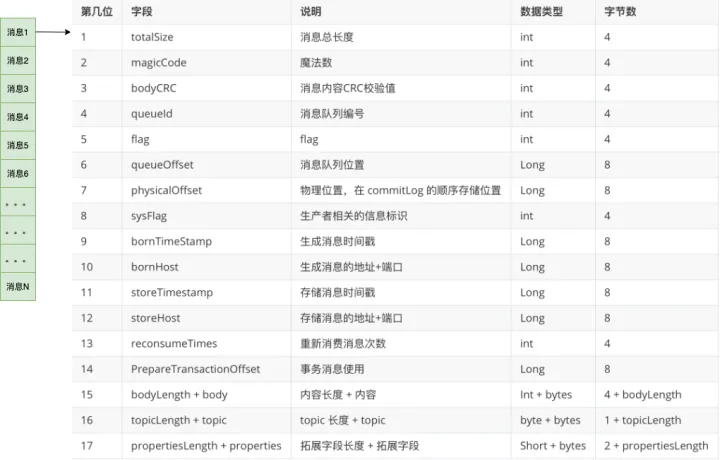
From the figure above, we can see that the messages are written to the file one by one, and the format of each message is fixed.
This design has three advantages:
1. Write in order
The disk access speed is not as fast as that of memory. The time-consuming of a disk IO mainly depends on: seek time and disk rotation time. The most effective way to improve disk IO performance is to reduce random IO and increase sequential IO.
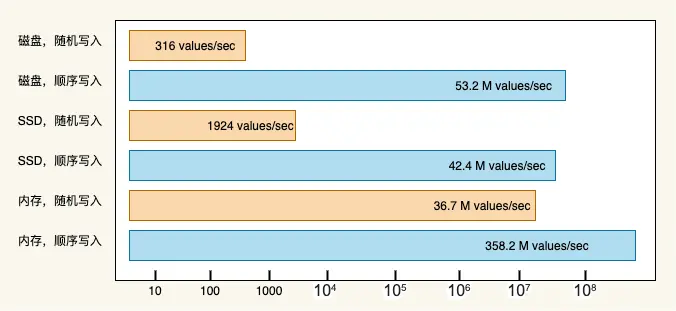
The article “The Pathologies of Big Data” pointed out that the speed of random read and write of memory is much lower than the speed of sequential read and write of disk. The sequential write speed of the disk can reach hundreds of MB/s, while the random write speed is only a few hundred KB/s, a difference of thousands of times.
2. Quick positioning
Because the messages are written to the commitlog file one by one, after the writing is completed, we can get the physical offset of the message.
The physical offset of each message is unique, and the commitlog file name is incremented, which can be passed according to the physical offset of the messagebinary searchlocate the file in which the message is located, and obtain the message entity data.
3. Query message data through message offsetMsgId
The message offsetMsgId is generated by the Broker server when writing a message, and the message contains two parts:
- Broker server ip + port 8 bytes;
- The commitlog physical offset is 8 bytes.
We can locate the Broker’s ip address + port through the message offsetMsgId, and pass the physical offset parameter to locate the message entity data.
3 consumption documents
Before introducing the consumequeue file, let’s review the transmission model of the message queue –Publish Subscribe Model which is also the current transport model of RocketMQ.
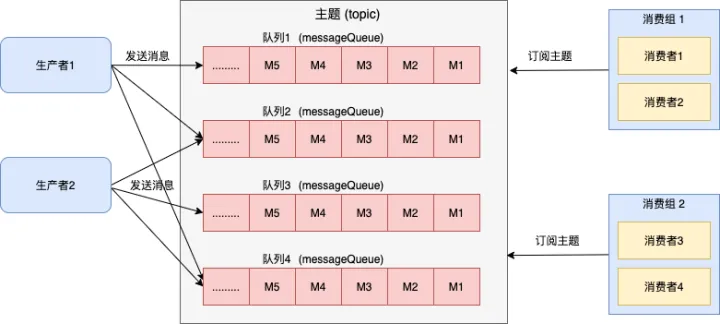
The publish-subscribe model has the following characteristics:
- Consumption independence: Compared with the anonymous consumption method of the queue model, the identity of the consumer in the publish-subscribe model is generally called a subscription group (subscription relationship), and different subscription groups are independent of each other and will not affect each other.
- One-to-many communication: Based on the design of independent identities, messages in the same topic can be processed by multiple subscription groups, and each subscription group can get the full amount of messages. Therefore, the publish-subscribe model can realize one-to-many communication.
therefore,The file design of rocketmq must meet the requirements of the publish-subscribe model.
So can only the commitlog file meet the demand?
If there is a consumerGroup consumer who subscribes to the topic my-mac-topic, because the commitlog contains all message data, querying the message data under this topic needs to traverse the data file commitlog, which is extremely inefficient.
Enter the rocketmq storage directory, as shown in the figure below:
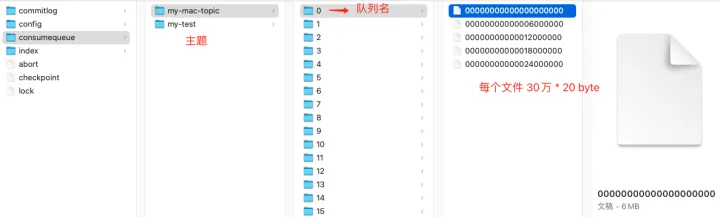
- Consumption files are stored according to topics, and there are different queues under each topic. In the figure, there are 16 queues in my-mac-topic;
- Under each queue directory, consumequeue files are stored, and each consumequeue file is also written sequentially. The data format is shown in the figure below.
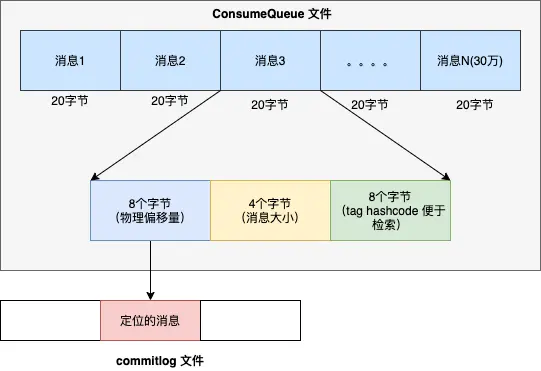
Each consumequeue contains 300,000 entries, the size of each entry is 20 bytes, the size of each file is 300,000 * 20 = 600,000 bytes, and the size of each file is about 5.72M. Similar to the commitlog file, the name of the consumequeue file is also named after the offset, and the logical offset of the message can be used to locate which file the message is located in.
consumption documents according totopic-queueto save, this method is especially suitable forPublish Subscribe Model.
When consumers obtain subscription message data from the broker, they do not need to traverse the entire commitlog file, but only need to query the message offset from the consumequeue file according to the logical offset, and finally obtain the real message data by locating the commitlog file.
In this way, the consumption query logic can be simplified, and at the same time, consumers can subscribe to different queues or tags under the same topic, which improves the scalability of the system.
4 index file
The unique identification code of each message at the business level should be set in the keys field to facilitate future location of message loss issues. The server will create an index (hash index) for each message, and the application can query the content of the message and who consumes the message through topic and key.
Since it is a hash index, please make sure that the key is as unique as possible, so as to avoid potential hash conflicts.
//订单Id
String orderId = "1234567890";
message.setKeys(orderId); Query the message list according to the topic and key from the open source console:
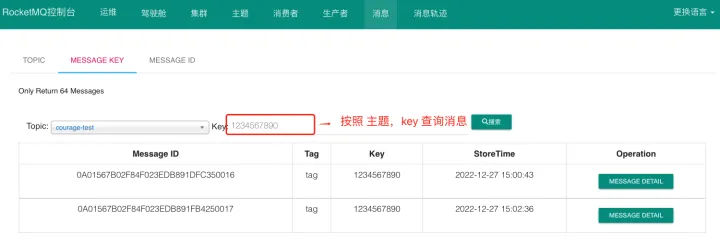
Enter the index file directory, as shown in the figure below:
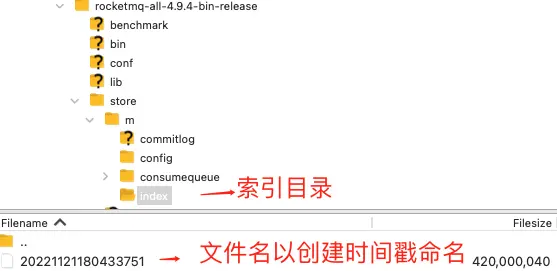
The index file name fileName is named after the time stamp when it was created, and the fixed single IndexFile file size is about 400M.
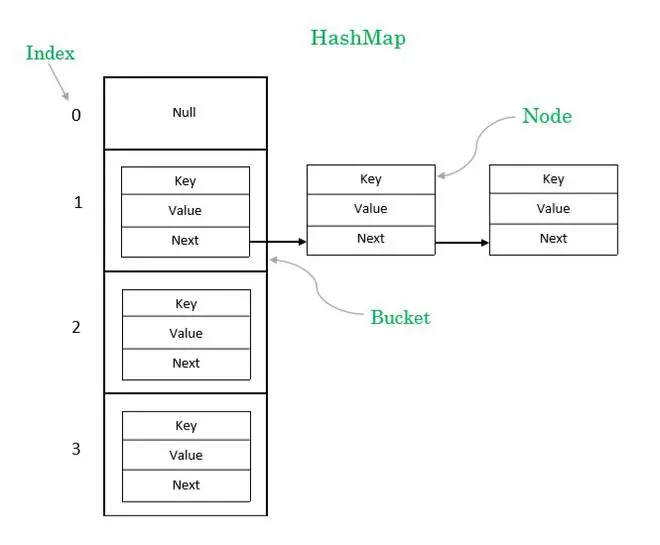
The file logic structure of IndexFile is similar to that of JDK’s HashMaparray plus linked liststructure.
The index file is mainly composed of three parts: Header, Slot Table (5 million entries by default), and Index Linked List (up to 20 million entries by default).
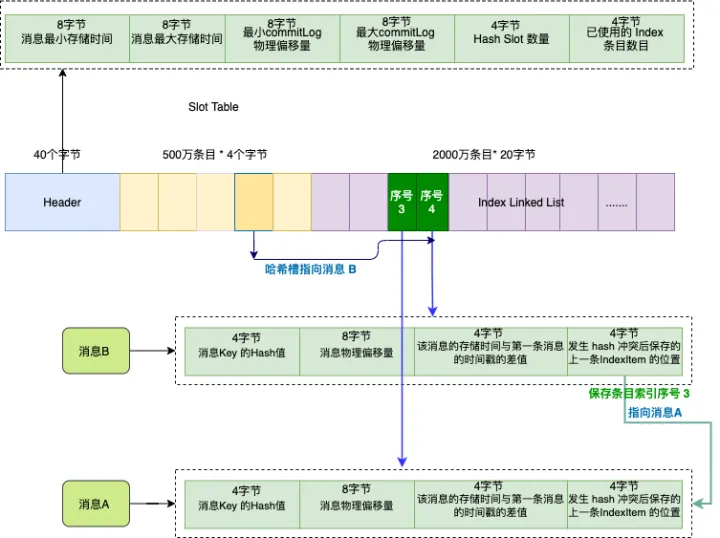
If the order system sends two messages A and B, their keys are both “1234567890”, we store message A and message B in turn.
Because the hash values of the keys of these two messages are the same, their corresponding hash slots (dark yellow) will also be the same, and the hash slot will save the index entry number of the latest message B, and the number value is 4, which is the second dark green entries.
The last 4 bytes of the index entry information of message B will store the index entry number corresponding to the previous message, and the index number value is 3, which is message A.
5 write to the end
Databases are specializing – the “one size fits all” approach no longer applies —— MongoDB Design Philosophy
The RocketMQ storage model is designed very delicately. The author thinks that each design has its underlying thinking. Here are three points:
- Perfectly adapt to the message queue publish-subscribe model;
- Data files, consumption files, and index files each perform their own duties. At the same time, with data files as the core, the mode of asynchronously building consumption files + index files is very easy to expand to the architecture of master-slave replication;
- Fully consider the business query scenario, support message key, message offsetMsgId query message data. It also supports consumers to subscribe to different messages under the topic through tags, which improves the flexibility of consumers.
Click to follow and learn about Huawei Cloud’s fresh technologies for the first time~
#detailed #explanation #RocketMQs #storage #model #HUAWEI #CLOUD #Developer #Alliances #personal #space #News Fast Delivery