Author: Qian Yan, Presence
A guide
In recent years, self-supervised learning and Transformers have made a big splash in the field of vision. Image self-supervised pre-training greatly reduces the heavy labeling work of image tasks and saves a lot of labor costs. The great success of transformer technology in the field of NLP also provides a great imagination for the further improvement of the effect of CV models. In order to promote the implementation of self-supervised learning and visual Transformer on Alibaba Group and Alibaba Cloud, Alibaba Cloud’s machine learning platform PAI has created the EasyCV all-in-one visual modeling tool, built a rich and complete self-supervised algorithm system, and provided effective results. SOTA’s visual Transformer pre-training model, modelzoo covers image self-supervised training, image classification, metric learning, object detection, key point detection and other fields, and provides developers with out-of-the-box training and reasoning capabilities, while training / reasoning Efficiency has also been deeply optimized. In addition, EasyCV is fully compatible with the Alibaba Lingjie system, and users can easily use all the functions of EasyCV in the Alibaba Cloud environment.
After being fully polished by Alibaba’s internal business, we hope to push the EasyCV framework to the community to further serve the vast number of CV algorithm developers and enthusiasts, so that they can experience the latest image self-supervision and transformer technology very quickly and easily, and implement it. into their own business production.
How is the algorithm framework behind EasyCV designed? How can developers use it? What are the plans for the future? Let’s learn more about it today.
2. What is EasyCV
EasyCV is Alibaba’s open source Pytorch-based all-in-one visual algorithm modeling tool with self-supervised learning and Transformer technology as the core. EasyCV supports multiple BU businesses such as Search, Tao Department, Youku, and Fliggy in Alibaba Group, and also serves several enterprise customers on Alibaba Cloud. The need to solve business problems.
Project open source address: https://github.com/alibaba/EasyCV
1 Project Background
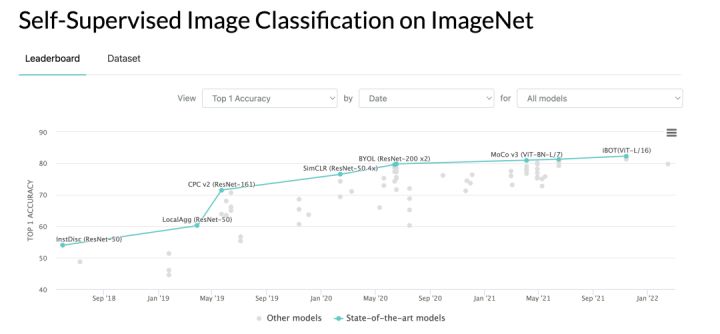
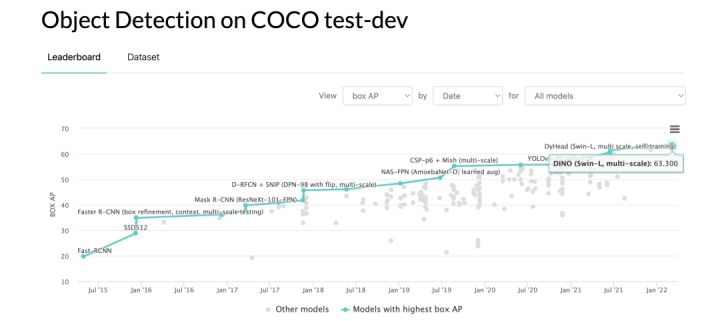
In the past two years, image self-supervised pre-training technology based on unlabeled training data has developed rapidly, and the effect of each visual task has been comparable to or even surpassed the effect of supervised training that requires a large number of labels; on the other hand, it has achieved great success in the field of NLP. The Transformer technology further refreshes the SOTA effect on each image task, and its application presents a blowout explosion. As a combination of the two, the pre-training of self-supervised visual Transformer also came into being.
The industry’s self-supervised learning and visual Transformer algorithm technology updates and iterations are very fast, and at the same time, it also brings a lot of trouble to CV algorithm developers, such as scattered open source code, uneven implementation methods and styles, resulting in high learning and reproduction costs, training , low inference performance, etc. By building a flexible and easy-to-use algorithm framework EasyCV, the Alibaba Cloud PAI team systematically precipitates SOTA’s self-supervised algorithm and Transformer pre-training model, encapsulates a unified, simple and easy-to-use interface, and optimizes performance for self-supervised big data training. Users try the latest self-supervised pre-training technology and Transformer model to promote the application and implementation in business.
In addition, based on the deep learning training and inference acceleration technology accumulated by the PAI team for many years, IO optimization, model training acceleration, quantitative cutting and other functions are also integrated in EasyCV, which has its own advantages in performance. Based on Alibaba Cloud’s PAI product ecosystem, users can easily perform model management, online service deployment, and large-scale offline reasoning tasks.
2 Main Features
- Rich and complete self-supervision algorithm system: including the industry’s representative image self-supervision algorithms SimCLR, MoCO, Swav, Moby, DINO, etc., as well as the mask-based image pre-training method MAE, and provides detailed benchmark tools and reproduction results.
- Rich pre-training model library: Provides rich pre-training models, based on the transformer model, also includes mainstream CNN models, supports ImageNet pre-training and self-supervised pre-training. Compatible with PytorchImageModels to support a richer visual Transformer backbone.
- Ease of use and scalability: It supports configuration and API calls for training, evaluation, and model export; the framework adopts mainstream modular design, which is flexible and scalable.
- High performance: support multi-machine multi-card training and evaluation, fp16 training acceleration. In view of the large amount of data in self-supervised scenarios, DALI and TFRecord files are used to accelerate IO. Connect to Alibaba Cloud’s machine learning PAI platform for training acceleration and model inference optimization.
Three main technical features
1 Technical Architecture
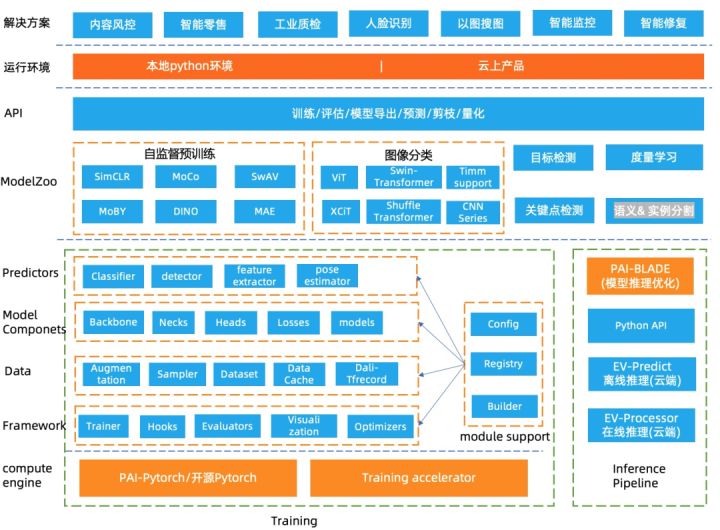
The underlying engine of EasyCV is based on Pytorch and is connected to the Pytorch training accelerator for training acceleration. The algorithm framework is mainly divided into the following layers:
- Framework layer: The framework layer reuses the openmmlab/mmcv interface that is widely used in the open source field at present, controls the main process of training through Trainer, and customizes Hooks for learning rate control, log printing, gradient update, model saving, evaluation and other operations, and supports distribution training and assessment. The Evaluators module provides evaluation indicators for different tasks, supports multi-dataset evaluation, optimal ckpt preservation, and supports user-defined evaluation indicators. Visualization supports visualization of prediction results and input images.
- Data layer: Provides abstraction of different data sources (data_source), supports a variety of open source data sets such as Cifar, ImageNet, CoCo, etc., supports raw image file format and TFrecord format, TFrecord format data supports data processing acceleration using DALI, raw format Image support speeds up data reading through a caching mechanism. The data preprocessing (data enhancement) process is abstracted into several independent pipelines, and different preprocessing processes can be flexibly configured by means of configuration files.
- Model layer: The model layer is divided into modules and algorithms. The modules provide basic backbone, commonly used loss, neck and head of various downstream tasks. The model ModelZoo covers self-supervised learning algorithms, image classification, metric learning, target detection and key points The detection algorithm will continue to expand to support more high-level algorithms in the future.
- Inference: EasyCV provides an end-to-end inference API interface, supports PAI-Blade for inference optimization, and supports off-line inference on cloud products.
- API layer: Provides a unified API for training, evaluation, model export, and prediction.
EasyCV supports convenient operation and debugging in the local environment. At the same time, if users want to run large-scale production tasks, we also support convenient deployment in aliyun PAI products.
2 Perfect self-supervision algorithm system
Self-supervised learning does not require data annotation, and the introduction of contrastive learning makes its effect gradually approaching supervised learning, which has become one of the focuses of academic and industrial circles in recent years. EasyCV includes mainstream self-supervised algorithms based on contrastive learning, including SimCLR, MoCo v1/v2, Swav, Moby, DINO. The MAE algorithm based on mask image modeling is also reproduced. In addition, we provide comprehensive benchmark tools to evaluate the performance of self-supervised pre-trained models on ImageNet.
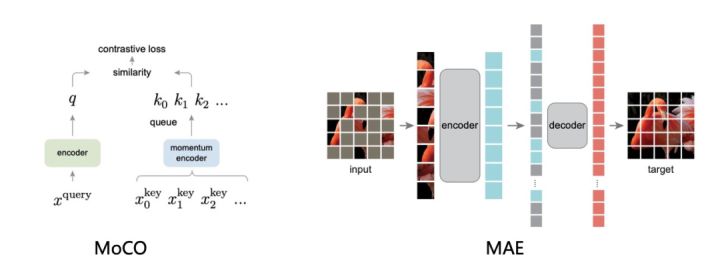
Based on systematic self-supervision algorithms and benchmark tools, users can easily improve models, compare effects, and innovate models. At the same time, you can also train a better pre-training model suitable for your business field based on your own large amount of unlabeled data.
The table below shows the speed of existing self-supervised algorithms pre-trained on ImageNet data and the effect of linear eval/finetune on the ImageNet validation set.
| Model | DALITFRecord(samples/s) | JPG(samples/s) | performance boost | Remark |
| dino_deit_small_p16 | 492.3 | 204.8 | 140% | fp16 batch_size=32×8 |
| moby_deit_small_p16 | 1312.8 | 1089.3 | 20.5% | fp16 batch_size=128×8 |
| mocov2_resnet50 | 2164.9 | 1365.3 | 58.56% | fp16 batch_size=128×8 |
| swav_resnet50 | 1024.0 | 853.3 | 20% | fp16 batch_size=128×8 |
3 Rich pre-trained model library
CNN, as the backbone network, cooperates with the heads of various downstream tasks, and is a commonly used structure for CV models. EasyCV provides a variety of traditional CNN network structures, including resnet, resnext, hrNet, darknet, inception, mobilenet, genet, mnasnet, etc. With the development of visual Transformer, Transformer replaces CNN in more and more fields and becomes a backbone network with stronger expressive ability. The framework implements commonly used ViT, SwinTransformer, etc., and introduces PytorchImageModel (Timm) to support a more comprehensive Transformer structure.
Combined with the self-supervised algorithm, all models support self-supervised pre-training and ImageNet data supervised training, providing users with a wealth of pre-training backbones, users can simply configure and use in the downstream tasks preset by the framework, and can also access self-supervised training. in the defined downstream tasks.
4 Ease of use
1. The framework provides parameterization and python api interface to start training, evaluation, model export, and provides a complete prediction interface to support end-to-end reasoning.
1.# 配置文件方式
2.python tools/train.py configs/classification/cifar10/r50.py --work_dir work_dirs/classification/cifar10/r50 --fp16
3.
4.
5.# 简易传参方式
6.python tools/train.py --model_type Classification --model.num_classes 10 --data.data_source.type ClsSourceImageList --data.data_source.list data/train.txt API way
1.import easycv.tools
2.config_path="configs/classification/cifar10/r50.py"
3.easycv.tools.train(config_path, gpus=8, fp16=False, master_port=29527)Inference example
1.import cv2
2.from easycv.predictors.classifier import TorchClassifier
3.
4.output_ckpt="work_dirs/classification/cifar10/r50/epoch_350_export.pth"
5.tcls = TorchClassifier(output_ckpt)
6.
7.img = cv2.imread('aeroplane_s_000004.png')
8.# input image should be RGB order
9.img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
10.output = tcls.predict([img])
11.print(output) 2. The framework currently focuses on high-level visual tasks, and three major tasks are divided into classification and detection, based on content risk control, smart retail, smart monitoring, same-image matching, commodity category prediction, commodity detection, commodity attribute identification, and industrial quality inspection. and other application scenarios, based on Alibaba’s internal business practices and the experience of serving Alibaba Cloud’s external customers, the SOTA algorithm with the reproducible effect is screened, and the pre-training model is provided to open up the training, inference, and device-side deployment process, so as to facilitate users to customize the application in each scenario. chemical development. For example, in the field of detection, we have reproduced the YOLOX algorithm, integrated the model compression functions of PAI-Blade such as pruning and quantization, and can export the MNN model for end-to-end deployment. For details, please refer to the model compression and quantization tutorial.
5 Scalability
1. As shown on the right side of the technical architecture diagram, all modules support registration and are automatically created by Builder through configuration file configuration, which allows each module to be flexibly combined and replaced through configuration. The following takes the model and evaluator configuration as an example, the user can simply modify the configuration file to switch between different backbones and different classification heads to adjust the model structure. In terms of evaluation, users can specify multiple data sets and use different evaluators for multi-index evaluation.
1.model = dict(
2. type="Classification",
3. pretrained=None,
4. backbone=dict(
5. type="ResNet",
6. depth=50,
7. out_indices=[4], # 0: conv-1, x: stage-x
8. norm_cfg=dict(type="SyncBN")),
9. head=dict(
10. type="ClsHead", with_avg_pool=True, in_channels=2048,
11. num_classes=1000))
12.
13.eval_config = dict(initial=True, interval=1, gpu_collect=True)
14.eval_pipelines = [
15. dict(
16. mode="test",
17. data=data['val1'],
18. dist_eval=True,
19. evaluators=[dict(type="ClsEvaluator", topk=(1, 5))],
20. ),
21. dict(
22. mode="test",
23. data=data['val2'],
24. dist_eval=True,
25. evaluators=[dict(type="RetrivalEvaluator", topk=(1, 5))],
26. )
27.] 2. Based on the registration mechanism, users can write customized modules such as neck, head, data pipeline, evaluator, etc., quickly register them in the framework, and create and call them by specifying the type field in the configuration file.
1.@NECKS.register_module()
2.class Projection(nn.Module):
3. """Customized neck."""
4. def __init__(self, input_size, output_size):
5. self.proj = nn.Linear(input_size, output_size)
6.
7. def forward(self, input):
8. return self.proj(input)
The configuration file is as follows
1.model = dict(
2. type="Classification",
3. backbone=dict(...),
4. neck=dict(
5. type="Projection",
6. input_size=2048,
7. output_size=512
8. ),
9. head=dict(
10. type="ClsHead",
11. embedding_size=512,
12. num_classes=1000) 6 High performance
In terms of training, it supports multi-machine multi-card, fp16 accelerated training and evaluation.
In addition, the framework will be optimized for specific tasks. For example, self-supervised training requires a large number of small images for pre-training. EasyCV uses tfrecord format data to encapsulate small files, and uses DALI to perform GPU acceleration for preprocessing to improve training optimization performance. . The following figure is the performance comparison of training using DALI+TFrecord format and the original image training.
| Model | DALITFRecord(samples/s) | JPG(samples/s) | performance boost | Remark |
| dino_deit_small_p16 | 492.3 | 204.8 | 140% | fp16 batch_size=32×8 |
| moby_deit_small_p16 | 1312.8 | 1089.3 | 20.5% | fp16 batch_size=128×8 |
| mocov2_resnet50 | 2164.9 | 1365.3 | 58.56% | fp16 batch_size=128×8 |
| swav_resnet50 | 1024.0 | 853.3 | 20% | fp16 batch_size=128×8 |
Test model: V100 16GB*8
Four application scenarios
As mentioned at the beginning, EasyCV supports 10+BU20+ businesses within Alibaba Group, and at the same time, it meets the needs of cloud-based customer customization models and solving business problems through platform-based components.
For example, a BU uses 100w pictures from the business gallery for self-supervised pre-training, and performs finetune on the downstream task based on the pre-trained model, which achieves the best effect, which is 1% higher than the baseline model. Many BU students use the self-supervised pre-training model for feature extraction, and use the characteristics of contrastive learning to use image features to perform the same image matching task. At the same time, we have also launched a similar image matching solution on the public cloud.
For public cloud users, for entry-level users, link data annotation, model training, and service deployment to create a smooth out-of-the-box user experience, covering image classification, object detection, instance segmentation, semantic segmentation, and key point detection For algorithms in other fields, users only need to specify the data, simply adjust the parameters to complete the model training, and complete the online service through one-click deployment. For advanced developers, it provides a notebook development environment, support for cloud-native cluster training scheduling, supports users to use the framework for customized algorithm development, and uses preset pre-training models for finetune.
- A customer of the public cloud uses the object detection component to customize the model training to complete the intelligent audit of whether the installation of workers in its business scenario is qualified.
- A recommended user uses the self-supervised training component to train the image representation model using a large number of unlabeled advertisement images, and then integrates the image features into the recommendation model. Combined with the optimization of the recommendation model, the ctr is increased by 10+%.
- A panel R&D manufacturer completed cloud training and end-to-end deployment reasoning based on the EasyCV customized defect detection model.
Five Roadmaps
In the future, we plan to release the Release version every month. The recent Roadmaps are as follows:
- Transformer classification task training performance optimization & benchmark
- Self-supervised learning increases detection & segmentation benchmark
- Develop more Transformer-based downstream tasks, detection & segmentation
- Common image task dataset download, training access interface support
- Model inference optimization function access
- End-to-end deployment support for more domain models
In addition, in the medium and long term, we will continue to invest in the following exploratory directions, and welcome feedback and improvement suggestions from various dimensions, as well as technical discussions. At the same time, we welcome and look forward to colleagues who are interested in open source community building. Participate in co-construction.
- Combining self-supervised technology and Transformer to explore more efficient pre-training models
- Lightweight Transformer, based on joint optimization of training and reasoning, promotes the implementation of Transformer in actual business scenarios
- Based on multimodal pre-training, explore the application of unified transformer in visual high-level multitasking
Project open source address: https://github.com/alibaba/EasyCV
To learn more about AI open source projects, please click: https://www.aliyun.com/activity/bigdata/opensource_bigdata__ai
#EasyCV #Open #Source #Outofthebox #visual #selfsupervision #Transformer #algorithm #library #News Fast Delivery #Chinese #open #source #technology #exchange #community