Open source address:
update content
1. Optimize reverse cache matching to obtain accurate key values. Use in(:keys) instead of like :nameKeyWords scenarios
<sql id="qstart_order_search">
<filters>
<!--
unmatched-return-self:缓存未匹配到key直接用名称代替(默认true)
cache-not-matched-value: 缓存未匹配到给一个默认值
-->
<cache-arg cache-name="staffIdName" param="staffName"
alias-name="staffIds" unmatched-return-self="true"/>
</filters>
<value>
<![CDATA[
select * from sqltoy_order_info where #[staff_id in (:staffIds)]
]]>
</value>
</sql>Key advantages of sqltoy:
//------------------了解 sqltoy的关键优势: -------------------------------------------------------------------------------------------*/
//1、最简最直观的sql编写方式(不仅仅是查询语句),采用条件参数前置处理规整法,让sql语句部分跟客户端保持高度一致
//2、sql中支持注释(规避了对hint特性的影响,知道hint吗?搜oracle hint),和动态更新加载,便于开发和后期维护整个过程的管理
//3、支持缓存翻译和反向缓存条件检索(通过缓存将名称匹配成精确的key),实现sql简化和性能大幅提升
//4、支持快速分页和分页优化功能,实现分页最高级别的优化,同时还考虑到了cte多个with as情况下的优化支持
//5、支持并行查询
//6、根本杜绝sql注入问题
//7、支持行列转换、分组汇总求平均、同比环比计算,在于用算法解决复杂sql,同时也解决了sql跨数据库问题
//8、支持保留字自动适配
//9、支持跨数据库函数自适配,从而非常有利于一套代码适应多种数据库便于产品化,比如oracle的nvl,当sql在mysql环境执行时自动替换为ifnull
//10、支持分库分表
//11、提供了取top、取random记录、树形表结构构造和递归查询支持、updateFetch单次交互完成修改和查询等实用的功能
//12、sqltoy的update、save、saveAll、load 等crud操作规避了jpa的缺陷,参见update(entity,String...forceUpdateProps)和updateFetch
//13、提供了极为人性化的条件处理:排它性条件、日期条件加减和提取月末月初处理等
//14、提供了查询结果日期、数字格式化、安全脱敏处理,让复杂的事情变得简单,大幅简化sql或结果的二次处理工作
//-----------------------------------------------------------------------------------*/Introduction to sqltoy features:
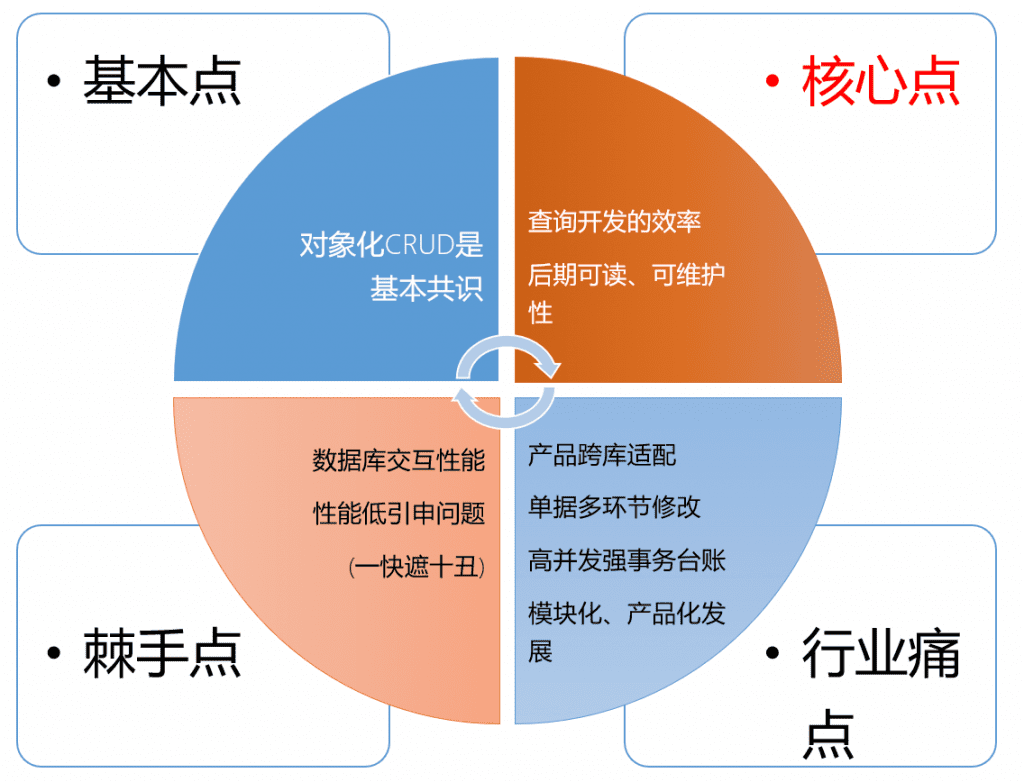
- The core construction idea of sqltoy
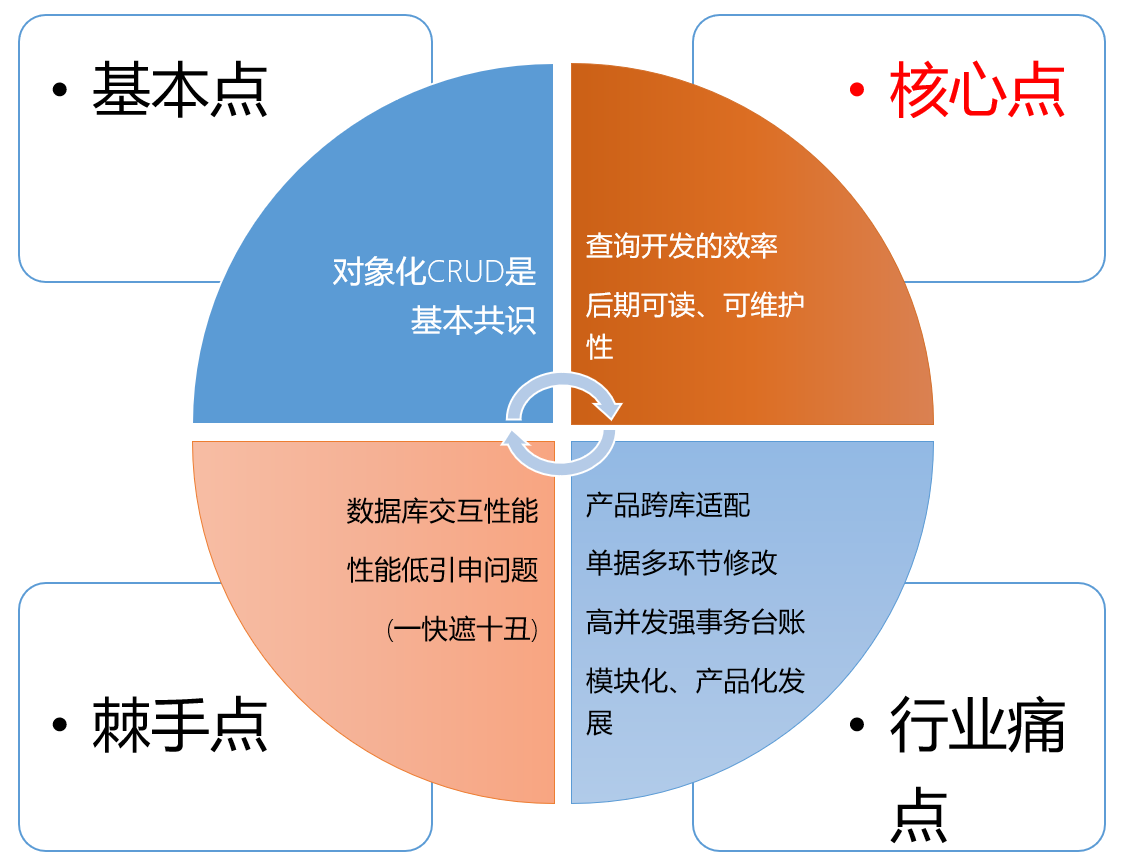
- The core points of sqltoy compared to mybatis (plus): query statement writing, readability, maintainability

- Object crud is the foundation, but sqltoy has targeted improvements: update, updateSaveFetch, updateFetch, etc.

- sqltoy’s cache translation greatly reduces table association and simplifies sql, making your query performance geometrically improved

- Extreme pagination also helps you achieve a significant improvement in query performance
- Fast paging: @fast () realizes fetching single-page data first and then associated query, which greatly improves the speed
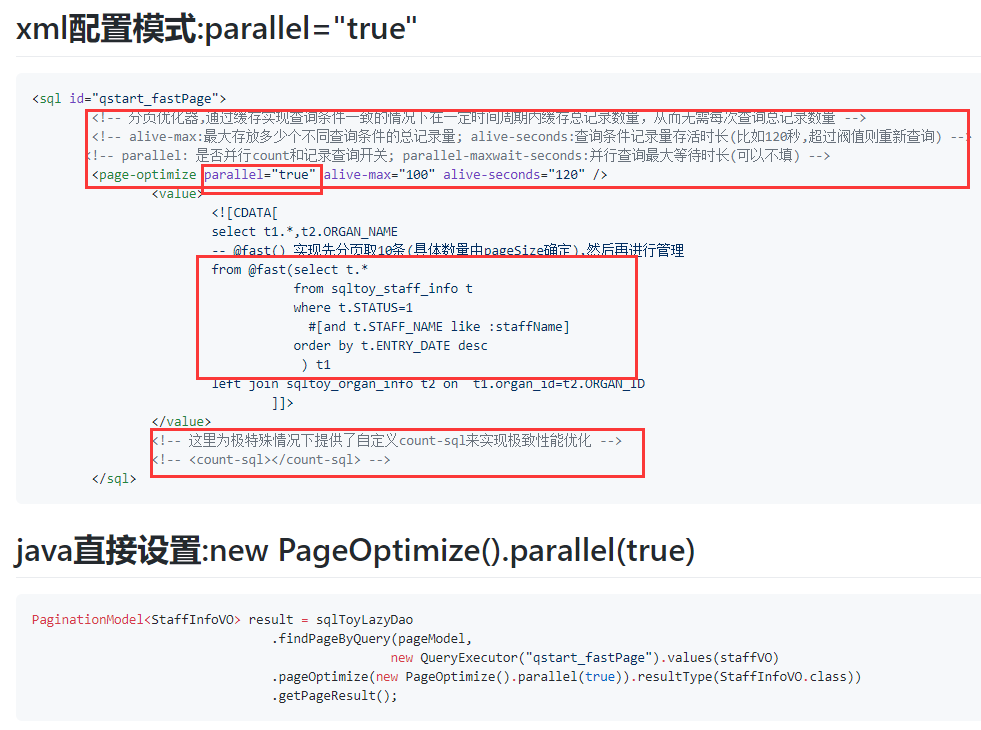
- Paging optimizer: page-optimize makes paging query from two times to 1.3~1.5 times (the total number of records with the same query condition can be realized in a cache without repeated query within a certain period
- The process of sqltoy’s pagination to fetch total records is not a simple select count (1) from (original sql); but an intelligent judgment whether to become: select count (1) from ‘from statement after’, and automatically remove the outermost order by
- sqltoy supports parallel query: parallel=”true”, query the total number of records and single-page data at the same time, greatly improving performance
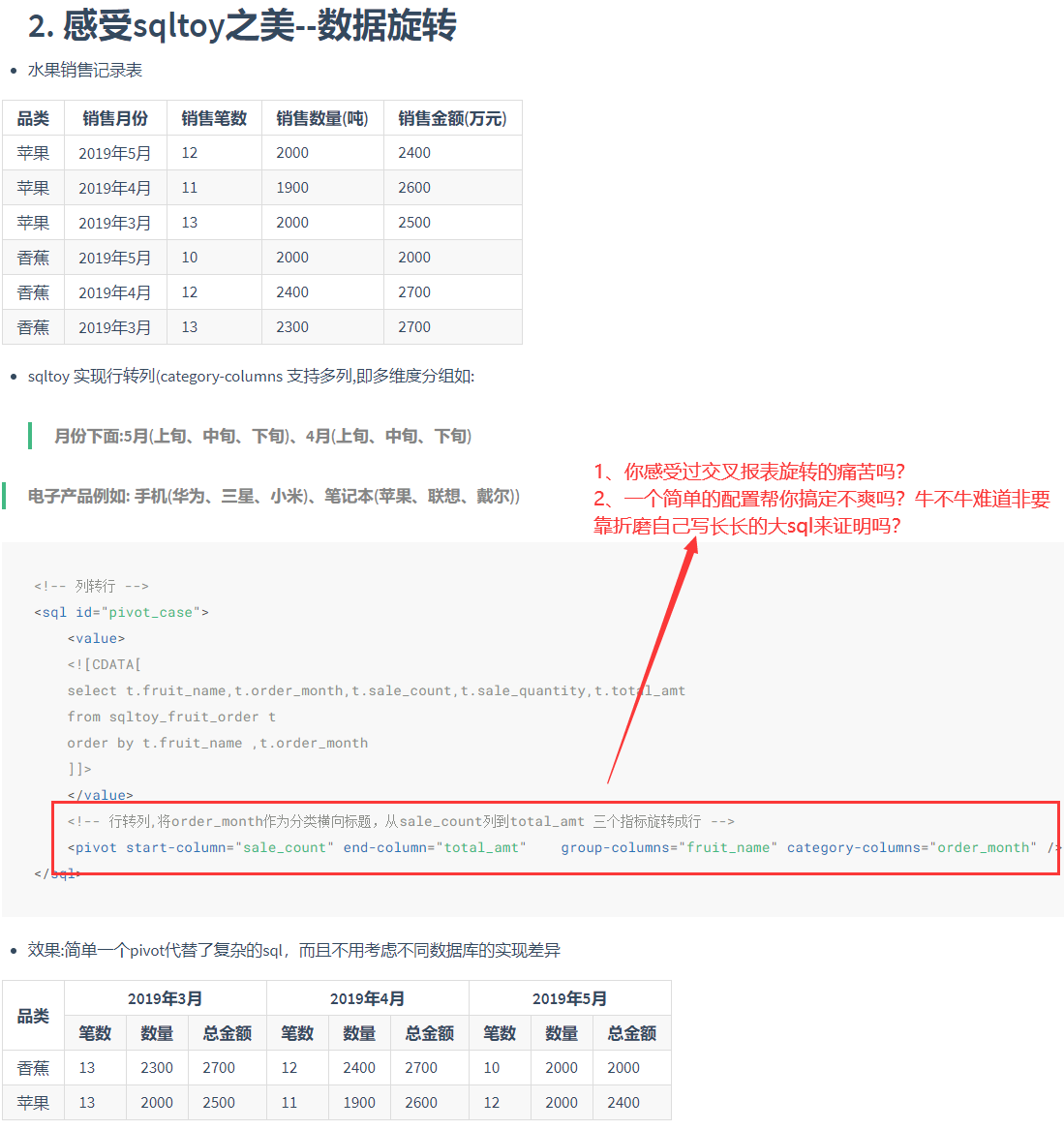
- Convenient Cross-Database Statistical Computing: Data Rotation
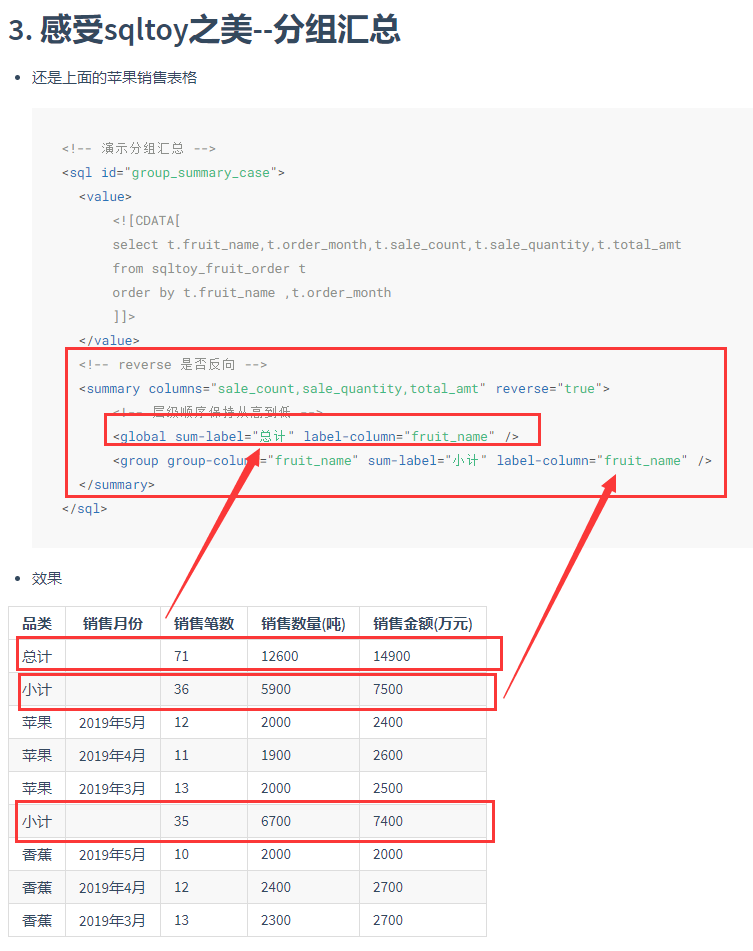
- Convenient cross-database statistical calculation: Infinitus group statistics (including summary and averaging)
- Convenient cross-database statistical calculation: year-on-year comparison

#intelligent #ORM #sagacitysqltoy5231 #released #News Fast Delivery