At last year’s DevCon, Huang Dongxu, co-founder and CTO of PingCAP, put forward a conjecture: “The database itself will die as a software form, and the platformization and micro-service of the database will replace the original database software form.” Today, this conjecture It is being proven—almost all database vendors provide services on the cloud, and many databases are strengthening their cloud-native attributes.
So, after cloud native, what’s next for databases? On December 1, at the PingCAP DevCon 2022 conference, Huang Dongxu gave the answer: Serverless.
In the past year, PingCAP has been busy turning database technology into a database cloud service, and finally TiDB Cloud was born. Since this year, Serverless has become the key technical direction of PingcCAP.
It is generally believed in the industry that Serverless can be traced back to the introduction of serverless cloud functions such as AWS Lambda, which allows developers to start and stop applications through simple API calls. Developers don’t need to configure any hardware for it to run code. Later, this concept was extended to the field of databases.
Serverless is often translated as “serverless”, but Huang Dongxu believes that it should be called “serverless”. Then in the higher dimension of software development, it is “technology ineffective”. He said that the core of Serverless is to reduce the complexity of the database step by step through higher-level abstraction. In this way, developers can use the database with little awareness of specific technologies.
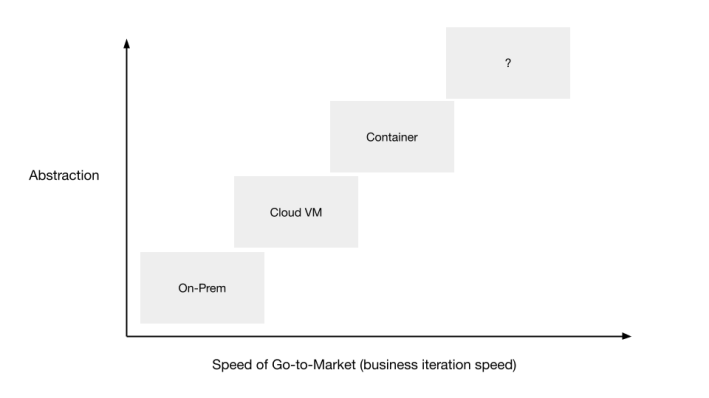
In order to better understand the relationship between Serverless and development efficiency, Huang Dongxu introduced the concept of “abstract”.
Twenty years ago, if a website was to be built, developers had to spend a lot of time on things unrelated to the business, such as buying servers, renting computer rooms, and renting the Internet, in addition to writing code. The level of abstraction was very low, and the iteration speed very slow.
Then, the emergence of the public cloud abstracted away the complexity of data centers such as hardware, deployment, and networks, and turned them into virtual machines. To develop an application, you only need to open an account on the public cloud, deploy the application, and pay monthly. This is a step faster than going to the data center by yourself.
Next, the concept of cloud native emerged. The original computing unit is a VM virtual machine. In the cloud-native world, the computing unit is further abstracted into a Container. Container is a higher-level abstraction than VM virtual machine. In the era of virtual machines, you still have to consider what to do if the VM hangs up, but in the container world, the container and the underlying cloud scheduler don’t care, and these are all abstracted away. This means that cloud-native software development iterations can be much faster than traditional VM-based abstractions.
Although it has come to the era of cloud native and the development efficiency has been improved unprecedentedly, Huang Dongxu still thinks it is not enough. He said that development efficiency is low, and developers have no time to focus on business innovation, which is an important reason that hinders the further deepening of digital transformation.Inapps Researchsupports this view. “Developers spend 41% of their time each day on infrastructure maintenance rather than innovating or bringing new products to market.”
In practice, this reason is usually ignored by many people, but as a developer, Huang Dongxu has a deep understanding of it. “When I am ambitious to develop a new application, the actual development time may only take up 10%-20% of the whole time. A lot of time is spent on buying servers, deploying databases, data backup and recovery, CI/CD Build it, not develop the app.”
In addition to the complexity of the data architecture system itself, the multi-point blooming of database technology has also become the pressure on developers.
When I was in college, my teacher told Huang Dongxu that the database is very simple, you only need to know how to write SQL. But after working, Huang Dongxu discovered that in addition to SQL, there are also OLTP, OLAP, time-series databases, graph databases, and all kinds of strange databases, and each database has its own complex concepts and operation and maintenance. If you want to use it well They have to learn a lot of things.
“There is a very real joke in the industry: don’t release it, don’t make new things, I really can’t learn anymore… these complex concepts are not hidden now, but are all transparently passed on Developer.” Huang Dongxu said: “I have always wanted to bring the database back to the time when I was in college, how simple it was then.”
This is exactly what PingCAP is doing: Serverless. This is also what PingCAP believes is the next direction of the database after cloud native. A month ago, PingCAP released TiDB’s Serverless cloud service—— TiDB Cloud Serverless Tier.
It is understood that TiDB Cloud Serverless Tier has four major features:
- One is that the database kernel is stable, and it can provide very hard-core basic capabilities such as good elasticity, automatic failover, and SQL on the cloud.
- Second, HTAP can provide real-time one-stack data services. Users don’t need to care about what is OLAP and what is OLTP. One system can support all loads, and there is no need to worry about OLAP loads affecting normal OLTP services.
- The third is that the cost of serverless deployment is extremely low, and you don’t need to care about any details of operation and maintenance. The start and stop of the cluster can be controlled through code and open API. Especially when dealing with more complex or larger systems, serverless can significantly reduce complexity.
- The fourth is real on-demand billing. Serverless can truly bill according to resource consumption. For developers, when they want to use the database, they can call it immediately, and when they don’t use it, they don’t need to pay. Access at any time, the database can provide external services.
Huang Dongxu said that one of the principles of designing TiDB Cloud Serverless Tier is to make full use of different services provided by the cloud, such as Spot Instances, S3, EBS, and elastic Load Balancer. It effectively integrates and ingeniously schedules all elastic resources on the cloud, providing users with an extremely elastic experience. “The user experience is a step forward from the original cloud-native database, with fewer details and a higher level of abstraction.”
He also said that the serverless architecture can unlock more possibilities. “Take S3, a cloud object storage service heavily relied on under TiDB Serverless Tier, as an example. User A uses S3, and user B also uses S3. Data sharing becomes very simple. But in a private environment, the data must be downloaded first. Copy a copy, upload it, and then analyze it. If the amount of data is relatively large, this is almost unimaginable. And the serverless architecture is technically capable of data sharing.”

For now, PingCAP is just the first step on the road to Serverless.
Regarding the future of Serverless, Liu Song, vice president of PingCAP, has long imagined: “The programming paradigm of the next generation of application developers will undergo major changes because of the ‘technology-insensitive’ technology like Serverless. All cloud vendors in the future, Including database vendors have begun to enter the serverless ticket. The last fundamental change is that after three to five years, 90% of application developers don’t need to care about what a database is.”
Huang Dongxu thought further. “In the future, the focus of application developers on databases will change from databases to APIs, and even in the longer term, they only need to focus on web front-end development.”
#cloud #native #direction #database #Personal #space #News Fast Delivery #editorial #department #News Fast Delivery