Stanford Alpaca (Stanford Alpaca) is an instruction-tuned LLaMA model fine-tuned from Meta’s large language model LLaMA 7B.
Stanford Alpaca lets OpenAI’s text-davinci-003 model generate 52K instruction-following samples in a self-instruct manner as Alpaca’s training data. The research team has open sourced the training data, codes for generating training data, and hyperparameters, and will release model weights and training codes later.
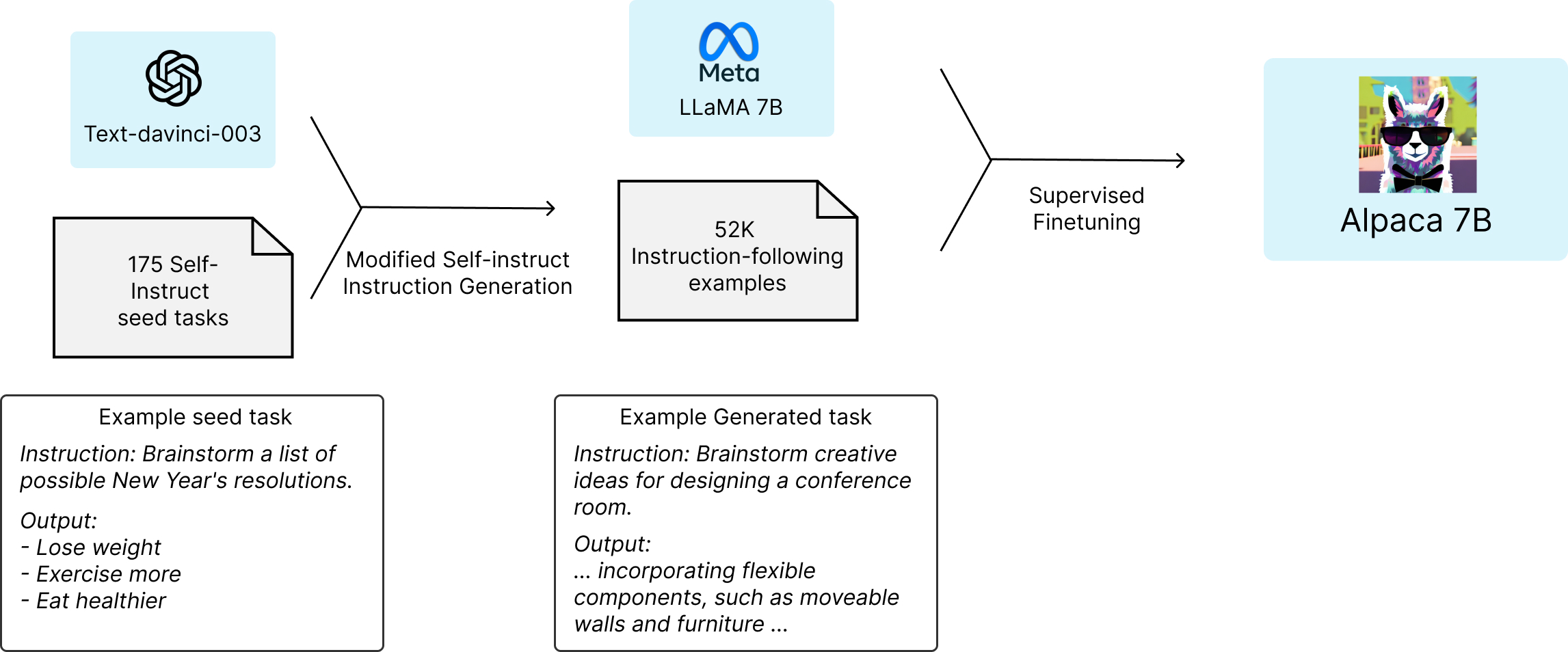
The GitHub repository contains:
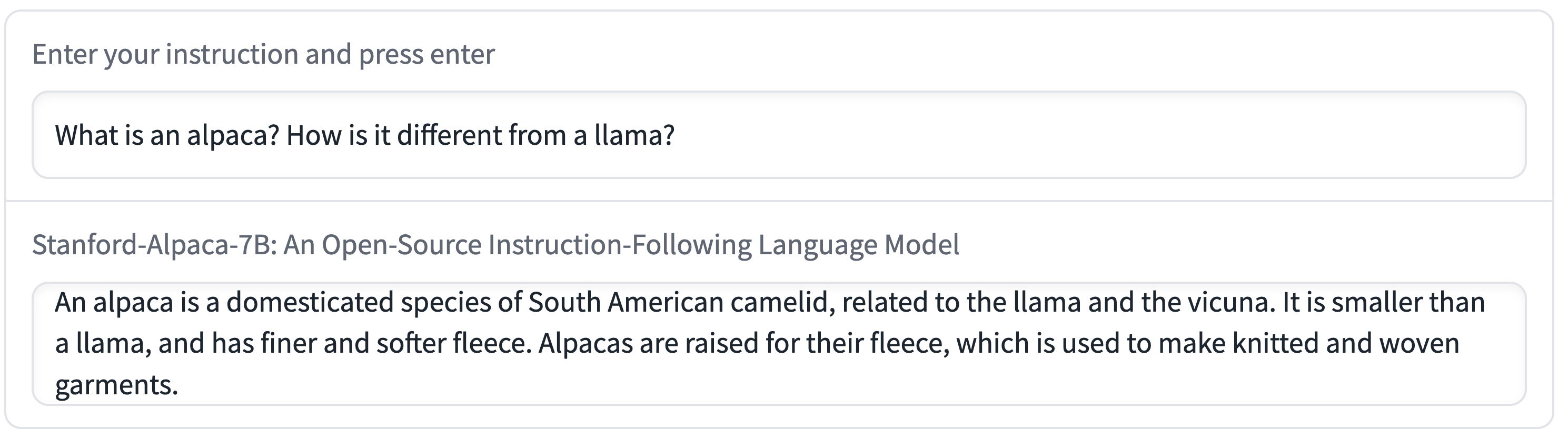
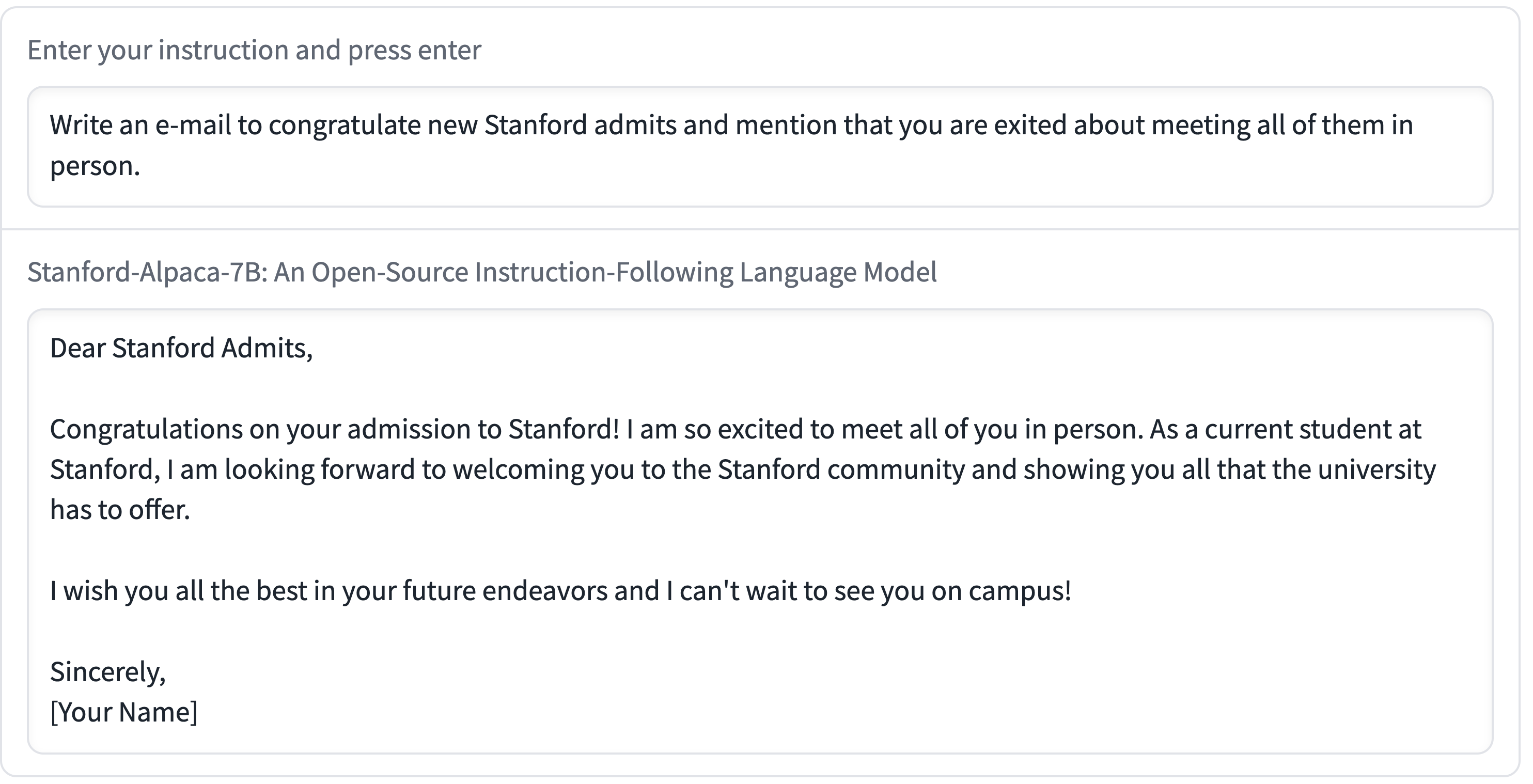
official example
#Stanford #Alpaca #Homepage #Documentation #Downloads #LLaMA #Model #Instruction #Tuning #News Fast Delivery