
Author: JD Logistics Zhao Shuai Yao Zaiyi Wang Xudong Meng Weijie Kong Xiangdong
1 Introduction
The logistics contract center is the only entrance for JD logistics contract management. Provide merchants with the ability to create and seal contracts, and provide contract customization, filing, and query functions for different business lines. Due to the large number of business lines, providing high-availability query capabilities for each business line is the top priority of the logistics contract center. At the same time, the billing system needs to query the contract center when each logistics order is settled to ensure the content of the contract signed by the merchant to ensure the accuracy of billing.
2 business scenarios
1. Query dimension analysis
From the perspective of the source of the business call, most of the contract is the billing system. When billing each logistics order, it needs to call the contract center to judge whether the merchant has signed the contract.

Judging from the input parameters of business calls, most of them use multiple conditions to query the contract, but basically they query a certain merchant, or query the contract through a certain attribute of the merchant (such as a business account).
Judging from the results of the calls, 40% of the queries have no results, and most of them are because the merchants have not signed the contract, resulting in empty queries. For the rest of the query results, the quantity returned each time is relatively small, and generally a merchant only has 3 to 5 contracts.
2. Analysis of call volume
Call volume The current call volume of the contract is about 20 million times per day.
Call volume statistics for a day: 
The daily peak period of calling time is working time, and the highest peak is 4W/min.
Call volume statistics for one month:
 It can be seen from the above that the daily call volume of the contract is relatively average, mainly concentrated from 9:00 to 12:00 and 13:00 to 18:00, that is, during working hours. The overall call volume is relatively high, and there is basically no sudden increase in calls.
It can be seen from the above that the daily call volume of the contract is relatively average, mainly concentrated from 9:00 to 12:00 and 13:00 to 18:00, that is, during working hours. The overall call volume is relatively high, and there is basically no sudden increase in calls.
From the overall analysis, the query volume of the contract center is relatively high and relatively average. It is basically a random query, and there is no hot data. Among them, invalid queries account for a large proportion. There are many query conditions each time, and the amount of returned data is relatively large. not big.
3 scheme design
From the analysis of the overall business scenario, we decided to implement three layers of protection to ensure the support of call volume, and at the same time, we need to handle data consistency. The first layer is a Bloom filter to intercept most invalid requests. The second layer is redis cache data to ensure that queries with various query conditions hit redis as much as possible. The third layer is a bottom-up solution for directly querying the database. At the same time, to ensure data consistency, we use broadcast mq to achieve it. 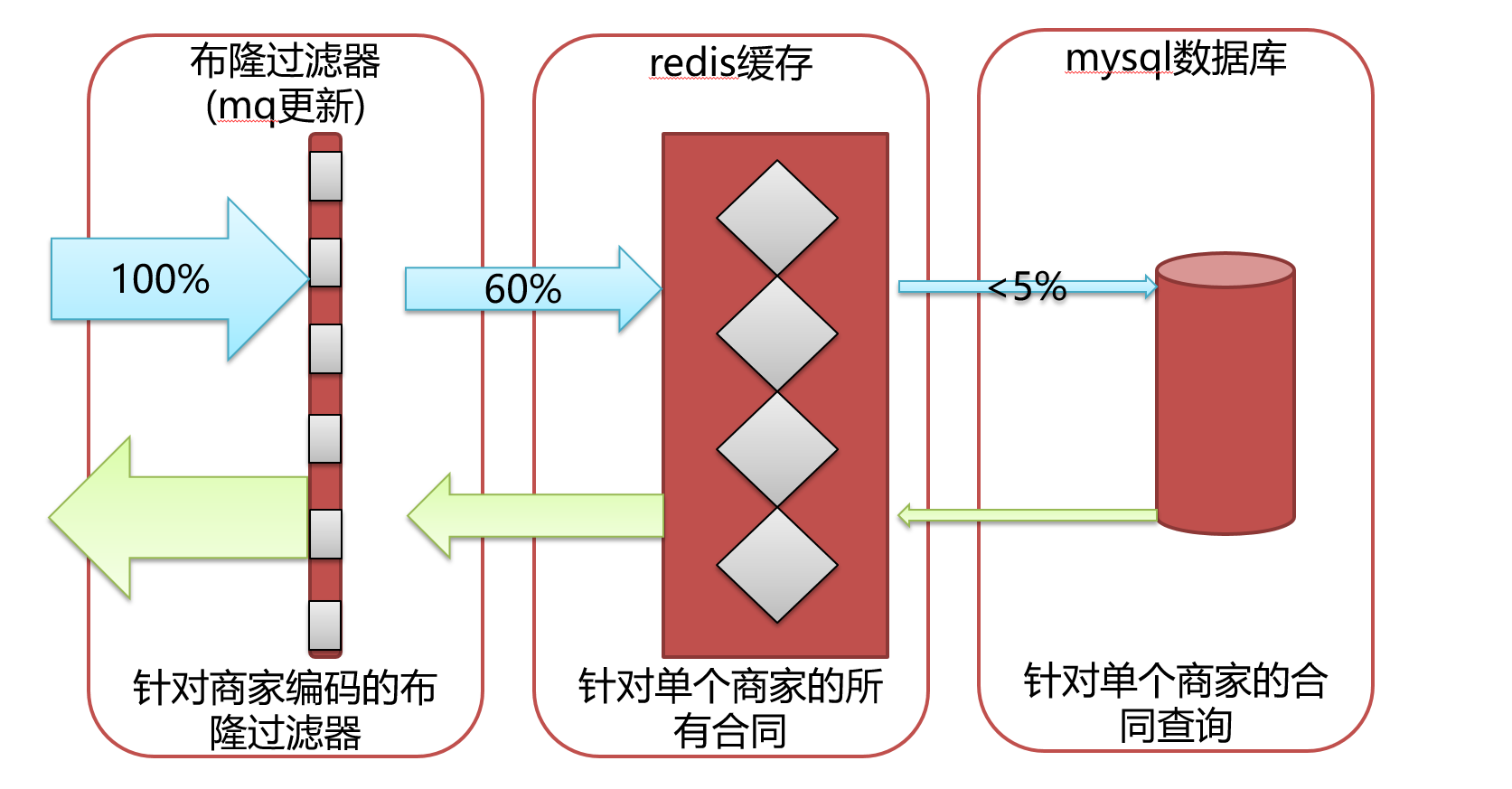
1. The first layer of protection
Since nearly half of the queries are empty, we first of all this is the phenomenon of cache penetration.
Cache penetration problem
Cache penetration means that the data accessed by the user is neither in the cache nor in the database. For the sake of fault tolerance, if the data cannot be queried from the underlying database, it will not be written to the cache. This causes each request to be queried to the underlying database, and the cache loses its meaning. When there is high concurrency or someone uses a non-existent key to attack frequently, the pressure on the database increases suddenly, or even crashes. This is the problem of cache penetration.
conventional solution
Cache specific values
Generally, our more conventional approach to cache penetration is to set a fixed value for a non-existent key, such as NULL, &&, etc. When the query returns this value, our application can consider it to be a non-existent key , then our application can decide whether to continue to wait, continue to visit, or give up directly. If we continue to wait for the visit, set a polling time and request again. If the obtained value is no longer our preset, it means It already has value, thus avoiding transparent transmission to the database, thus blocking a large number of similar requests in the cache.
Cache a specific value and update it synchronously
Certain values are cached, which means more memory storage space is required. When the data in the storage layer changes, the data in the cache layer and the storage layer will be inconsistent. Some people will say that for this problem, it is not enough to add an expiration time to the key. Indeed, this is the simplest and can solve these two problems to a certain extent, but when the concurrency is relatively high (cache concurrency) , In fact, I do not recommend using the strategy of cache expiration, I prefer the cache to always exist; the purpose of updating the data consistency in the cache through the background system.
bloom filter
The core idea of the Bloom filter is that it does not save the actual data, but creates a fixed-length bitmap in the memory and uses 0, 1 to mark whether the corresponding data exists in the system; the process is to pass the data through multiple hashes The Hive function calculates different hash values, then uses the hash value to modulo the length of the bitmap, and finally obtains the subscript of the bitmap, and then marks the corresponding subscript; the same is true when looking for numbers , first obtain the hash value through multiple hash functions, and then perform modulo calculation between the hash value and the length of the bitmap to obtain multiple subscripts. If multiple subscripts are marked as 1, it means that the data exists in the system, but as long as one subscript is 0, it means that the data definitely does not exist in the system.
Here is an example to introduce the scene of Bloom filter:
Take the ID query article as an example. If we want to know whether there is a corresponding article in the database, the easiest way is to save all the IDs in the database to the cache. It is used to judge whether the corresponding data ID exists in the system. If it does not exist, it will be returned directly to avoid the request from entering the database layer. If it exists, the information of the article will be obtained from it. But this is not the best way, because when there are a lot of articles, a large number of document ids need to be stored in the cache and can only continue to grow, so we have to think of a way to save memory resources when it is a request Can hit the cache, this is what the Bloom filter does.
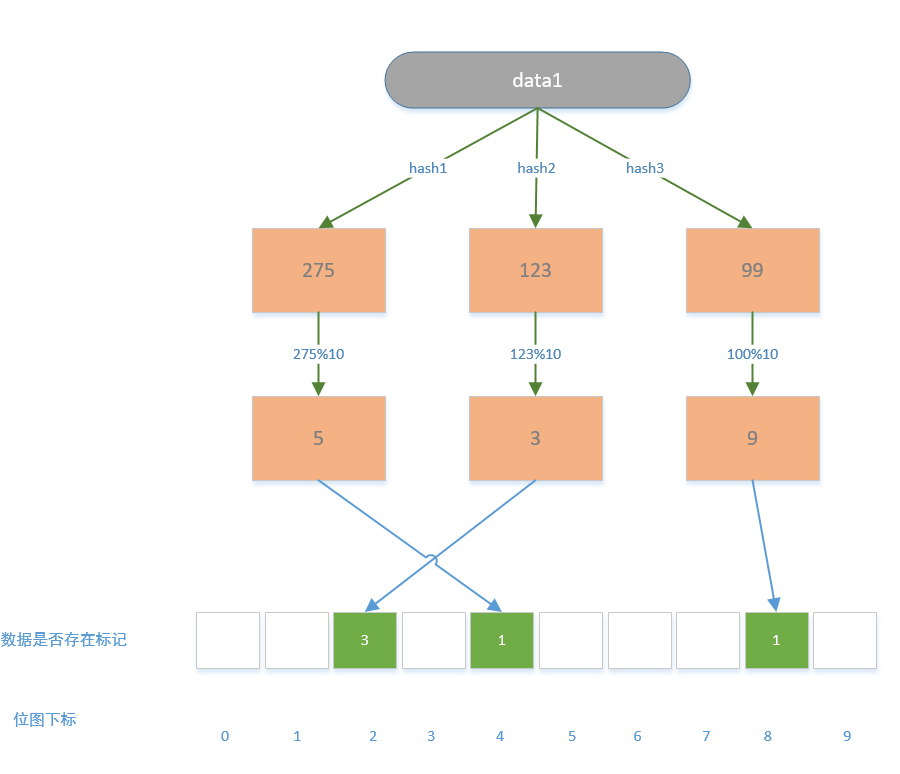
We analyze the pros and cons of Bloom filters
advantage
1. There is no need to store data, it is only represented by bits, so it has a huge advantage in space occupancy 2. The retrieval efficiency is high, and the time complexity of insertion and query is O(K) (K represents the number of hash functions ) 3. The hash functions are independent of each other and can be calculated in parallel at the hardware instruction level, so the efficiency is high.
shortcoming
1. There are uncertain factors, and it is impossible to judge whether an element must exist, so it is not suitable for scenarios that require 100% accuracy. 2. Only elements can be inserted and queried, and elements cannot be deleted.
Bloom filter analysis: Facing the advantages, it fully meets our demands. For the disadvantage 1, there will be very little data penetration and no pressure on the system. For disadvantage 2, the data of the contract cannot be deleted. If the contract expires, we can find out all the contracts of a single merchant, and judge whether the contract is valid from the end time of the contract, without deleting the elements in the Bloom filter.
Considering that calling the redis Bloom filter will take a network trip, and nearly half of our queries are invalid queries, we decided to use a local Bloom filter, which can reduce one network request. But if it is a local Bloom filter, when updating, it needs to update the local Bloom filters of all machines. We monitor the status of the contract to update, and insert elements into the Bloom filter through the broadcast mode of mq, so that This achieves the uniform element insertion of the Bloom filter on all machines.
2. The second layer of protection
In the face of high concurrency, the first thing we think of is caching.
When introducing cache, we need to consider the three major problems of cache penetration, cache breakdown, and cache avalanche.
Among them, cache penetration has been dealt with in the first layer of protection. Here we only solve the problems of cache breakdown and cache avalanche.
Cache breakdown (Cache Breakdown) Cache avalanche refers to the situation where only a large number of hot keys fail at the same time. If a single hot key is constantly carrying large concurrency, at the moment the key becomes invalid, the continuous large concurrent requests will be broken Cache, directly request to the database, like a brute force breakdown. This situation is cache breakdown.
conventional solution
cache invalidation dispersion
This problem is actually easier to solve, that is, add a random value when setting the cache expiration time, for example, add a random value of 1-3 minutes to spread the expiration time and reduce the probability of collective failure; control the expiration time to the lowest in the system The time period of traffic, such as three or four in the morning, avoids the peak period of traffic.
lock
Locking means that when the query request misses the cache, lock it before querying the database operation. After locking, subsequent requests will be blocked, preventing a large number of requests from entering the database to query data.
Never expire
We can not set the expiration time to ensure that the cache will never expire, and then synchronize the latest data to the cache regularly through the background thread
Solution: Use distributed locks, and for the same merchant, only let one thread build the cache, and other threads wait for the completion of the cache build to obtain data from the cache again.
Cache avalanche (Cache Avalanche) When a large number of hot caches in the cache adopt the same effective time, it will cause the cache to become effective at a certain moment at the same time, and all requests are forwarded to the database, resulting in a sudden increase in database pressure and even downtime. As a result, a series of chain reactions are formed, causing system crashes and other situations. This is a cache avalanche.
Solution: The solution to cache avalanche is to set the expiration of the key to a random number within a fixed time range, so that the keys can expire evenly.
We consider using redis cache, because the conditions of each query are different, and the result data returned is relatively small. We consider that the limited query must have a fixed query condition, the merchant code. If the merchant code is not checked in the query conditions, we can reverse check the merchant code through the merchant name, merchant business account and other conditions.
In this way, we can cache all contracts encoded by a single merchant, and then use filters to support other query conditions through the code, avoiding cache data updates caused by different query conditions to cache data, cache data elimination, and cached data consistency. .
At the same time, only all contracts encoded by a single merchant are cached. The amount of cached data is also controllable, and the size of each cache is also controllable. Basically, there will be no problem of large redis keys.
Introducing cache, we have to consider the issue of cache data consistency.
Regarding the issue of cache consistency, you can use Baidu yourself, and this will not be described here.
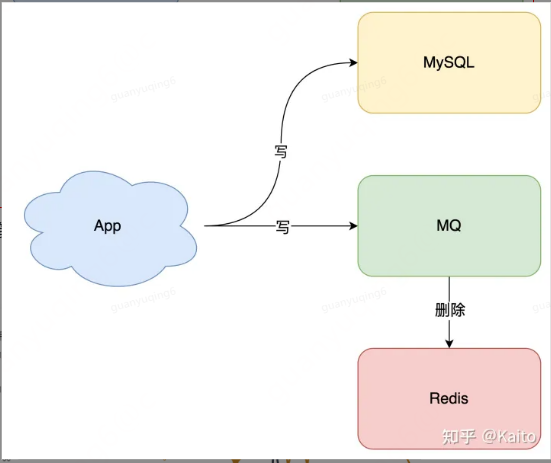
As shown in the figure, for the cache data of the merchant code dimension, we monitor the status of the contract and use mq broadcast to delete the cache of the corresponding merchant, so as to avoid problems related to cache and data consistency.
3. The third layer of protection
The third layer of protection is naturally the database. If a query passes through the first and second layers, then we need to query the database directly to return the results. At the same time, we monitor the threads that directly call the database.
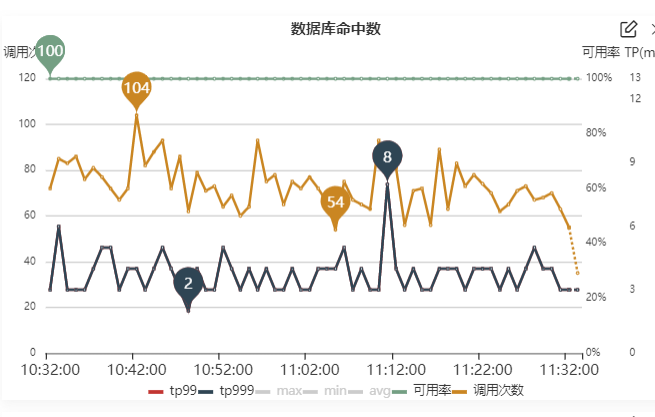
In order to avoid the influx of some unknown queries, which will lead to the problem of database call guarantee, especially during big promotions, we can cache all merchant contracts in the database in advance. When caching, in order to avoid the cache avalanche problem, we set the expiration of the key to a random number within a fixed time range, so that the key will expire evenly.
At the same time, there is an influx of queries in case there are still surprises. We control the query of the database through the ducc switch. If the call volume is too high to support, the database call will be directly closed to ensure that the database will not go down directly and cause the entire business to be unavailable.
4 Summary
This article mainly analyzes the call scenario design and technical solutions for high concurrent calls. While introducing caching, we must also consider the actual call input and participation results. Faced with increased network requests, whether it can be further reduced. In the face of redis cache, can some means be used to avoid all query conditions requiring cache, resulting in cache explosion, cache elimination strategy and other issues, and to solve a series of problems such as cache and data consistency.
This solution is to design specific technical solutions based on specific query business scenarios, and the corresponding technical solutions are different for different business scenarios.
#Consistency #Design #Practice #Random #High #Concurrency #Query #Results #Cloud #Developers #Personal #Space #News Fast Delivery