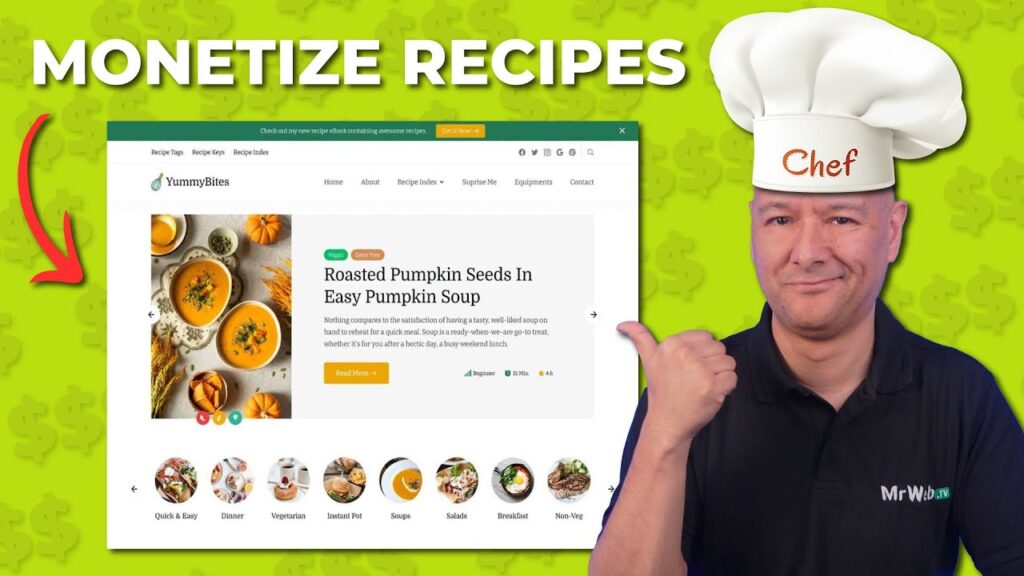
How to Make a Recipe Website with WordPress [BEST Solution]
Today we’ll discover how to make a recipe blog website with WordPress using the WP Delicious plugin, and it’s by far the BEST solution available on the market right now ✅ GET Theme and Plugin ▶ Download Here 👉 ✅ GET HOSTING ▶ Get Hosting Here 👉 This is a co-branded page that I have […]
How to Make a Recipe Website with WordPress [BEST Solution] Read More »